前面說明了所謂「假設檢定」的邏輯,也就是推論統計的基礎。但前面都還只是概念的階段,目前沒有真正進行任何的操作──還沒有提到推論統計的技術。
這篇其實有點像是一個過渡,是將前面的概念銜接到下一篇t檢定之間的過程,也可以說是稍微解釋一下t檢定怎麼發展出來的。稍微複習一下我們在哪裡
從推論統計是什麼這個問題開始,首先提到了抽樣,並從抽樣解釋了大名鼎鼎的中央極限定理 ,緊接著介紹了常態分布與機率的關係,最後則是這個關係怎麼幫助我們做出統計檢定(統計推論)。
常常聽到有人說莫忘初衷,初衷想必是很重要的。那麼現在也可以回顧一下推論統計的初衷,以及聰明的統計學家們到底是想出了怎樣的方法來解決各種問題。如果把推論統計的整個思考邏輯拆解成不同步驟,大概會是類似下面這樣的狀況:
- 推論統計的目的是什麼?因為不知道母體的狀況,但想至少知道母體平均是多少。(統計急救箱─什麼是推論統計?)
- 怎麼知道母體平均是多少?就要靠抽樣分布,那是一個以母體平均數為中心的常態分布曲線。(統計急救箱─抽樣分布與中央極限定理(一)、統計急救箱─抽樣分布與中央極限定理(二))
- 推論母體平均數的原理是什麼?先假設母體的平均數是某個數值,然後再看看「如果假設是對的,得到現在這筆資料的機率有多高?」如果機率很低,就會認為假設可能有誤。透過這種否定母體平均數為某個值的方式,來猜測母體平均數在哪。(統計急救箱─常態分布與假設檢定(上)、統計急救箱─常態分布與假設檢定(下))
- 那要怎麼知道發生機率有多大?在知道抽樣分布的平均數和標準差之後,我們就可以算出來。(統計急救箱─常態分布與機率)
- 抽樣分布的平均數可以由我們自己假設(也就是假設母體平均數),但標準差呢?
沒錯,如果不解決這個標準差的計算問題,之後也沒有所謂的假設檢定可以做了。
之所以要列出來目前提到的這些東西,是因為這裡要講的東西會稍微綜合一些,要回到抽樣分布(也就是中央極限定理下得到的常態分布)開始說起。所以如果不知道抽樣分布是怎麼長出來的,可以回頭去複習一下。
如果分不清楚樣本分布、抽樣分布以及母體分布這三個名詞指的是什麼,也需要回頭複習一下中央極限定理的部分喔。
常態分布的機率計算:兩個參數
在 統計急救箱─常態分佈與機率 裡面有介紹過常態分布的特性,在第三個特性中我們提到理論上只要知道母體平均數與標準差,就能計算出常態分布上任何一點的發生機率。
上面這是白話的說法──也就是說,常態分布的圖形會長成怎樣(或者說如果我們想知道常態分布上某個點的發生機率有多高),需要看「平均數」與「標準差」兩個數值來決定。如果改用數學語言來說,這就是常態分布的兩個參數。有興趣的人可以參考下面的圖片說明。
這也是為什麼要計算抽樣分布上的機率必須要先獲得兩個資訊:
- 抽樣分布的平均數,同時等於母體的平均數(決定抽樣分布的位置)
- 抽樣分布的標準差(決定抽樣分布的寬度)
抽樣分布的標準差是多少?
其實在之前的文章裡面,就已經偷偷寫出抽樣分布的標準差怎麼計算了,不過在那篇文章中並沒有多做解釋。那張圖在這裡:
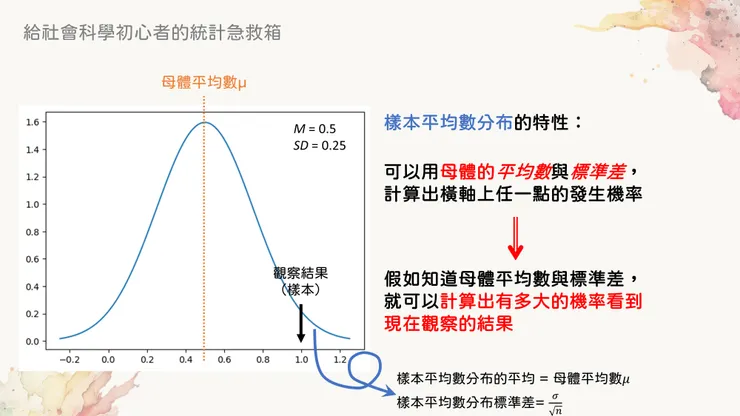
這張圖最下面的兩行字,已經寫出抽樣分布的平均和標準差了
在之前抽球的例子裡面已經實際演示過抽樣分布的平均數等於母體平均數這件事了,但標準差這東西很難具體的用類似方法展示出來...只能說靠著統計學家們聰明的腦袋和厲害的數學計算能力,得出抽樣分布的公式如下(這是數學上可以證明出來的,但我們只需要知道結果就好):

