知己知彼,百戰百勝,一起看看有什麼新發表!
介紹本週海選的三篇 AI paper,包括量化 AI 在「工程層級的研究重現能力」、AI 人機協作及專供企業內部部署的企業級大型語言模型,適用於多語言環境。。
PaperBench—AI 能從零重現最前沿機器學習研究嗎?
OpenAI 團隊聯手推出 PaperBench,首個系統性評估 AI 是否具備「從頭重現頂尖 AI 論文」能力的基準測試。

一、PaperBench 是什麼?
一套全新的 benchmark,針對 AI 能否從零開始重現完整的機器學習研究流程進行評估。任務涵蓋三大面向:
• 理解論文貢獻
• 開發程式碼(無參考實作)
• 執行實驗並重現結果
二、評估對象與範圍
• 精選自 ICML 2024 的 20 篇 Spotlight 與 Oral 論文
• 涵蓋 12 個子領域(如深度強化學習、魯棒性、機率方法等)
• 每篇論文拆解為可單獨評分的子任務,總數高達 8,316 個
• 所有評分標準(Rubrics)皆與原作者共同設計,確保真實性與準確性
三、採用大型語言模型進行自動評分-自動化評分與 JudgeEval
為加速評分流程,研究團隊開發了基於 LLM 的自動評審系統:
• 最佳模型為 o3-mini-high + custom scaffolding
• 在評審準確度測試 JudgeEval 上達成 F1 分數 0.83
• JudgeEval:一個由人類專家標記的資料集,用於評估與訓練自動評審模型
四、前沿模型表現仍有限 - AI 模型表現與人類比較
• Claude 3.5 Sonnet(新版):得分最高,僅 21.0%
• o1 模型:完整 PaperBench 中得分約 26.6%(在三篇子集上)
• GPT-4o:得分為 4.1%(需標註來源版本)
• 相較之下,ML PhDs(博士級專家) 在同樣任務中 48 小時內達到 41.4%,人類依然領先
五、Code-Dev 輕量版本
• PaperBench Code-Dev:不執行實驗,只評分代碼邏輯與結構
• o1 模型於此版本得分提升至 43.4%
• 顯示當去除實驗執行障礙後,模型的工程能力更能發揮
六、模型常見問題與行為觀察 - 失敗模式與啟示
• 多數模型出現:
• 中途放棄
• 缺乏長程規劃能力
• 無法策略性迭代
• Claude 表現較佳時使用較自由的 BasicAgent 架構
• o1 在 IterativeAgent(結構化提示)下有明顯改善
• 顯示:提示語設計與 scaffold 結構會顯著影響代理人表現
七、關鍵貢獻總結
• PaperBench:首個結合論文、原作者 rubrics、AI 重現與自動評分的重磅 benchmark
• JudgeEval:為自動評審建立可評估準確性的金標資料集
• Code-Dev 版本:讓資源受限的研究者也能進行部分評估與比較
• 實驗結論:現階段 AI 還無法獨立完成長期、高難度的 ML 研究任務,但 scaffold 與提示設計已成為關鍵突破點
一句話總結:
PaperBench 讓我們首次能量化 AI 在「工程層級的研究重現能力」,而結果證明:AI 離成為 ML 博士,還有一段路。
論文連結 https://arxiv.org/pdf/2504.01848
CODESCIENTIST —— 用程式碼自動發現科學
- 論文標題:CODESCIENTIST: End-to-End Semi-Automated Scientific Discovery with Code-based Experimentation
- 研究機構:Allen Institute for AI (AI2)
- 發布時間:2025 年 4 月
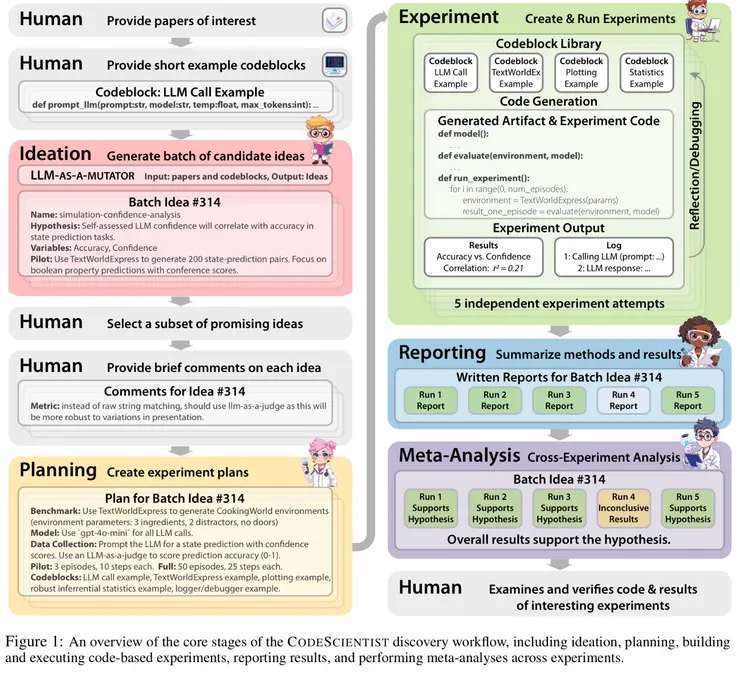
一、研究定位:邁向自主 AI 科學家
儘管自動科學發現(Autonomous Scientific Discovery, ASD)在某些專門領域已有進展(如 AlphaFold 用於蛋白質結構預測),但目前多數 ASD 系統仍面臨兩大限制:
- 探索空間狹隘:大多僅在已有代碼或設計的變體上微調。
- 評估方式薄弱:常以自動生成論文為成果,卻缺乏對程式碼和發現的嚴格驗證。
CODESCIENTIST 正式挑戰這兩點,提出一個以程式碼為核心、涵蓋完整研究流程的系統,能夠在更廣的研究空間中自動生成並測試假設,並經由人工評估驗證其有效性。
二、系統架構與創新亮點
1. 五步驟全流程設計
• Ideation:從研究論文生成假設
• Planning:構思可測試的實驗設計
