上次我們探討了資料集中的狀況,而這一章節我們要來討論數據的分布情況
全距 range
最大值-最小值全距易受極端值影響,因此去頭尾某一比例衍伸出四分位距。
四分位距 interquartile range
IQR=Q3-Q1,可搭配箱型圖

進入下面環節前,我們必須先對 Σ 有更多的認識。了解數據加減乘除時,Σ 還可以如何運算。
X數據帶入常數c做加減乘除
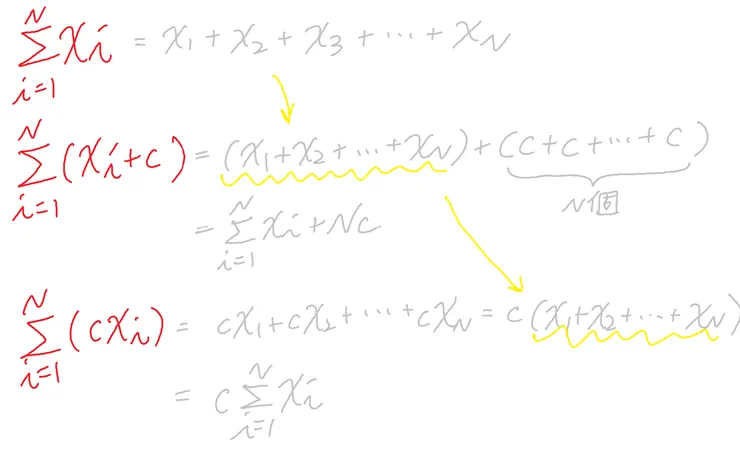
帶入另一數據Y,並帶入常數c做加減乘除
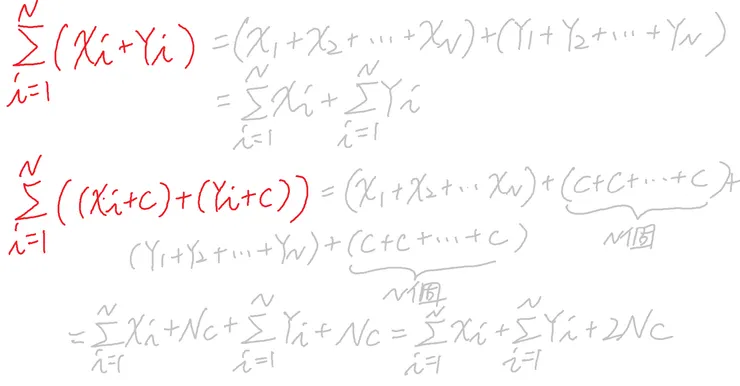
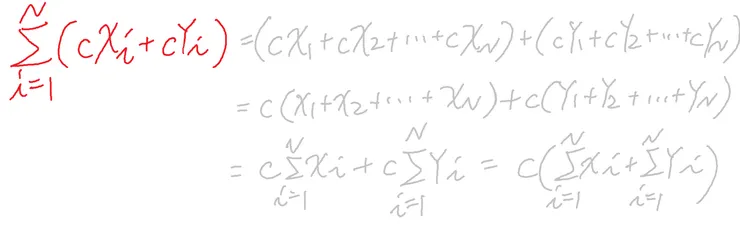
平均離均差 average deviation
開始把「平均數」的概念帶進來,用每筆資料扣掉平均數來看分散程度。但是算出來會相抵變成零,沒有意義。
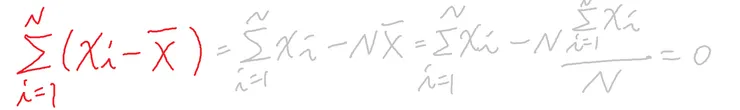
平均絕對離均差 mean absolute deviation
為了改善平均離均差的問題,開始用絕對值來改善。但是計算太麻煩了,因此後人想出使用離均差平方來得到正數。
離均差平方和 Sum of square, SS

