我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
我們在 AI說書 - 從0開始 - 271 | 其他解釋 Transformer 模型之方法簡介 中,提到 LIT 視覺化,今天我們來操作一次,首先造訪:https://pair-code.github.io/lit/,我們將使用 Sentiment Analysis Classifier,更多的探索可以參見以下網站:https://pair-code.github.io/lit/tutorials/sentiment/
延續 AI說書 - 從0開始 - 272 | Transformer 模型之 LIT 視覺化,接續步驟如下:
- 在「Data Table」處點選資料
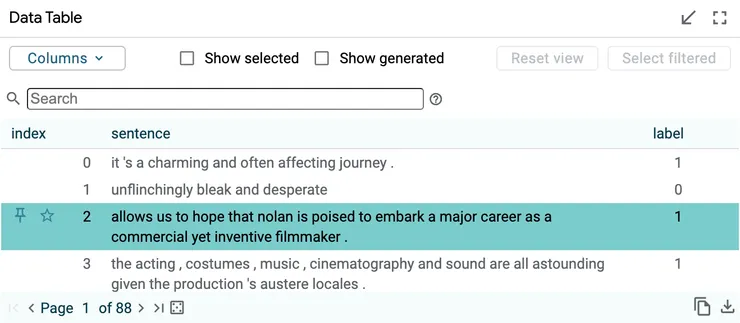
- 在「Datapoint Editor」也會出現稍早選擇的資料
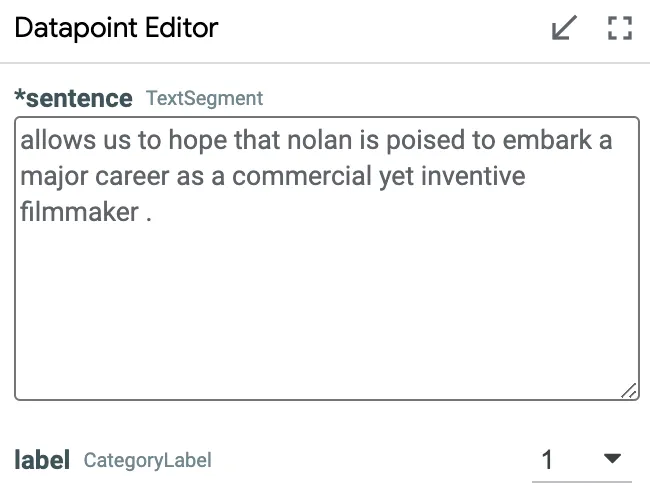
Datapoint Editor 的功能為:Datapoint Editor 允許你更改句子的上下文,例如,你可能想了解某個反事實分類出了問題,本應屬於某一類別但最終被歸入了另一類別,你可以更改句子的上下文,直到它出現在正確的類別中,以理解模型的運作方式以及為何會出錯

