抽樣分布的標準差公式
分子的sigma表示母體標準差,分母的N表示抽樣的樣本數(請記得抽樣分布是指每次抽出N個樣本並計算平均數。重複這個行為無數次之後得到的平均數分布)。
換句話說,當我們知道母體的標準差是多少,再加上自己假設一個母體平均數的數值,我們就可以知道抽樣分布會長怎樣,接著就可以計算這個分布上所有的機率,藉此推斷母體平均數是不是如同我們所假設的了,可喜可賀!
結案,大家可以散會了。
如果沒有真的乖乖聽上面那句話收拾東西走人,馬上就會發現一個奇妙的問題...不是,誰會知道母體標準差是多少啊?別忘了計算標準差可是需要先知道平均數,當我們知道母體標準差之後不就表示知道母體平均數了嗎?那誰還要管抽樣分布是什麼東西啊。
母體標準差未知怎麼辦?從標準差到標準誤
好吧,事情果然不是這麼簡單的。
我們想知道抽樣分布的標準差就是為了想要估計母體的平均值,結果竟然需要知道母體的標準差,這下可怎麼辦?
在每次抽樣裡面,我們都能得到樣本的平均數和標準差。既然不知道母體標準差,要不乾脆拿樣本標準差來代替好了 [*1]。於是這公式就會被改成下面這樣:

這叫做標準「誤」(SE)
其實這後面還是牽扯到很多數學推導,如果上面那段文字聽起來彷彿統計學家們很隨便,那是因為我寫成這樣的關係 [*2]。
剛剛說分子如果是母體標準差 (sigma) 的話,公式的名字叫做「抽樣分布的標準差」。現在這公式都改了,名字我們也要改一下才行。當我們在分子的部分用單次抽樣的樣本標準差 (Sx) 代替母體標準差 (sigma),這個公式的名稱就叫做標準誤差 (standard error,簡稱SE),它的功能是拿來代替抽樣分布的標準差,好讓我們能夠對母體平均數做出統計檢定。
或者也可以這樣理解:標準誤 (SE) 是對抽樣分布標準差的估計值。這也是為什麼它可以代替抽樣分布標準差的理由 [*3]。所以未來看到標準誤的時候請記得這是一種估計值喔~
到此為止,從抽樣分布到統計檢定的最後一塊拼圖終於湊齊了。從下一篇開始就要真正介紹「實務上執行統計檢定的技術以及做法」了。
後續的文章感覺會越來越不好寫...應該還是會以面向初學者實務導向為方向,很多細節跟深度就會默默的消失。其實這系列文章最開始的想法,也是讓沒學過統計的人之後自己去查資料可以比較好懂一些。
備註:
[*1] :這裡要注意一件事,就是在先前講描述統計時,提到樣本變異數的計算公式,分母是除以N的。但事實上當我們要把樣本標準差拿來計算標準誤的時候,樣本標準差的公式會長成這樣:

標準差的不偏估計式
這個東西叫做樣本標準差的不偏估計式。不過現在用統計軟體的時候預設的樣本標準差大概都是這樣算的了,而且在樣本數量沒有太小的時候分母是N或N-1往往差異不是太大,所以大概知道一下就好。
[*2]:事實上t分數並不是單純把母體標準差抽換成樣本標準差那麼單純,而是透過某些技術將母體標準差給消除掉,進而避開了母體標準差未知而無法推論的問題。想了解更多的話可以參考Kirk (2014) 的著作Experimental design: Procedures for the behavioral science第四版當中的第三章,有比較詳細的說明。
[*3]:這裡講的比較簡單一些,實際上樣本標準差能不能直接拿來取代母體標準差,跟抽樣大小有關係。當樣本數太小(例如只有個位數個)或者很大(例如超過母體的5%)時,這個標準誤是需要另外進行校正處理的。