你可能已經聽過很多AI術語,也大概知道其中一些是什麼意思……但其實不太清楚。以下是20多個最常見AI術語的「講給五歲小孩聽」版定義,這些內容來自我的個人理解、大量研究,以及我那些最懂AI朋友們的回饋。
如果你已經都懂了,沒關係,這篇文章不是為你寫的。對其他人來說,下次開會時如果被滿天飛的AI術語搞得頭昏眼花,記得把這份清單放在手邊。隨著新流行語不斷出現,我會持續更新這份清單。模型(Model)

AI模型是一個設計來模仿人腦運作的電腦程式。你給它一些輸入(也就是提示詞),它會進行一些處理,然後產生回應。
就像小孩一樣,模型透過接觸大量關於人們在不同情境下如何反應或行為的範例來「學習」。隨著看到越來越多的例子,它開始能夠辨識模式、理解語言,並產生連貫的回應。
AI模型有許多不同類型。有些專注於語言處理——像是ChatGPT o3、Claude Sonnet 4、Gemini 2.5 Pro、Meta Llama 4、Grok 3、DeepSeek和Mistral——這些被稱為大型語言模型(LLMs)。其他的則是為影片而設計,像是Google Veo 3、OpenAI Sora和Runway Gen-4。有些模型專門產生語音,例如ElevenLabs、Cartesia和Suno。還有更傳統的AI模型類型,例如分類模型(用於詐騙偵測等任務)、排序模型(用於搜尋引擎、社群媒體動態牆和廣告)、以及迴歸模型(用來進行數值預測)。
LLM(大型語言模型)
LLM是基於文字的模型,設計來理解和產生人類可讀的文字。這就是為什麼名稱裡有「語言」這個詞。
最近,大多數LLM實際上已經演化成「多模態」模型,不僅能處理和產生文字,還能在單一對話介面中處理影像、音訊和其他類型的內容。例如,所有ChatGPT LLM模型都原生支援文字、影像,甚至語音。這始於GPT-4o,其中「o」代表「omni」(全方位的意思,表示它接受文字、音訊和影像的任何組合輸入)。這裡有一個關於LLM實際運作原理的絕佳入門介紹,還有Andrej Karpathy的這個熱門深度解析:
Transformer
Transformer架構由Google研究人員在2017年開發,是讓現代AI(特別是LLM)成為可能的演算法突破。
Transformer引入了一種叫做「注意力」的機制,模型不再只能逐字、依序地閱讀文字,而是能夠同時關注所有的字詞。這幫助模型理解字詞之間的關係,使其在捕捉意義、脈絡和細微差異方面比早期技術好得多。Transformer架構的另一個重大優勢是它具有高度可平行化特性——它可以同時處理序列的許多部分。這讓我們能夠透過擴大資料和運算能力來訓練更大、更聰明的模型。這個突破就是我們為什麼突然從基本聊天機器人進化到複雜AI助理的原因。今天幾乎所有主要的AI模型,包括ChatGPT和Claude,都是建立在Transformer架構之上。

最常見AI術語的「講給五歲小孩聽」版定義
訓練/預訓練(Training/Pre-training)
訓練是AI模型透過分析大量資料來學習的過程。這些資料可能包括網際網路的大部分內容、所有已出版的書籍、音訊錄音、電影、電玩遊戲等。訓練最先進的模型可能需要數週或數月,需要處理數TB的資料,成本高達數億美元。
對於LLM來說,核心訓練方法叫做「下一個標記預測」。模型會看到數十億個文字序列,其中最後一個「標記」(token,大致相當於一個詞,見下方token的定義)被隱藏起來,它要學習預測接下來應該出現什麼詞。在訓練過程中,模型會調整數百萬個稱為「權重」的內部設定。這類似於人腦中的神經元如何根據經驗強化或弱化它們的連結。當模型做出正確的預測時,這些權重會被強化。當它做出錯誤的預測時,權重就會被調整。隨著時間推移,這個過程幫助模型提升對事實、文法、推理以及語言在不同情境下如何運作的理解。這裡有一個快速的視覺化解釋。如果你對下一個標記預測能否產生新穎見解和超級智慧AI系統持懷疑態度,這裡有Ilya Sutskever(OpenAI共同創辦人)解釋為什麼它具有看似簡單卻強大的威力:

