好的,那我們開始今天的主題吧。最近啊,我看到兩則跟 Anthropic 有關的重大訊息,真的覺得有必要跟大家整理分享一下。先簡單介紹一下這家公司喔,Anthropic 跟我們比較熟悉、商業味比較重的 OpenAI 不太一樣,他們從創立開始就一直強調「AI 安全」跟「國安風險」,一路專注在對齊、推理、安全規範這些領域。他們家的 Claude 系列模型,在推理能力、風險控管這些地方都很厲害,很有特色,所以像美國政府、國防單位、金融機構,都超級愛用他們的服務。
楊老師AI365 - 為什麼Anthropic對「知識蒸餾」這麼敏感
那今年九月,Anthropic 做了一件非常有骨氣的事情,他直接擴大禁止中國、俄羅斯、伊朗、北韓這些威權國家的公司使用他們的 AI 系統。甚至連那些設立在海外,但是母公司持有50%的公司也算在內,這樣算是他們政府可以控制的公司,他就一律禁止。他們寧願少賺幾億美金,也不讓這些政權有機會把 Claude 拿去「蒸餾」、複製、拆開研究。這種動作非常罕見。
結果幾天前,他們又丟出一個更震撼的消息:Anthropic 他們公布從九月開始就偵測到、攔截並破解了全球第一次「AI 自己規劃、自己寫腳本、自己執行」的大規模網路間諜攻擊。也就是說,這不是人類駭客指揮 AI,而是 AI 自己像代理人一樣,自主跑完整個攻擊流程。
這份報告裡還有說明喔,這個攻擊可能是來自中國的國家級駭客組織,他們利用 Claude Code 當成一個「自動化駭客入侵代理」,在全球 30 幾個目標上發動滲透攻擊,裡面不乏科技大廠、金融機構、化工產業、甚至政府機構。整個攻擊的執行速度快到誇張,每秒數千次請求,遠遠超過人類駭客所能做到的事情。
更可怕的是,裡面高達 80% 到 90% 的攻擊行為都是 AI 自動完成的,人類只在四到六個關鍵節點稍微介入一下。Anthropic 形容這是第一次看到「幾乎完全不需要人類」的 AI 大規模駭客入侵行動,這也意味著全球網路安全正式走入新時代。
講完這兩個故事,你應該就可以知道,Anthropic就是一個很重視「AI 安全」跟「國安風險」的公司。
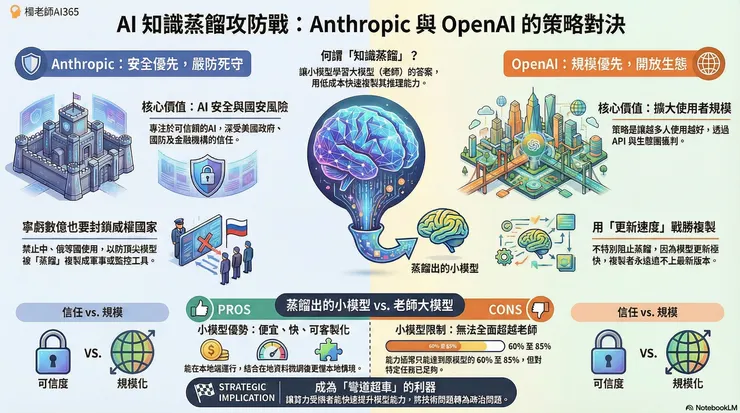
然後,我想特別討論一下,剛剛談到的「知識蒸餾」這個詞。
第一,為什麼 Anthropic 這麼害怕中國拿他們家的模型做「知識蒸餾」?
第二,為什麼 OpenAI 好像沒有這麼擔心被拿去「知識蒸餾」?
第三,被蒸餾出來的小模型,真的能跟老師模型競爭嗎?
先說什麼是「知識蒸餾」。你就把它想成這樣:如果我每天都拿一大堆題目去問一位超強的老師,讓他一直回答、一直解題。然後,我把老師全部的答案整理起來,拿去給我家小學生背。小學生背久了,也會開始「像老師一樣思考」。
這就是 AI 的知識蒸餾。大模型是老師,小模型是小學生。你只要讓小學生讀老師大量產生的答案,小學生就會開始複製老師的邏輯、語氣、推理方式。重點是,成本超低、速度超快,原本要追個三五年的差距,可能一兩個月就拉起來了。
對 Anthropic 來說,他們家的 Claude 在推理能力、程式能力、安全對齊上都是最頂尖的。美國政府、金融機構、企業都把它當成「可信任的合作夥伴」。如果這種等級的模型被大量蒸餾,那不只是商業損失,更是國安風險。當然啊,人家美國花大錢練的老師,被中國公司用便宜的方法複製成「平價版 GPT」,然後用來做軍事、監控、基礎建設、資訊戰,那可不是鬧著玩的。所以 AnthropIc 才會寧願少賺幾億,也要把門鎖緊。
反過來看中國,因為受美國封鎖,沒有最強算力、沒有最新模型,結果就用「知識蒸餾」這條路彎道超車。DeepSeek 就是最典型的例子,不是靠算力,而是靠蒸餾和工程優化,硬是把小模型拉到可以跟大模型打的程度。
那話又說回來,OpenAI怎麼好像老神在在,沒在怕?
其實啊,很簡單,因為 OpenAI 的策略跟 Anthropic 完全不一樣。OpenAI 是商業公司,他們的方向是「讓越多人用越好」,擴散越快越棒。他們主打的是「規模」,然後靠 API、生態圈、企業整合去賺錢。所以對他們來說,只要你願意付費,就算你拿模型去問題目、拿回答當訓練資料,他們也不會特別阻止。而且 OpenAI 的模型更新速度太快了,你今天就算蒸餾 GPT-4.1,結果三個月後人家已經更新到 5 甚至 5.1 了。你永遠追不上最新版,他們也就沒那麼擔心。
你剛剛聽我介紹Anthropic,應該可以知道,他們家強調的不是「規模」,而是「可信度」。美國政府、國防單位、金融機構都是他們的大咖支持者,大咖客戶,這些都是不能馬虎的產業。你只要讓他們覺得你的技術有被複製的可能,信任就崩掉了,那就玩完了。所以 Anthropic 在蒸餾問題上非常警覺,對敏感地區的使用者格外小心。
說到這裡,你一定會好奇:那蒸餾出來的小模型,到底能不能跟老師模型PK?答案是,大模型當然是更全面的好。畢竟,學生再怎麼厲害,一定不可能比老師懂更多,小模型通常只能做到老師的 60%~85%。
但是,如果你要的是夠用就好、速度快又便宜最重要、要能客製化、要能在本地端跑,那小模型就非常吃香了。而且,小模型可能因為更乾淨、更精簡,反而比老師模型更穩。例如客服、FAQ、自動摘要、特定程式語法、金融監理文本分析,只要任務範圍清楚,小模型可以表現到更好。
再加上小模型可以運用「本地端的語料去微調」,例如:中國企業大量用中文資料微調之後,你會發現:原來小模型不只成本低,還更懂本地情境、更好整合到企業內部系統裡。這也是為什麼中國模型,像 DeepSeek、通義千問等等,這兩年進步得非常快,他們很大一部分就是靠蒸餾+本地微調,衝上來的。
你說,從技術角度看,蒸餾不是偷,也不是抄,而是一種節省成本、壓縮能力的工程方法;但從國際政治角度看,只要你大量蒸餾別人家的模型,尤其是蒸一個國安等級的美國大模型,那問題就立刻變成政治問題,而不是技術問題了。



















