在ChatGPT問世以來,大家已經感受到了生成式AI入侵各行各業的威力,但真正能夠從這個趨勢賺錢的企業,是位於價值鏈的哪個位置?一些號稱能抓到生成式AI機會的公司,會不會只是泡沫的hype實際上不可取代的程度低,做不出市場所需的差異化產品。
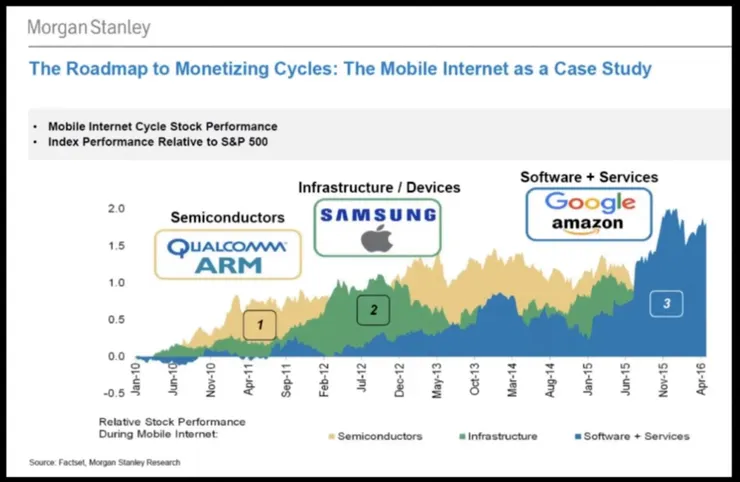
如果觀察上一代大型的科技循環,Mobile移動網路的趨勢,會有不同的公司在不同時期表現強勢。上一代吃到移動紅利的先行者,是需要先將聯網mobile裝置做出的半導體的高通和ARM,所有的公司都搶著要開發移動裝置,他們是淘金潮的鏟子必要的部件。
接著是裝置和基礎設施平台像是三星,蘋果,憑藉著強悍的設計、製造和成本控制能力,成為了最重要且利潤獲得最多的裝置平台巨頭。最後是像Google、Amazon這樣基於Mobile裝置等軟體應用App與服務,因為普及化的移動裝置使他們的軟體營用和服務市場大幅擴大,進而獲取移動端的廣告或電商紅利。
這次新一波的生成式AI科技浪潮,可能也會有類似的路徑。
硬體先行,AI淘金潮的鏟子
生成式AI需要GPU或TPU來處理、訓練、推理大量的數據,這些硬體的設計與製造相對集中於少數的廠商像是Nvidia、Google還有TSMC,是進入門檻高的行業有比較深的護城河。
AI伺服器和GPU晶片需求會有顯著的上升,TrendForce預測2023年搭配GPU、FPGA和ASIC的AI伺服器年增會在38.4%,將佔伺服器整體出貨量的9%,預計在2026年會佔15%。2023 AI chip的出貨量則預計會年增46%,配備 Nvidia的A100與H100 AI伺服器出貨量年增率預期會高達50%,除了Nvidia,提供AI伺服器解決方案的美超微電腦Supermicro(SMCI)就是主要受惠者之一。
部署在高階GPU(如Nvidia H100, AMD 的MI300和Google的TPU)的HBM(High Band Memory)需求,預計因為新的HBM3技術增強AI伺服器運算性能而會在2023大增58%,2024也會繼續年增30%。做記憶體介面技術研發設計和授權的 Rambus (RMBS) 和滿足AI SoC 設計需求的EDA公司包含Synopsys (SNPS)、Cadence(CDNS)也都是受惠的公司。
這些硬體需求會在AI需求成長爆發之際保持不墜,即便景氣變得更糟糕,預算也會花在更新AI硬體排擠其他的硬體投資。等到競爭格局穩定時成長才會顯著慢下來。但同時要注意佔比的問題,許多AI題材若營收占比低,事實上是對獲利成長貢獻有限。
雲端平台
由於GPU與TPU的高昂算力成本和需求,使大部分企業要自行構建硬體平台的成本效益不高,大部分的公司要訓練、調整大型的AI模型會使用雲端運算平台包含第一線的Azure、GCP和AWS,以及比較小的像是Oracle和IBM也有提供雲端AI訓練的服務。更小規模的雲端運算平台廠商,則需要大型企業為了降低大型平台的依賴給予支持才可能會得到更多市占率。但大型平台因為其成本結構和規模會更有優勢。
不過和硬體Nvidia獨大的情形不同,雲端平台的競爭格局三足鼎立,Azure、GCP、AWS即便都會受惠於AI訓練和推理的需求上升,但競爭可能會讓彼此的價格沒辦法大幅增加,尤其規模龐大的AWS和Azure仍要觀察其AI需求對他的營收能有多少比例的boost,同時在基礎建設支出大增的情形下,營業利潤率的變化。
AI 基礎 Model
生成式AI的爆發點是從OpenAI調教出的大型語言模型GPT-3.5開始廣為世人所知,這些經過預訓練深度學習基礎模型開發出來後,可以創建特定類型的內容,然後能基於這些模型創建不同的應用,像是ChatGPT就是大家最熟悉的基於GPT--3.5和GPT-4模型的聊天機器人。
要訓練這些模型需要有海量資料的數據庫,包含公開的Wikipedia和像是Reddit、Twitter這類社交媒體,或是像是Shutterstock這類的圖像資料庫用來訓練模型。
開發和訓練、調教基礎模型的成本昂貴,OpenAI的GPT-3就估計就要花費400萬到1200萬美金,往上的數據量是指數型的成長。但訓練所需的數據不見得是會越來越大,針對特定任務製作更小的模型訓練,這會是更多公司的機會。一些有巨頭支持的新創公司包含Anthropic、Cohere、Stability AI也有自己訓練的模型,由於數據安全的因素大部分公司都希望這些LLM大規模語言模型在自己的環境中工作。


