監督式學習(Supervised learning)
監督式學習是指模型在「有標籤」的資料上訓練——也就是提供了正確答案。例如,模型可能會收到數千封標記為「垃圾郵件」或「非垃圾郵件」的電子郵件,從中學習辨識區分垃圾郵件與非垃圾郵件的模式。訓練完成後,模型就能對從未見過的新郵件進行分類。
大多數現代語言模型,包括ChatGPT,使用一種叫做「自監督學習」的子類型。模型不依賴人工標記的資料,而是建立自己的標籤,通常是透過隱藏句子的最後一個標記/詞並學習預測它。這讓它能夠從大量原始文字中學習,而不需要人工標註。

非監督式學習(Unsupervised learning)
非監督式學習正好相反:模型收到的資料沒有任何標籤或答案。它的工作是自行發現模式或結構,例如將相似的新聞文章分組在一起,或在資料集中偵測異常模式。這種方法通常用於異常偵測、分群和主題建模等任務,目標是探索和組織資訊,而不是做出特定預測。
後訓練(Post-training)
後訓練是指訓練完成後為了讓模型更有用而採取的所有額外步驟。這包括「微調」和「RLHF」等步驟。
微調(Fine-tuning)
微調是一種後訓練技術,你拿一個已訓練的模型,並在特定資料上進行額外訓練,這些資料是針對你希望模型特別擅長的領域量身定制的。例如,你會在公司的客服對話上微調模型,使其以你品牌的特定風格回應,或在醫學文獻上微調使其更擅長回答醫療保健問題,或在特定年級的教育內容上微調,建立一個能以適齡方式解釋概念的輔導助理。
這種額外訓練會調整模型的內部權重,使其回應專門針對你的特定用例,同時保留它在預訓練期間學到的一般知識。這裡有一個關於微調運作原理的絕佳技術深度解析:
RLHF(人類回饋強化學習)
RLHF是一種後訓練技術,它超越了下一個標記預測和微調,透過教導AI模型以人類希望的方式行事——使它們更安全、更有幫助,並與我們的意圖保持一致。RLHF是用於所謂「對齊」的關鍵方法。
這個過程分兩個階段:首先,人類評估員比較成對的輸出並選擇較好的那個,訓練一個「獎勵模型」來學習預測人類偏好。然後,AI模型透過強化學習來學習——這是一個試錯過程,它從獎勵模型(而非直接從人類)獲得「獎勵」,以產生獎勵模型預測人類會偏好的回應。在第二階段,模型基本上是在試圖「遊戲化」獎勵模型以獲得更高的分數。

