我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續 AI說書 - 從0開始 - 380 | Hugging Face 模型組入,會看到諸多 T5 模型種類,當中差異如下:
- Base 亦即基準模型,它的設計類似於 BERTBASE,有 12 層和大約 2.2 億個參數
- Small 是一個較小的模型,有 6 層和 6,000 萬個參數
- Large 的設計與 BERTLARGE 類似,有 12 層、7.7 億個參數
- 3B 和 11B 使用 24 層編碼器和解碼器,大約有 28 億和 110 億個參數
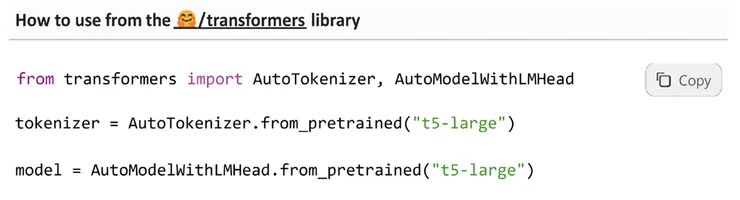
我們將使用 Large 模型,簡介為: