大家在跟Chat GPT互動的時候,會不會覺得常常雞同鴨講
我們梳理了一些提升Chat GPT回答能力的作法 ChatGPT回答不是你要的怎麼辦?我們也實作了當中的一種方法,叫做RAG於 自己做免錢Chat GPT吧
這篇文章,我們談談其他技巧,稱為「透過LoRA執行Fine Tuning」
- LoRA簡介
Microsoft 團隊提出的Low Rank Adaption (LoRA)是一種有效的參數Fine Tuning技術,可幫助改善大型語言模型 (LLM)在特定任務上的效能表現,並且具有較低的運算和儲存成本。 它旨在透過降低模型參數的秩(Rank)來減少模型的複雜度,從而提高模型的一般化能力和適應性。
- LoRA圖示說明
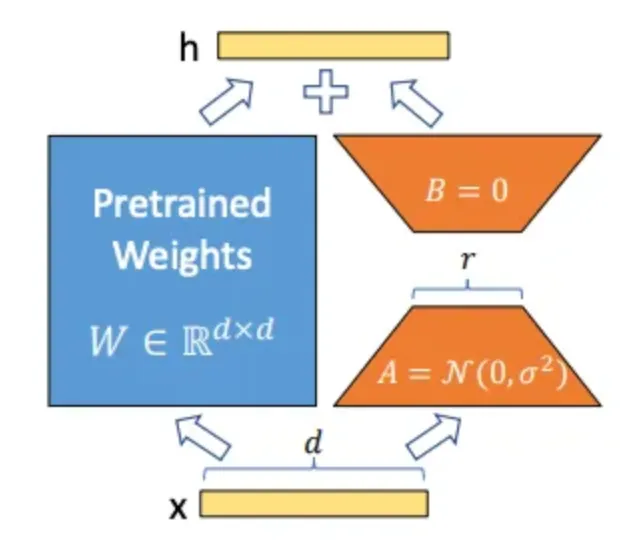
- 既然 LLM 適用於不同任務,那代表模型對於不同任務會有不同的神經元/特徵來處理這件事,如果我們能從眾多特徵中找到適合那個下游任務的特徵,並對他們的特徵進行強化,那我們就能對特定任務有著更好的成果。
- 因此搭配另一組可訓練的參數 Trainable Weight進行組合,藉此最佳化下游任務的成果。
- 右邊橘色模組為我們要訓練的模型權重 LoRA ,透過中間 Rank — r 的限縮,可以大幅地降低訓練的參數量。
- LoRA與LLM中的Transformer關係圖
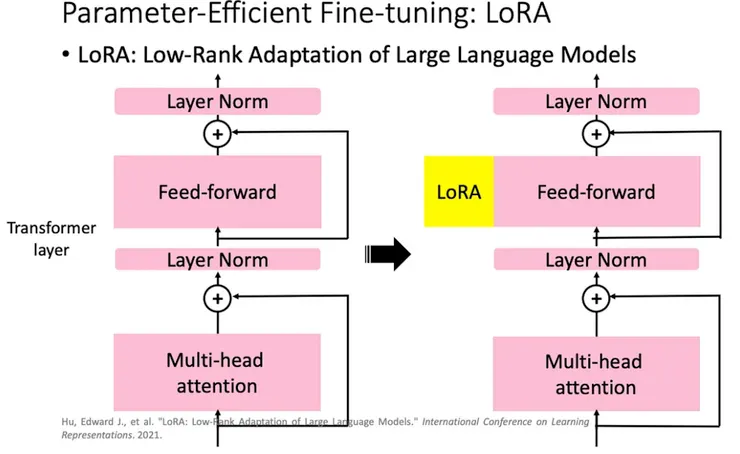
透過凍結原本的預訓練模型的權重,搭配一個小的模型進行微調就可以達到很好的 Fine-Tuning 效果。透過微調新增的小型網路,當作補丁或是插件。整體想法如上圖:在特定層之中插入小型的 LoRA 網路,來讓模型可適用不同的任務。
- 補充說明
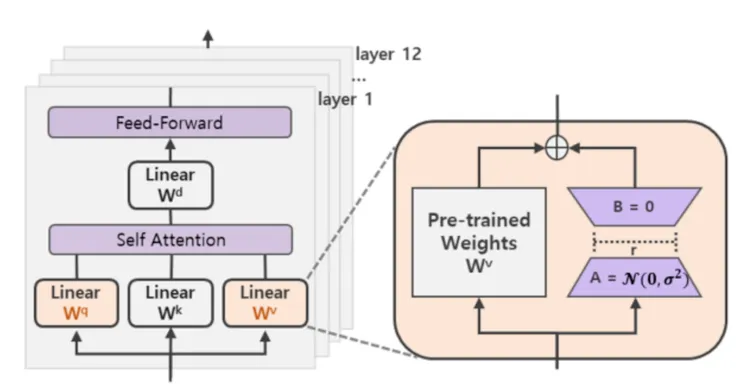
- 矩陣A的權重參數會透過高斯函數初始化,而矩陣B的權重參數會初始化為零矩陣,這樣能保證訓練開始時新增的旁枝BA = 0,從而對模型結果沒有影響。
- Transformer模組中的Attention部分包含Query、Key、Value矩陣,也包含Multiple Attention的矩陣,乃至於Multiple Layer Perceptron的矩陣,LoRA只應用於Attention模組中的四個矩陣,透過實驗發現,LoRA應用於Query和Value矩陣效果最佳。






