最常見AI術語的「講給五歲小孩聽」版定義
提示詞工程(Prompt engineering)
提示詞工程是為AI模型精心設計問題(即「提示詞」)的藝術與科學,以獲得更好、更有用的回應。就像你與人交談時,問題的措辭方式可能導致截然不同的回答。同一個AI模型會根據你如何設計提示詞給出非常不同的回應。
提示詞有兩個類別:
- 對話式提示詞:當你與ChatGPT/Claude/Gemini對話時發送的內容
- 系統/產品提示詞:開發人員在產品中內建的幕後指令,用來塑造AI產品的行為方式
RAG(檢索增強生成)
RAG是一種技術,讓模型在執行時能夠存取它們訓練時沒有的額外資訊。這就像給模型一個開卷考試,而不是讓它憑記憶回答。
當你問「本月的銷售額與上月相比如何?」這樣的問題時,檢索系統能夠搜尋你的資料庫、文件和知識庫來找到相關資訊。然後這些檢索到的資料會作為脈絡加入你的原始提示詞中,建立一個豐富的提示詞,然後模型再處理它。這會產生更好、更準確的答案。「幻覺」的一個常見來源是當你沒有透過RAG給模型回答問題所需的脈絡時。
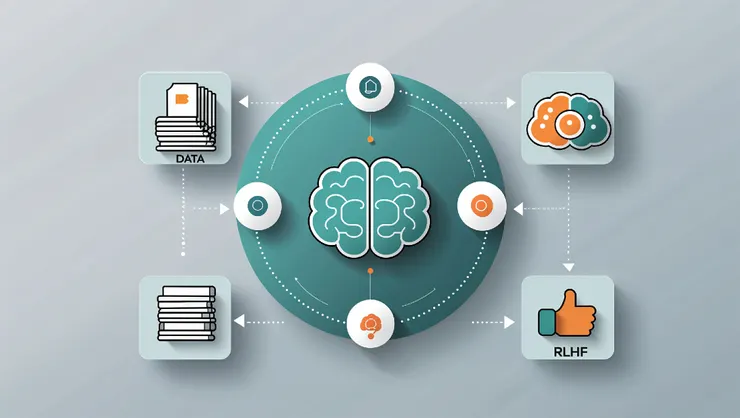
總體來說,總結一下:
- 預訓練:教導模型一般知識(和語言)
- 微調:讓模型專門執行特定任務
- RLHF:讓模型與人類偏好保持一致
- 提示詞工程:精心設計更好輸入以引導模型產生最有用輸出的技能
- RAG:一種在執行時從外部來源檢索額外相關資訊的技術,為模型提供它未訓練過的最新或特定任務脈絡

最常見AI術語的「講給五歲小孩聽」版定義
評估(Evals)
評估(Evals,evaluations的縮寫)是衡量AI系統在特定任務上表現如何的結構化方法,例如正確性、安全性、有用性或語氣。它們定義了你的AI系統什麼是「好」的表現,並幫助你回答這個問題:這個模型是否在做我想要它做的事?
評估基本上是你AI產品的單元測試或基準測試。它們透過預定義的輸入執行你的模型,並將其回應與預期輸出進行比較。這幫助你量化進展、發現問題,並指引你進行改進。例如,這是一個用來衡量模型回應的毒性和語氣的評估可能的樣子。你的模型輸出會被插入到{text}變數中:評估經常被頂尖產品領導者描述為建立成功AI產品最關鍵但被忽視的技能
推論(Inference)
推論是模型「執行」的時候。當你問ChatGPT一個問題,它產生回應時,那就是在進行推論。

最常見AI術語的「講給五歲小孩聽」版定義
MCP(模型脈絡協定)
MCP是最近發布的開放標準,允許AI模型輕鬆、可靠且安全地與外部工具互動——例如你的行事曆、CRM、Slack或程式碼庫。在此之前,開發人員必須為每個新整合編寫自己的自訂程式碼。
MCP還賦予AI透過這些工具採取行動的能力,例如在Salesforce中更新客戶記錄、在Slack中發送訊息、在你的行事曆中安排會議,甚至將程式碼提交到GitHub。AI協定的定義還處於早期階段,還有其他競爭提案,例如Google的A2A和BeeAI/IBM的ACP。
生成式AI(Gen AI)
生成式AI是指能夠建立新內容的AI系統,例如文字、影像、程式碼、音訊或影片。這與只分析或分類資料的模型相對,例如垃圾郵件偵測、詐騙分析或影像辨識模型。

