PROCESS macro for SPSS 可以用非常簡單方式進中介模式。本文將介紹四種類型的變項,並解釋調節式中介的公式,還有如何操作最4.0版本的PROCESS macro for SPSS。文末也會附上所有所有Process模型圖例,提供給讀者方便分析~
程度不夠的讀者,推薦先閱讀下面的文章:
使用PROCESS macro for SPSS 進行中介模式分析
使用PROCESS macro for SPSS 進行調節模式分析
本文將先簡單介紹四種類型的變項
之後範例中,X代表自變項,Y代表依變項,M代表中介變項,W代表調節變項,Z代表另一個調節變項
自變量(Independent Variable)是指在研究中可以被操縱和改變的變量,並用於預測或解釋另一個變量(依變量)的值。可以通過統計分析和實驗設計等方法來評估自變量對依變量的影響。
依變量(Dependent Variable)是指在研究中需要被解釋或被預測的變量,並受到自變量的影響。依變量通常是研究中的主要關注點,可以是各種各樣的,如心理健康、學習成績、消費行為等。
中介變量(Mediating Variable)是指影響自變量與依變量之間關係的變項。自變項主要透過中介變項來影響依變項。也就是說中介變項是自變項和依變項之間的橋樑。舉例來說,學習方式對學習成績的影響,其中學習方式是自變量(X),學習成績是依變量(Y),而學習時間是中介變量(M),學習方式主要透過學習時間影響成績,如果今天學生都不花時間學習,那擁有很好的學習方式也對成績沒有幫助。
調節變量(Moderating Variable)指的是一種影響自變量對依變項的關聯強度的變項。舉例來說,性別(W)可能是運動時間(X)和肌肉量(Y)的調節變項,因為女生比較不容易長肌肉,所以運動時間和肌肉量的關聯不明顯,但如果是男生的話,運動時間和肌肉量的關聯就很明顯。
調節式中介公式解釋
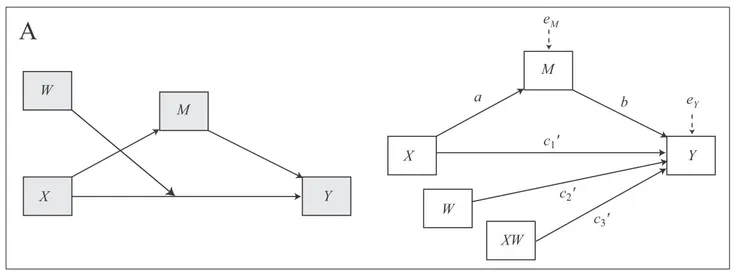
示例 A :X對Y直接影響受到W調節
如下圖所示 在該模型中,存在 X 通過 M 對 Y 的單一間接影響,以及作為第四個變量 W ,其調節X對Y的直接影響。統計圖表示兩個方程式,一個用於依變項 M,一個用於依變項 Y,如下:
M = iM + aX + eM
Y = iY + c′1X + c′2W + c′3XW + bM + eY
在依變項 Y的方程式中,把X移位,可以改寫成
Y = iY + (c′1+ c′3W)X + c′2W + bM + eY其中 X 對 Y 的直接影響受到W調節,所以X對Y的係數為c′1(主要效果)+ c′3W(交互作用)。Simple slopes analysis時, PROCESS 會把W帶進代表高/中/低程度的數值,看X 對 Y係數的變化。