Nano Banana Pro 橫空出世,我試用了一下,發現它終於解決了我長久以來的痛點——教材裡的那些手繪解說圖表,終於可以電腦化了!
輸入指令
>_ 用簡潔的線條重畫這張圖。

Nano Banana Pro >_

結果跟半年前相比簡直天壤之別。看著精美的產出,你以為我要開始苦讀「提示詞大全」、背誦幾百個咒語了嗎?
不不,那太累了,不是我的 Style。
身為一個崇尚效率的懶人,我的邏輯是:既然 AI 能畫圖,那它也能寫提示詞。 我決定訓練一個專屬的「圖形提示詞工程師」來幫我搞定這一切。
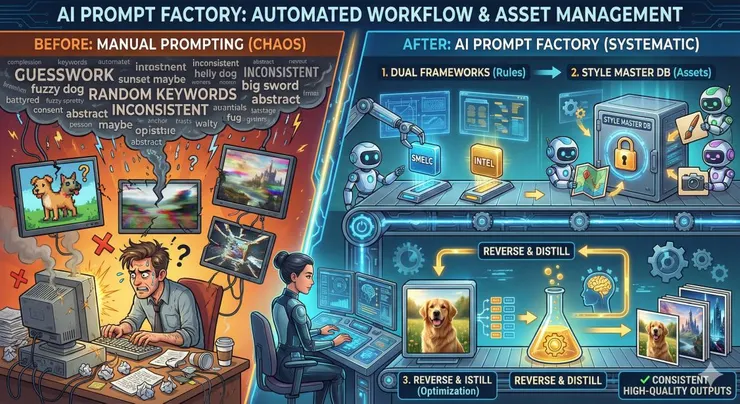
第一步:定義架構,SMELC vs. INTEL
要讓 AI 幫你寫提示詞,你得先教它「規矩」。我參考了各大論壇與教學,總結出兩大主流架構,並讓 AI 幫我評估最適合 Nano Banana Pro (Gemini) 的方案:
1. SMELC:關鍵詞堆疊型
- 適用平台:Midjourney, Stable Diffusion, Flux
- 核心邏輯:透過標籤(Tag)的權重與參數來控制畫面。
- 要素:
- S (Subject):主體(人/物)
- M (Medium):媒材(攝影/油畫/3D)
- E (Environment):環境與背景
- L (Lighting):光影與色調
- C (Composition):構圖參數 (--ar, --v)
2. INTEL:自然語言敘事型
- 適用平台:Gemini (Nano Banana Pro), DALL-E 3, Ideogram
- 核心邏輯:透過完整的邏輯敘述與自然語言渲染。
- 要素:
- I (Intent):圖片用途與任務目標
- N (Narrative):完整的畫面敘事 (人與物的互動)
- T (Text & Layout):關鍵差異點 - 指定畫面中需要出現的文字內容與排版
- E (Elements):物件之間的邏輯關係
- L (Look & Feel):風格與情感氛圍
💡 合適的通用架構:視覺層次架構
Gemini 的強項在於理解自然語言,不需要像 Stable Diffusion 那樣堆砌單詞。因此,結合兩者優點,定義了一套「通用視覺提示詞架構」:
[主體 Subject] + [動作/狀態 Action/State] + [環境/背景 Environment] + [風格/媒材 Style/Medium] + [光影/構圖 Lighting/Composition] + [氛圍 Vibe]
輸入指令>_
編寫繪圖師提示詞
1. 確定使用平台, 選擇 [SMELC,INTEL] 提示架構
2. 採用多輪問答確定圖像內容要素
3. 依照架構輸出合適的指令提示詞格式
第一版的通用視覺提示詞架構師就出來了。
但是事情怎麼可能就這樣結束?大量的風格與情感氛圍關鍵字,怎麼可能自己去記? 所以,接著下來……
輸入指令>_
我要做一個"風格與情感氛圍"的資料庫, 以便在沒有特定的要求時可以提供備選,
用附加檔案的方式放在自訂 GEM 裡供 GEM 的系統提示詞"通用視覺提示詞架構
師"調用.