GPT(生成式預訓練Transformer)
「GPT」捕捉了ChatGPT 4.1、Claude Opus 4、Llama 4和Grok 3等最先進LLM運作方式背後的三個關鍵要素:
- 生成式:模型不僅僅分類或分析——它可以產生新內容。
- 預訓練:它首先透過在大量文字上訓練來學習一般語言模式(如上所述),然後可以針對更具體的任務進行微調。
- Transformer:這指的是突破性架構(如上所述),讓模型能夠理解語言中的脈絡、關係和意義。
這三個想法的結合——生成、大規模預訓練和Transformer架構——就是讓ChatGPT這樣的工具在各種任務中感覺智慧、連貫且驚人有用的原因。
標記(Token)
標記是AI模型理解的文字基本單位。對於LLM來說,這有時是一個詞,但通常只是詞的一部分。影像模型有類似的概念叫「區塊」,語音模型則有「幀」。
例如,「ChatGPT is smart.」可能會被分割成「Chat」、「GPT」、「is」、「smart」和「.」這些標記。即使「ChatGPT」是一個詞,模型也會將它分解成更小的片段,使語言學習更具擴展性、靈活性和效率。這個關於Transformer的解釋也很好地解釋了標記,這裡你可以看到頂尖模型如何將詞彙標記化。
代理(Agent)
代理是設計來代表你採取行動以完成目標的AI系統。與像Claude或ChatGPT這樣接受提示詞並快速回應答案的聊天機器人不同,代理可以規劃、逐步工作,並使用外部工具,通常跨越多個應用程式或服務,來實現你設定的某個結果。
最好將「代理」一詞視為一個光譜,AI系統展現越多以下行為,就越具有「代理性」:
主動行動,而非等待提示;制定自己的計劃,而非接受指令;採取現實世界的行動,例如更新CRM、執行程式碼或在工單上留言——而非只是分享建議。
使用即時資料,例如網路搜尋或客服佇列——而非依賴靜態訓練或你手動上傳檔案
建立自己的回饋循環,觀察自己的輸出並在沒有人類協助的情況下迭代
氛圍編程(Vibe coding)
氛圍編程已經變成使用像Cursor、Windsurf、Bolt、Lovable、v0或Replit等AI工具建立應用程式的意思,透過用簡單的英文(即提示詞)描述你想要什麼,而不是寫程式碼。在許多情況下,你根本不會看程式碼。

AGI(通用人工智慧)
AGI是指AI變得「通用」智慧——不只是擅長編碼、數學或資料分析等狹窄任務,而是能夠良好執行各種任務,以及學習如何處理新問題而不需要專門訓練。
當人們談論達到AGI時,他們通常是指AI在大多數科目上比一般人類更聰明的時間點。有些人認為我們已經達到了這個點。
人工「超級智慧」(ASI)是指AGI之後的下一步——在幾乎每個領域都比最優秀的人類頭腦聰明得多的AI。我們相信還沒有達到這個點,關於從AGI到ASI會是快速還是緩慢起飛還存在爭議。
幻覺(Hallucination)

幻覺是指AI模型產生聽起來很有信心但實際上不正確或完全虛構的回應。這種情況發生是因為模型實際上並不「知道」事實或在資料庫中查找資料。相反,它根據訓練資料中的模式預測最可能的下一個標記/詞來產生回應。當它缺乏正確的資訊時,可能會自信地用聽起來合理但不真實的東西來填補空白。好消息是較新的模型在避免幻覺方面越來越好,而且有經過驗證的策略——例如RAG和提示詞工程——幫助減輕風險。
合成資料(Synthetic data)
要訓練越來越智慧的模型,你需要越來越多的資料。但是當模型已經在整個網際網路、所有已出版的書籍、每個錄音、資料集等上訓練過後,我們如何給它們更多資料?部分答案是「合成」資料。合成資料是人工產生的資料。它遵循與人類產生資料相同的模式和結構,令人驚訝的是,它在幫助模型學習方面同樣有效。當真實資料有限、敏感或完全耗盡時,它很有價值。
根據資料類型的不同,合成資料的產生方式也不同:
- 文字:提示LLM根據真實世界的例子產生虛構的客服聊天、醫療筆記或數學問題。
- 影像:擴散模型和GAN建立逼真的視覺效果,從街景到X光片到產品照片,而不複製實際影像。
- 音訊:語音和聲音模型合成模仿真實錄音的語音、背景噪音或音樂。
- 對人類來說,合成資料通常與真實資料無法區分,例如,一個看起來真實但完全是產生出來的聊天機器人對話記錄。
以上皆為本人我趙辰懷Guenter長期的研究資料,若有錯誤敬請留言。轉仔只要註明原出處與超連結即可。本文原本刊載於個人部落格【Nameless 佚名集】

























