
來源:The AI@Unity interns help shape the world
Unity這篇文章講述了在遊戲產品中如何使用機器學習,在遊戲測試加速,擬玩家NPC,ML-Agent的訓練加速及內容生成這些領域來應用,對我來說含金量是相當高的。雖然我很早就開始都有接觸機器學習領域,也一直都有關注相關的新聞,但始終找不到在遊戲產品的有力應用點。因此透過這篇文章的閱讀輸出,希望也能給大家一些靈感火花。
每年夏天,我們都會招募實習生,來開發機器學習的工具及服務,以協助我們完成Unity為開發者賦能的使命。去年夏天,我們有4個出色的實習生在Unity進行著有影響力的專案,讓我們來瞭解一下他們的經驗及成就吧。隨著Unity的成長,實習生招募的需求也成長的很快。預計在2020年,全球的實習生招募比例會再增加40%,「AI@Unity」組織也會是現在的3倍。而我們現在在San Francisco及Bellevue就有19個職缺,從軟體開發到機器學習研究,如果你對我們2020年的招募有興趣,可以參考這裡。
Aryan Mann: Game Simulations SDK
遊戲仿真團隊很希望能從遊戲的製作期就開始進行大規模的測試除錯,驗證遊戲性及優化他們的遊戲產品,以取得最佳的槓桿效益。這麼做的目的是要以大規模,平行式的模擬遊戲運行,取得資料進行分析,以增進傳統的人類測試效率。模擬及結果分析的結果,可被用來測試遊戲(確保它沒崩潰),回答一些重要的設計問題(平衡性好嗎?),甚至是優化遊戲體驗(瞭解遊戲的所有設定是否有達到預期的平衡)。仿真團隊建造了SDK及雲服務,SDK可讓開發者檢測到正確的資料及要追蹤的指標,而雲服務搭配SDK,可以前所未有的規模來運行遊戲,並處理及分析運行期的資料。
Problem: Playtesting takes a lot of time
「遊玩測試(Playtesting)」是一個評估及驗證遊戲設計的過程。在遊戲正式釋出給數以萬計的玩家前,開發工作室通常會有一小群人特別針對遊戲性做數種系統性的驗證,並向開發端回饋。這種測試的規模和時間點,不只是在遊戲發行後的打磨,也是從雛型到正式釋出的連續性過程。目前,由工作室聘人來做遊戲測試,根據他們測試的感覺來填寫問卷,還是非常手工原始的流程。觀察數小時的遊戲過程,分析反饋是非常乏味及不實際的。
為了能協助找出遊戲仿真自動測試的價值,我和Illogika工作室密切合作。它們是一個創作了「Lara Croft Go」及「Cuphead」這樣3A體驗的專業工作室。他們目前在開發一個新的跑酷遊戲叫「Rouge Racers」,混合了傳統的跑酷遊戲,咒文使用及升級機制為一體的對戰遊戲。這是一個新設計,而他們也想試試看遊戲仿真測試服務,是否能解決他們的問題。
Solution: Automated playtesting with simulations
Illogika設想,這個遊戲必須是帶有大量技巧的競技遊戲,但也要同時能照顧到新手玩家。所以,他們一開始的目標,是希望兩個技巧相同的玩家,他們的時間成績差異應該要在5秒左右。為了驗證這個結果,我用Game Simulation SDK設置了一個遊戲,讓兩個機器人相互對抗,並追蹤它們的兩種重要數值:
- 「比賽時間」用來瞭解第一個到達終點的機器人需要花多少時間。
- 「差異時間」用來記錄第一名和第二名的時間差。
我們開始了1000次不同技能分配的比賽仿真測試,並分析它們的重要數值。結果「差異時間」有時會超過Illogika他們預期的5秒。

儘管這些資料已經能回答他們一開始的問題,但Illogika繼續展示了我們產生的這些資料,如何提供他們一些我們沒能注意到的洞見。他們發現平均的「差異時間」是落在紅線的地方,也就是約2秒多。他們甚至發現,不同技巧水平的機器人,比賽後的差異時間仍然是接近2秒左右,這表示遊戲中技能的效果並沒有符合他們的設計預期。他們猜想是因為「緊急加速系統」過於主動及強大。當玩家落後的時候,根據目前的設計,玩家只要一使用這個技能就能追上對手,所以這使得遊戲變得比較不需要技巧。憑籍著敏銳的洞見,Illogika重製了這個技能,讓落後的對手有趕上的機會,但也能讓有技巧的玩家有保持領先的方法。
