目前我們已經完成:
- Single-Head Attention 數學說明:AI說書 - 從0開始 - 52
- Multi-Head Attention 數學說明:AI說書 - 從0開始 - 53
- Attention 機制程式說明 - 輸入端:AI說書 - 從0開始 - 53
- Attention 機制程式說明 - Query 端:AI說書 - 從0開始 - 54
- Attention 機制程式說明 - Key 端:AI說書 - 從0開始 - 54
- Attention 機制程式說明 - Value 端:AI說書 - 從0開始 - 55
- Attention 機制程式說明 - Query 、 Key 、 Value 結果:AI說書 - 從0開始 - 56
- Attention 機制程式說明 - Attention Score 計算:AI說書 - 從0開始 - 57
- Attention 機制程式說明 - Attention Score 正規化計算:AI說書 - 從0開始 - 58
- Attention 機制程式說明 - 輸出結果計算:AI說書 - 從0開始 - 59
- Attention 機制程式說明 - 輸出結果呈現:AI說書 - 從0開始 - 60
我們有始有終,做個整理:
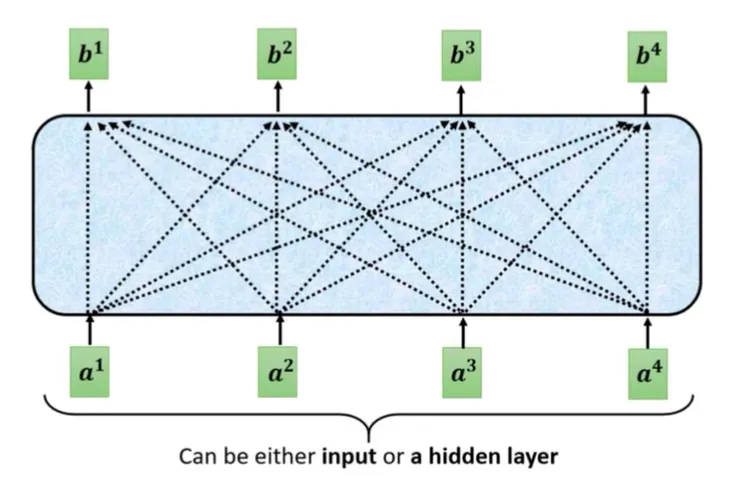
- 回顧 AI說書 - 從0開始 - 52
- Attention 機制就是給定一排字,每個字有其對應向量 a1、a2、a3、a4,然後輸出向量 b1、b2、b3、b4
然後我現在經歷 AI說書 - 從0開始 - 52 至 AI說書 - 從0開始 - 60 的奮鬥得到:

- 回顧 AI說書 - 從0開始 - 53 說現在設定一個句子有三個字
- 兩相對照知 b1 = [1.9366 6.6831 1.5951] 、b2 = [2.000 7.9640 0.0540] 、 b3 = [1.9997 7.7599 0.3584]


















