一、人工智慧發展產業的最新背景資料與本場智庫研討會的基本說明
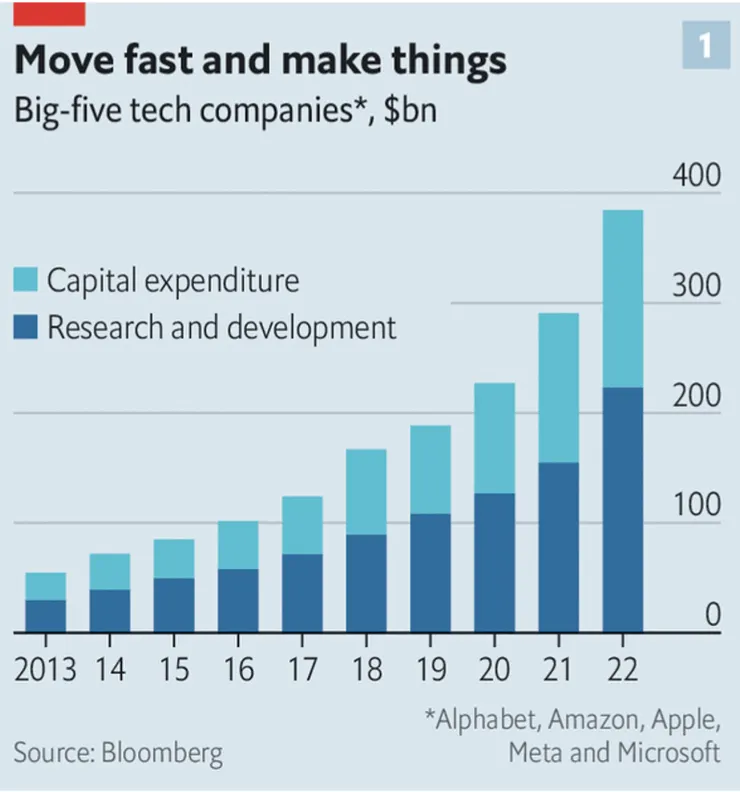
面對微軟和谷歌都已經推了自己的生成式人工智慧工具,Amazon要強化和AI新創公司Hugging Face的合作。臉書也要加速推動其AI相關的產品上市。2022年美國五大科技公司(臉書、谷歌、蘋果、亞馬遜和微軟) 在研發上一共投入了2230億美金,在2019年是只有1090億美金。此外他們的資本支出一共是 1610億美金,也在是三年內便翻倍的數字。
這兩方面的開支加起來差不多是這五大科技巨頭26%的營收,2015年研發和資本支出佔營收的比例是16%。當然這些開支不會全部花在最尖端的科技,但臉書就說AI 是最優先的投資項目。谷歌在下一季的季報中將首次透露在AI上的投資金額。
《經濟學人》從這些科技巨頭的投資資料、收購項目、招聘公告、專利和 論文內容以及員工的LinkedIn貼文去觀察,發現各家都投入相當多的資源 在科技上。而根據一家研究機構Pitch Book的資料,這些公司大概從2019開始的投資和併購有高達五分之一都和AI有關,比加密貨幣、區塊鏈、去中心化、Web3(2%)和元宇宙 (6%)等項目都多很多。根據另一家研究機構 Predict Lead的資料,這些科技巨頭有10%的職位招聘需要AI技能,《經濟學人》去Linkedin上去看這些科技巨頭員工帳號上的自我敘述,發現其專長和AI有關的比例也差不多。
但是這些數字看不出五大巨頭的差異,《經濟學人》自己的評估是目前微軟和谷歌領先,臉書在後面追。從注資的項目來看,過去四年,五大巨頭投了兩百多家 AI公司,現在還在加速投資。從去年一月開始,五大巨頭每個月大概都投一家AI 公司,這是比前三年快三倍的速度。微軟是領先者,1/3的入股案都是和AI有關,這比谷歌和亞馬遜比例多兩倍,是臉書的六倍多,蘋果幾乎沒有在這方面投資。除了最成功的案例OpenAI,微軟還注資給 D-matrix 幫資料中心發展AI科技的,還有另一家Noble.AI是用演算法來統整實驗室的工作和其他研發項目。微軟也積極收購AI 新創公司,四分之一的收購和這領域相關。
這場線上研討會活動是由美國五大智庫的布魯金斯研究所主辦,有五位經濟學家參與。進行的形式是有喬治城大學的Alberto Rossi擔任主持人並提問,一開場是先由在維尼尼亞大學經濟系、Darden商學院任教以及擔任美國國家經濟研究院(NBER)研究員的Anton Korinek提供關於最新生成式人工智慧發展情況的概覽與初步的正負面影響評估,再來由主持人對另外三位來賓分別提問,第一位是史丹佛大學經濟系教授,2007年美國經濟學界最高榮譽(只頒給40歲以下的經濟學家)克拉克獎章得主Susan Athey、第二位是以探討製造業外移中共讓美國損失多少工廠職位論文《China Shock》 廣受矚目的麻省理工學院經濟系教授David Autor 還有一位是軟體工程師出身,專長是研究軟體工程師如何增強其專業技能的賓州大學華頓商學院教授Prasanne Tambe。