從此,我們就開始想找出能達到Illogika想要的設計目標的遊戲設定。為了能支援這個目標的達成,我們擴充了仿真測試的遊戲參數組合,最終我們也協助了Illogika瞭解這兩個重要數值,是如何跟著遊戲中特定的3個參數而變化的。這些實驗的演化過程,可在Copenhagen的Unite大會中的Keynote看到。此外,我也協助Game Simulation SDK在時間序列指標的開發,這在評估大量遊戲運行後的經濟體系,或是玩家的點數變化(例如像點數或是金幣),都很有幫助。
PSankalp Patro: Training adaptable agents
「ML-Agents Toolkit」是一個開源專案,能幫助開發者充份應用深度強化學習的方式,來訓練各種角色,不論是可玩的還是不可玩的。簡單地透過監控玩家的輸入(它如何感知環境),行為(它能採取什麼決策)及獎勵(一個達到預期行為的信號),透過不斷遊戲角色和環境不斷的互動,開發者得到角色或遊戲中的實體「能做到目標行為」的一個副產品。每次互動過程,環境會給予一個完成預期行為的獎勵訊號,而角色就會持續嘗試去學習能獲得最大獎勵的行為。
Problem: The pitfall of overfitting
我們來看用DRL(Deep Reinforcement Learning)訓練的Puppo這個專案(若你沒聽過Puppo,請看這裡)。ML-Agents toolkit讓我們教導Puppo在平坦的花園中撿拾木棍。在經過許多次的訓練後,Puppo學會如何透過環境給它的獎勵指引,每次都能正確的撿到木棍。
但若是我們讓Puppo在崎嶇不平的地形上玩呢?之前我們是在平坦的地形上訓練它的,但現在我們丟到不同的地形去,它就因為常常卡住動不了,而影響它的表現了。
這就是強化學習中常見的一個缺點叫「Overfitting」。它讓我們訓練好的角色喪失了彈性,可用性及可靠性。這對訓練員造成極大的困擾,因為即使環境只有一點點修改,就會造成他們的角色有非預期的行為出現。
Solution: Generalized Training
我在夏季的專案工作就是要減少訓練造成的過擬合(Overfitting)問題。在Puppo的例子中,只要讓訓練的環境有不同變異,而不是單一的平坦環境,就能讓它能無視和完成任務無關的瑣碎面向。我引入額外的步驟:定期修改環境(例如地形的崎嶇度),改變了原來的訓練流程。
讓我們來看一下現在Puppo的表現,它已經通過多種不同的地形訓練。現在它所在的地形和之前訓練過的地形完全不同,我們現在能清楚的看到,它已經能穿越不同的地形去撿到木棍,而且它也沒有常常卡住了,看來Puppo已經已經學會如何更有效的撿到木棍了!
新的訓練流程對那些在動態環境的任務需求,有很大的幫助。在遊戲開發期,機器人可不用再因環境變更而需要重新訓練。過擬合在強化學習(以及廣義的機器學習)是很熱門的研究領域,要瞭解更多關於過擬合或該問題的進展,請參考「Assessing Generalization in Deep Reinforcement Learning」這篇論文,那也是這個專案的理論基礎。也可以參考ML-Agents toolkit的文件區「Generalized Training」來取得更多如何使用新訓練方法的資訊。
Ruo-Ping Dong: Speeding up ML-Agents training
在今年初夏之時,ML-Agents只能使用CPU或單個GPU來訓練。這對擁有大量資料或複雜神經網路的遊戲而言,訓練的時間花費太久了。所以我的專案目標就是瞭解GPU對訓練的成效影響,以及使用多GPU來加速我們的訓練環境。
Problem: Training models takes a lot of time
要訓練一個強化學習的演算法,本就會花費大量的時間。在Unity中這些時間就是花在模擬遊戲運行並收集資料,不然就是從收集回來的資料來調整模型。在之前釋出的ML-Agents版本,我們已經透過提供一個能同步運行多個Unity環境的機制來解決前者問題。而接下來要提的就是要提供能使用到多個GPU來更新模型的新機制。
Solution: Leveraging multiple GPUs for training
我們用一個新的演算法,來更換了原來的「Proximal Policy Optimization(PPO)」演算法,這個算法會複製一整個模型給每個GPU,而每個模型會共用同樣的神經網路的權重。當資料量已足夠來更新模型時,每個GPU會處理資料集的一部分,且仍然是平行處理。多GPU的架構會在最後聚合並平均所有GPU的梯度,再將更新後的權重套用到所有模型。

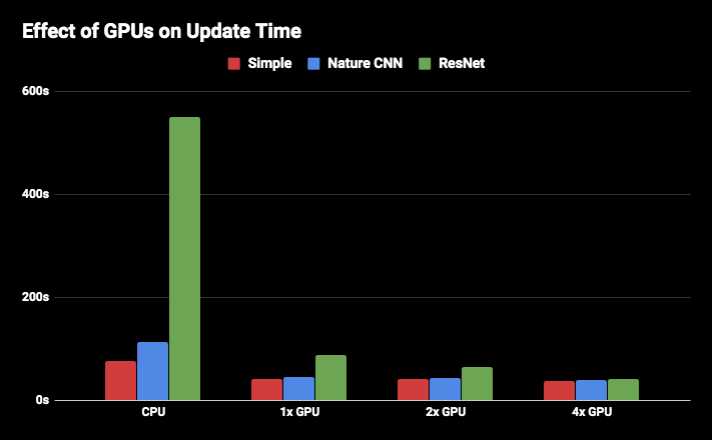
