I. 前言
支持向量機 (Support Vector Machine, 簡稱SVM),是一種將資料分群的機器學習方法。
屬於監督式學習 (supervised learning),因為:
- 給定已標記的數據 (labeled data),SVM可以透過訓練得到分類器模型 (classifier model)。
- 對於未標記的數據 (unlabeled data),可以利用訓練好的SVM模型來預測未知數據的類別。
II. 原理
在二維平面上,有紅色與藍色兩種顏色的球 (可視為已標記的數據)。

二維平面SVM分類原理
圖上有三條線 (H1、H2、H3),若想用其中一條線將紅藍球分開,
哪一條是最佳的呢? 一起來看看!
- H1: 無法分開紅、藍球,不考慮。
- H2: 雖可以將紅、藍球分開,但有沒有更好的選擇?
- H3: 可以準確地將紅、藍球分開,且向量到距離最近的紅、藍球已最大化,此二向量也作為支持向量 (support vector),其之間的空隙稱為margin,最大化空隙 (maximised margin)視為最佳解。
由上述例子可知,若想找到最佳的分割線 (二維空間)或分割平面 (三維空間),需要將支持向量之間的margin最大化 (SVM最主要的核心概念)。
III. SVM學習動畫
展示在多維空間找到分割平面的過程。
IV. 範例 (鳶尾花分類)
- 載入iris資料集
- 70%、30%切分訓練集 (train set)與測試集 (test set)
- 以訓練集的特徵 (花萼、花瓣長度與寬度)、類別 (花的種類)訓練SVM模型
(因為是分類問題,這裡用是使用Support Vector Classifier, SVC) - 訓練完成後,用測試集的特徵預測花的種類
- 評估正確率
- 視覺化:
- 用花萼長度與寬度作圖呈現訓練集與測試集的種類分布
- 測試集種類分布圖上標記黃色星為預測錯誤的點
(亦可用其他特徵作圖,有多種呈現方式)
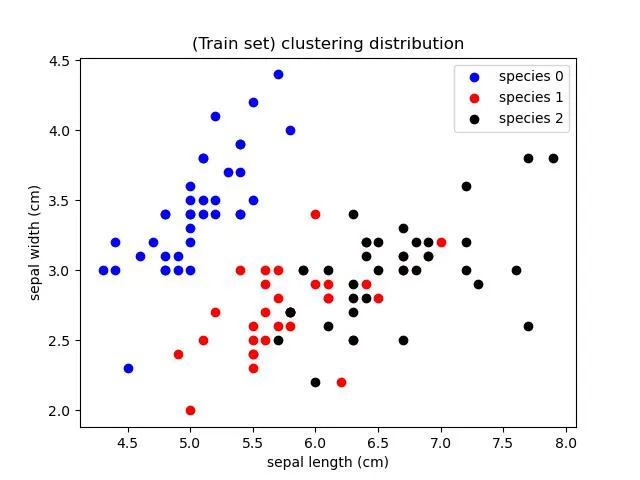
訓練集種類分布
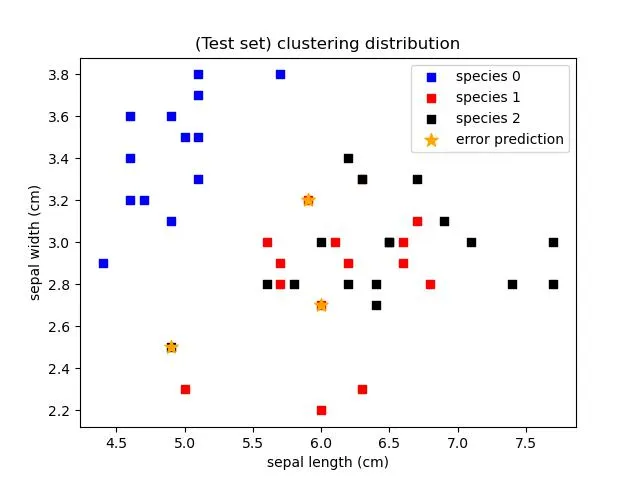
測試集種類分布
V. 程式碼 (python)
import pandas as pd
import matplotlib.pyplot as plt
import os
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
#%% 取得當前程式放置目錄
current_path = os.getcwd()
#%% 載入iris資料集
iris = datasets.load_iris()
#%% 抓出資料特徵與種類標記
features = pd.DataFrame(iris.data, columns = iris.feature_names)
species = pd.DataFrame(iris.target, columns = ['species'])
#%% 以70%/30%拆分訓練集與測試集
x_train, x_test, y_train, y_test = train_test_split(features, species, test_size = 0.3)
train_set = pd.concat([x_train, y_train], axis = 1).reset_index(drop = True)
test_set = pd.concat([x_test, y_test], axis = 1).reset_index(drop = True)
#%% SVM訓練
svc = SVC()
svc.fit(train_set[iris.feature_names], train_set['species'])
y_pred = svc.predict(test_set[iris.feature_names])
test_set['species_pred'] = y_pred
# SVM分類準確率
SVM_accuracy = round(accuracy_score(test_set['species_pred'], test_set['species']), 4)
print(f'SVM accuracy: {round(SVM_accuracy * 100, 2)}%')
#%% 以花萼長度(sepal length)與花萼寬度(sepal width)作圖
### 畫出訓練集的群集分布
plt.figure()
for i in range(3):
if i == 0: c = 'blue'
if i == 1: c = 'red'
if i == 2: c = 'black'
item = train_set[train_set['species'] == i]
plt.scatter(item[iris.feature_names[0]], item[iris.feature_names[1]], color = c, label = f'species {i}')
plt.legend()
plt.xlabel(f'{iris.feature_names[0]}')
plt.ylabel(f'{iris.feature_names[1]}')
plt.title('(Train set) clustering distribution')
plt.savefig(current_path + '\\train set_clustering distribution.jpeg')
### 畫出測試集的群集分布,以及標記SVM預測錯誤的點
plt.figure()
for i in range(3):
if i == 0: c = 'blue'
if i == 1: c = 'red'
if i == 2: c = 'black'
item = test_set[test_set['species'] == i]
plt.scatter(item[iris.feature_names[0]], item[iris.feature_names[1]], color = c, marker = 's', label = f'species {i}')
item_pred_error = test_set[test_set['species_pred'] != test_set['species']]
if len(item_pred_error) != 0:
plt.scatter(item_pred_error[iris.feature_names[0]], item_pred_error[iris.feature_names[1]], color = 'orange', marker = '*', s = 100, label = 'error prediction')
plt.legend()
plt.xlabel(f'{iris.feature_names[0]}')
plt.ylabel(f'{iris.feature_names[1]}')
plt.title('(Test set) clustering distribution')
plt.savefig(current_path + '\\test set_clustering distribution.jpeg')





