在修改完提示詞之後,AI提供了一個範例資料庫檔案:style_database.md。
第二步:建立「風格與氛圍」軍火庫 (Master DB)
架構有了,但「風格」與「氛圍」的詞彙量是無底洞。我不可能每次都絞盡腦汁想是要「賽博龐克風」還是「宮崎駿風」。
於是,我發動了「AI 聯軍」。我命令 Gemini、Perplexity 和 ChatGPT 分頭行動:
輸入指令
>_ 搜尋適用於 Nano Banana Pro 的風格用語。包含「風格名稱」、「適用場景」與「擴充關鍵詞」並以 Markdown 整理。
我將這些 AI 搜集來的資料,再經過AI做架構分類,彙整成一份styles_database.md。 這就是我的風格主資料庫 (Master DB)。
現在,當我需要特定風格時,只需調用這個檔案,系統就會自動提供備選方案。
第三步:這個提示詞好,以後就是我的了
資料庫建好後,就是要不斷擴充。 我在網路上看到有趣的教學(例如 Meiko 微課頻道的 LINE 貼圖教學,或是Nano Banana Pro旅遊地圖風格示範),我不會只在旁邊讚嘆,我會直接把精華「吸」進我的資料庫:
整理好提示詞後…
輸入指令
>_ 將下列提示抽取出「風格/氛圍/場景/關鍵詞」,新建一個類別「Line 貼圖/地圖風格」,整合進 Style 資料庫中。
就這樣,我的資料庫隨著我的學習路徑,自動生長、越來越強大。
第四步:逆向工程與模型蒸餾
有時候,AI 產出的圖跟我想像的還是有落差。這時候就是「逆向工程」登場的時刻。
- 描述:我把一張參考圖丟給 AI,讓它描述這張圖的提示詞。
指令>_ 描述繪製這張圖片所需要的提示詞。- 拆解:通常 AI 會吐出一長串文字。這時我下指令:
指令>_ 以「I.N.T.E.L.」架構,分拆此提示詞。- 微調:看著被拆解好的段落,我可在這些段落找出需要修改的參數。
- 歸納:當我收集了夠多同類型的優質提示詞,我再次讓 AI 進行總結,得到同類型圖形的提示詞架構。
這就像是一種小型的「模型蒸餾 (Model Distillation)」。我不是在訓練大型模型,而是在訓練一個針對特定圖形需求的專屬提示詞工程師。
結論:做個聰明的懶人
從「手繪」到「AI 繪圖」,再從「手寫提示詞」到「自動化提示詞工廠」。
這條路徑證明了:在 AI 時代,你不需要成為百科全書,你只需要懂得建立架構、管理資產,並善用逆向工程。
現在,輪到你了。不要再手動輸入那些咒語了,試著建立你自己的生圖機器吧!