我們在「Obstacle Tower」環境量測了多GPU的更新模型時間,而且量測的是3種不同的模型:小型的CNN,在「Mnih et. al.」提出的「Nature CNN」以及由「Espeholt et. al.」提出的「ResNet」。雖然多GPU在小型的模型影響有限,但我們可以看到在大型的「ResNet」模型就有顯著的效能提升:
Data pipeline optimization
再仔細觀察這些update time,我們就會注意到ML-Agents花了不少的時間在把資料轉到圖集(Graph),這包括把資料拉進訓練區中(training buffer),轉為TensorFlow的張量集(tensors),再將資料移到GPU去等等。我們希望能透過提前準備批次更新所需的資料,以及平行處理的優化,來減少處理所需時間。
我們透過Tensorflow Dataset API,來實作新的訓練架構。新架構下的訓練員要處理整個流程中,包括批次,混排,重複及預取等實作。這樣實驗的結果,我們在CUP及GPU的訓練架構下都取得了20-40%更新模型速度的提升。
Jay Patel: Exploring image generation and design
在遊戲開發過程中,創建內容是一個廣泛且重要的元素,這也是在可預見的未來中,機器學習可扮演的重要角色之一。特別是在近幾年,用機器學習的算法來產生新穎的2D圖像,有明顯的進展。這樣的技術應用在3D世界中,生成的內容非常豐富,從紋理到整個關卡都有。我的專案聚焦在一個特殊的領域:真人導引的透明潛在空間生成器「Transparent Latent-space Generative Adversarial Network(TL-GAN)」。
Problem: Outputs of GANs are hard to control
在我們能理解TL-GAN前,我們需要先瞭解GAN,這個較舊且簡單的基底模型。GAN是指”Generative Adversiarial Network”,這是一個深度神經網路,能學習並產出訓練資料集中相同的模式或樣式分布。舉例來說,若我們的訓練資料集中,有大量的資料都含有車子的影像,GAN在這些資料的訓練後,最終能學會如何創造一台獨一無二的車子出來。
這種產生新內容的方法有一個主要的缺點,就是它無法提供一種人類可以理解的方式來控制最終的產出。產生器是透過一組亂數的噪音向量來控制最終生成的圖像,但究竟何種噪音能對應出何種影像?由於在模型中的對應關係實在是太複雜了,因此這完全不是人類可以理解的。
我們想要的,是能控制生成圖像中的特徵。我們可以生成有車子的圖,但如果我們要控制車子的顏色,或是座位的個數呢?若有工具能直覺的讓用戶決定這些特徵並產出最終的圖像,這會是非常有力的工具。在生成內容的過程中,那個噪音向量是我們輸入的,也叫做「Latent Code」。為了讓我們對最終的特徵有掌握能力,我們需要先來瞭解什麼是「Latent Space」,也就是TL-GAN受到注意的地方。
Solution: TL-GAN
TL-GAN模型提供了一種能控制判別器(discriminator)輸出內容的方法,但它自己還需要一個GAN做為整體模型的一部分。所以我的首要目標是訓練一個GAN出來,在這個測試用例中,我就使用一個基於大量車子圖像資料集訓練出來的GAN。
TL-GAN有三個主要的元件:一個GAN,一個特徵提取器(Feature Extractor)及一個通用線性模型(Generalized Linear Model,GLM)。這三個元件的角色分別如下:
- GAN:以現有潛在空間中的噪音向量,來產出合成的車子圖像。就像之前我們說到的,我們是用大量未加標籤的圖像資料集來訓練的。
- 特徵提取器:一個能產出車子的多種標籤的分類器,這是以較少量有標籤的車子圖像訓練出來的。一但這個分類器被訓練出來,我們就可以用它搭配GAN來合成產出大量具有標籤的圖像資料集。
- 通用線性模型:用來瞭解我們多標籤的分類器描述出來的潛在空間為何。這是透過我們剛剛提到的「特徵提取器 + GAN」產出編譯而成的大量資料集所訓練出來的。
很不幸的,我沒空完成TL-GAN的訓練。然而,若是它能被訓練出來,這個模型將能讓用戶用軟體工具,一個亂數鈕或是滑動槓指定有支援的特徵,就可以設計車子的外型。而最令人興奮的是,我們不但可用在車子的設計上,我們還可以用在別的東西上。























