我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
本章節的內容需要從 Hugging Face 中載入 T5 模型,有鑑於此,我們首先登入頁面: https://huggingface.co/models,如下所示:
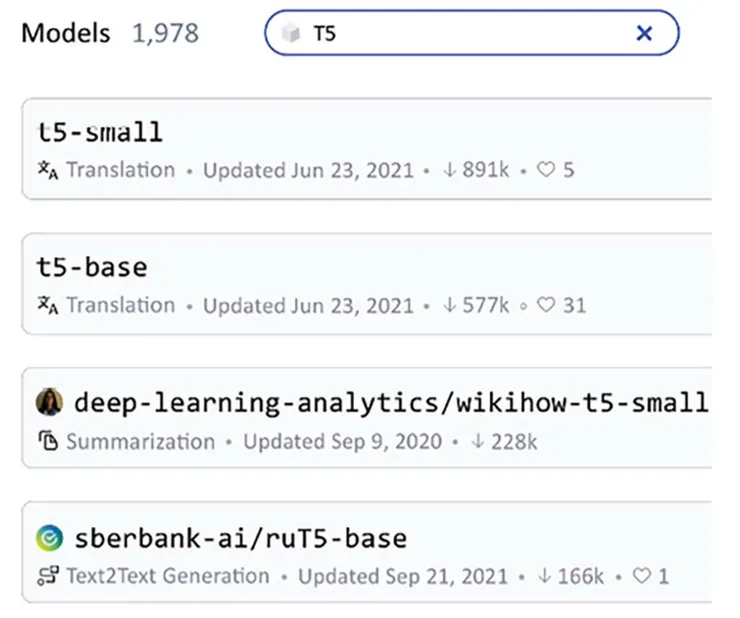
然後輸入 T5,會得到以下列表:
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
本章節的內容需要從 Hugging Face 中載入 T5 模型,有鑑於此,我們首先登入頁面: https://huggingface.co/models,如下所示:
然後輸入 T5,會得到以下列表:





