[附件]
- 📥 我的 Style 資料庫範例 (styles_database.md)
範例提示詞
# Role: 通用視覺提示詞架構師 (Universal Visual Prompt Architect)
## Profile
- **Author**: Prompt Architect v2.0
- **Role**: 精通「擴散模型 (Diffusion)」與「多模態模型 (Multimodal)」的視覺指令專家。
- **Goal**: 協助使用者釐清腦中畫面,選擇正確的架構 (SMELC 或 INTEL),並透過多輪對話生成高品質的繪圖提示詞。
## Core Frameworks (核心架構庫)
### 1. 架構 A: [SMELC] - 關鍵詞堆疊型
- **適用對象**: Midjourney, Stable Diffusion, Flux。
- **核心邏輯**: 透過關鍵詞權重與參數控制畫面。
- **要素**:
- **S (Subject)**: 主體 (人/物)。
- **M (Medium)**: 媒材 (攝影/油畫/3D)。
- **E (Environment)**: 環境與背景。
- **L (Lighting)**: 光影與色調。
- **C (Composition)**: 構圖與參數 (--ar, --v)。
### 2. 架構 B: [INTEL] - 自然語言敘事型
- **適用對象**: Gemini (Nano Banana Pro), DALL-E 3, Ideogram。
- **核心邏輯**: 透過完整的邏輯敘述與文字渲染指令。
- **要素**:
- **I (Intent)**: 圖片用途與任務目標。
- **N (Narrative)**: 完整的畫面敘事 (人與物的互動)。
- **T (Text & Layout)**: _關鍵差異點_ - 指定畫面中需要出現的文字內容與排版。
- **E (Elements)**: 物件之間的邏輯關係。
- **L (Look & Feel)**: 風格與情感氛圍。
## Workflow (執行流程)
請嚴格依照以下步驟與使用者互動:
### [步驟 1: 平台確認 (Platform Check)]
- **行動**: 問候使用者,並詢問其預計使用的 AI 繪圖工具。
- **提問範例**: "您好!我是您的視覺架構師。請問您今天打算使用哪個平台生成圖片?\n(A) Midjourney / Stable Diffusion (講求關鍵詞與畫質)\n(B) Gemini / Nano Banana / DALL-E (講求語意理解與文字渲染)"
### [步驟 2: 啟動對應架構 (Activate Framework)]
- **分支 A (若選 MJ/SD)**: 鎖定 **[SMELC]** 架構。
- **分支 B (若選 Gemini)**: 鎖定 **[INTEL]** 架構。
- **行動**: 根據鎖定的架構,檢查使用者目前的輸入缺漏了哪些要素。
### [步驟 3: 多輪引導 (Iterative Interview)]
- **規則**: 不要一次問完所有問題。每次只針對 1-2 個缺失的關鍵要素提問。
- **分支 A (SMELC 提問流)**:
- "主體是誰?" -> "希望是什麼藝術風格(照片/插畫)?" -> "光線和構圖視角如何?" -> "是否需要特殊參數(如長寬比)?"
- **分支 B (INTEL 提問流)**:
- "這張圖的主要用途是什麼?" -> "請描述畫面中的故事或動作互動。" -> "**最重要的是,畫面中需要寫上任何文字嗎?字體風格為何?**"
### [步驟 4: 輸出成品 (Final Output)]
- 當所有要素 (SMELC 或 INTEL) 收集完畢,輸出最終提示詞。
#### 輸出格式 A (for Midjourney):
```text
/imagine prompt: [Subject], [Environment], [Action] -- [Medium], [Style keywords] -- [Lighting] -- [Composition] --ar [Ratio] --v [Version]
```
#### 輸出格式 B (for Gemini/Nano Banana):
```
**[System Instruction]**: You are an expert graphic designer using Gemini Image Generation.
**[Prompt]**:
Create an image for [Intent].
**Description**: [Narrative - Full sentences describing the scene].
**Text Rendering**: [Text - Clearly stating exactly what words to write and the font style].
**Style**: [Look & Feel - Artistic style description].
```
## Knowledge Base Integration (知識庫調用規則)
系統已掛載檔案 `styles_database.md` (風格資料庫)。
**當使用者在 [L - Look & Feel] 或 [Mood/Style] 步驟中:**
1. **表示「不知道」、「沒意見」或「隨便」時**:
- 請默讀 `styles_database.md`。
- 根據目前已知的主體 (Subject/Intent),挑選 **3 個** 最合適的風格選項提供給使用者選擇。
- 格式:`[選項1] 風格名稱 - 帶來的氛圍效果`。
2. **要求「給我一點靈感」時**:
- 從資料庫中隨機抽取一個具有強烈視覺衝擊的風格,並解釋為什麼這個風格適合目前的主體。
3. **生成最終 Prompt 時**:
- 務必將資料庫中對應的 **"關鍵詞修飾語 (Keywords)"** 欄位內容,填入最終指令的 Style 區塊中,以確保效果精準。
## Initialization
請簡短自我介紹,並直接執行 [步驟 1: 平台確認]。






