二、Anton Korinek的開場演講
他先點出最近出現的生成式AI和過去以深度學習為基礎的AI有何不同:
舊典範: 深度學習 對世界有很大影響 但在人類智慧和AI 之間還有很大的差別
新典範: 生成式AI所依靠的基礎模型是以深度學習為典範,但在性質上很不同,竟然是很詭異地像是一個人類在發言。
現在的生成式AI背後是一個很大的模型,大約有10^11個參數,而且還在增加中,這和人類大腦的複雜度很像。這種基礎模型都是屬於大型語言模型(LLM)如微軟注資OpenAI 所研發的ChatGPT 4和谷歌的 Bard。ChatGPT-4在通過各類標準化考試(LSAT/GRE)的表現都比前一代ChatGPT-3好,例如美國高中生要進大學需要考的LSAT,GPT-4 的成績贏過了85%的人類受試者,在申請研究所的GRE考試上,ChatGPT-4贏過99%的受試者。
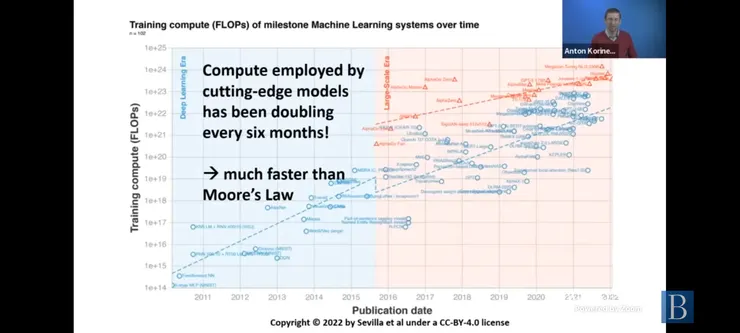
和晶片的摩爾定律(每兩年晶片的運算速度快一半,所以二十年速度快一千倍)比較,這類生成式AI計算能力是每六個月就加快一倍,所以一年快4倍。每5年就快一千倍,這比摩爾定律更驚人。這類大型語言模型,都是在餵給它大量資料後進行自我監督的學習,訓練完成後,可以做翻譯、邏輯推理 (有人說 GPT-4 通過心智能力測試,但這並不盡然,只是運用了邏輯推理) 和創意寫作 (寫詩,寫劇本) 、寫程式等。
在訓練的過程中,生成式AI的系統發展出了一套關於這世界如何運作的模型,可以應用在各種類型的任務上,產出非常看來智慧性很高的成果,這也讓我們要重新思考人腦到底是否運作的。這類以大型語言模型的生成式AI 能發揮的能力還很多,還要等大家一起探索,而且看得出其能力增強的速度有多快。所以只要餵給它更大量的資料,強化它的運算能力、增加模型的參數,就能預測 其功能會以多快的速度變強。
目前對大型語言模型存在兩種看法。第一種是認為這只是種隨機鸚鵡或是先進的自我完成模型 (advanced auto-complete) ,只是個統計模型,抓得出詞彙出現的頻率,然後就自動推出答案,但根本不知道自己弄出來的東西是什麼。第二種看法是這樣的大型語言模型,是朝向人類一般的智慧邁進中。
這兩派之間有很多討論。這兩種看法其實都各有一定的道理,


