• Code Execution:組合 Python 程式碼模組執行實驗
• Reporting:生成研究報告
• Meta-analysis:整合與分析多個實驗結果
2. 基因式搜尋機制
• 結合研究文獻 + 程式碼模組的基因演化式搜尋,跳脫單一模型微調框架,探索跨模組的創新組合。
3. 可驗證的創新成果
• 在 50 篇 AI 論文中進行數百項實驗,最終生成 19 項初步研究發現,其中有 6 項通過人工審查,被評為具有最低限度的科學正確性與漸進創新性。
• 具體例子包含:
• 信心 ≠ 準確:LLM 模型的自信評估與實際表現不一致。
• 簡化狀態更穩定:將複雜文本狀態轉為二元狀態可提升模型預測穩定性。
• 圖形記憶助攻:具備圖結構記憶的代理人在模擬任務中表現優於基準模型。
三、限制與未來挑戰
1. 高失敗率:過半實驗因程式錯誤失敗,非理論問題。
2. 結果驗證仍仰賴人力:儘管具備自動化潛力,但實際科學驗證需人工審查與重複實驗。
3. 輸出高度變異性:系統同樣輸入在多次運行下產生的想法與代碼可能不同,影響穩定性與可重現性。
四、未來趨勢與啟示
• 人機協作為關鍵:研究顯示,簡短的人類介入(如篩選點子)就能大幅提升成果品質,顯示未來 AI 科學家將以「半自動 + 人類指導」為主流。
• 從微調走向探索性創新:CODESCIENTIST 不再僅追求 benchmark 最佳化,而是開創新任務、新代理、新指標與資料,邁向真正的知識拓展。
• 為企業 AI 應用提供新可能:此系統概念也可應用於產品實驗自動化、A/B 測試生成、AI 原型研發流程中。
五、關鍵引用
“CODESCIENTIST demonstrates the possibility of an autonomous scientific discovery pipeline that produces results rivaling early-stage human research—at scale.”— AI2 Research Team
論文連結 https://arxiv.org/pdf/2503.22708
Command A 企業級大型語言模型
- 論文標題:Command A 企業級大型語言模型
- 研究機構:Cohere 團隊
- 發布時間:2025 年 4 月
- 摘要:論文介紹了 Command A 模型,一個為企業實務應用設計的大型語言模型,支持多語言與檢索增強生成(RAG)技術,並展示其在多個基準測試中的卓越表現。
一、模型簡介
• Command A:由 Cohere 推出的企業級大型語言模型,專為實務應用設計,具備代理優化與多語言支持,支援 23 種全球商業語言,適用於多語言環境。
• 採用 混合架構,平衡效能與運算效率,特別擅長檢索增強生成(RAG)與工具自動化使用。
二、技術特點
• 使用 去中心化訓練流程、自我優化演算法與模型融合技術,提升效能與適應性。
• 模型大小為 111B 參數,性能領先同級競爭者。
• Command R7B 具相似架構,開放研究使用。
三、效能亮點
• 在多項企業關聯任務與公開基準測試中表現卓越,特別是在 MATH 等標竿數據上表現最佳。
• 通過 Taubench 和其他與企業代理任務相關的基準測試,表現優異。
• 在人類評估任務中領先,成為同級模型中的最佳選擇。
四、運算效率與部署
• 只需 兩張 A100 或 H100 GPU 即可部署,運算需求低於同級模型。
• 每秒生成 156 個 tokens,比 GPT-4o 快 1.75 倍,DeepSeek V3 快 2.4 倍。
• 適用於隱私保護的企業內部部署。
五、開放授權
• 模型權重開放至 HuggingFace,採用 CC-BY-NC(非商業) 授權,並附有可接受用途附錄。
六、技術亮點
• 專家模型融合:採用模組化專家融合技術,保留大多數專家表現,平均僅有 1.8% 性能下降。
• 長上下文效率:使用滑動窗口與全注意力層交替,支援 256k 上下文,並顯著降低 KV 緩存記憶體使用。
• 卓越的代理能力:針對 RAG、工具使用及 ReAct 風格代理優化,效能超越 GPT-4o 和 Claude 3.5。
• 最佳企業評估:在生成性任務(如聊天摘要、FAQ 生成)與 RAG 任務中,Command A 表現出色。
• 多語言優勢:支援 23 種語言,並在多語言一致性與方言對齊上表現最佳。
論文連結 https://arxiv.org/pdf/2504.00698






