若數據加入常數c
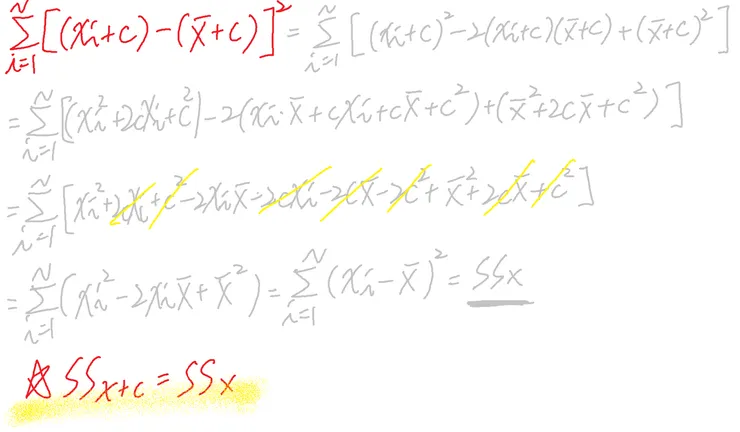
若數據乘除上常數c
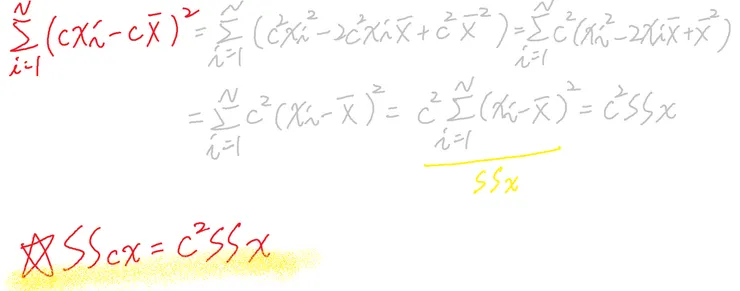
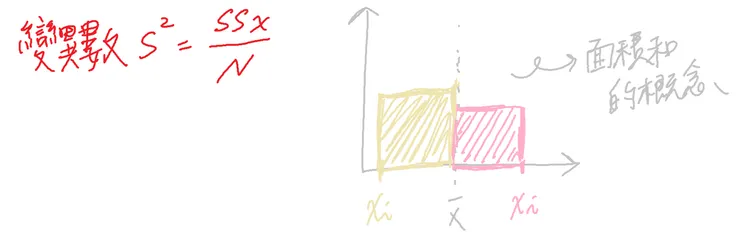
變異數 variance - 可使用於推論統計
若數據加減常數c
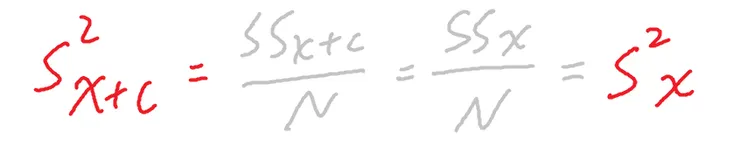
若數據乘除常數c
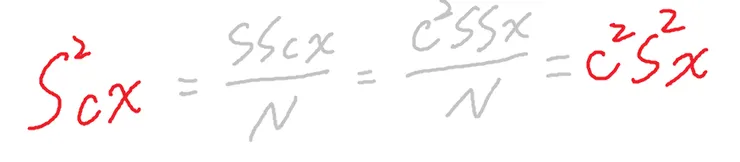
標準差 standard deviation - 可使用於推論統計
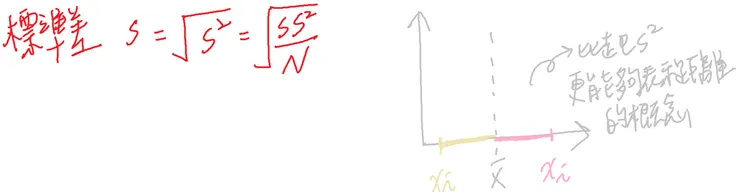
若數據加減常數c

若數據乘除上常數c
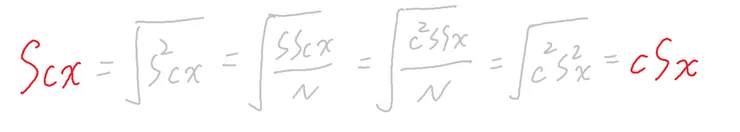
標準差雖然好用,但若不為同一資料則無法比較。因此,衍伸出變異係數。
相對變異係數 coefficient of variation
若平均數大,離均差也會比較大,因此除上自己的平均數再做比較。雖方便可以比較跨資料的分布情形,但無法使用在推論統計。有負值、上下限的量表不太適用,因此大多用在比率變項。
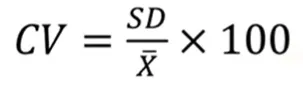
看完分散量數後,相信對於資料的分布狀態有一定程度的了解了!但是,人終究還是關心自己嗎!所以,我們會想要知道自己的表現在班上排名多少。因此,出現了相對地位指標,讓大家能夠知道自己的分布位置喔!下章見!























