多層次資料問題指的是在社會科學研究中,我們經常透過問卷以班級或學校為單位進行調查,此時收集到的資料很可能存在著多個層次的結構。這意味著我們觀察到的個體或單位被分類或分群到不同的層次中。本文將簡介此用傳統統計分析多層次資料結構的問題和限制
例如:我們對學生的學業成績進行研究。我們不僅有個別學生的資料,還有學校、班級和縣市等不同層次的資料。這些層次之間可能存在著巢套關係,也就是學生屬於班級,班級屬於學校,學校屬於縣市的層次結構。同個班級/學校/縣市的學業成績可能有很高的相似性。

多層次資料的存在使得傳統的統計方法無法直接應用,因為這些方法通常假設觀察到的資料是獨立的。然而,在多層次資料中,個體之間的觀測可能相互關聯,例如學生的成績可能受到所屬班級或學校的影響。
為了解決這個問題,出現了多層次模型(MLM)或階層線性模式(HLM)。這些模型能夠考慮到多層次資料的結構,並在分析中引入階層結構的效應。通過建立階層模型,我們可以進一步瞭解不同層次對於觀察結果的影響程度,並進行更準確的統計推論。
總結來說,多層次資料問題是可能違反資料獨立性的假設。MLM或HLM則是用於處理這種問題的統計方法,能夠更好瞭解層次結構對研究結果的影響。
下面的圖很好展現多層次資料的問題,如果我們沒有將各群組區分出來,就將全部樣本拿去跑迴歸分析,就會發現V2和V1的是負向相關(黑線),反之,如果我們將各個群組區分出來(A~J),就會發現各組的V2和V1呈現正向關聯(不同顏色的線)。
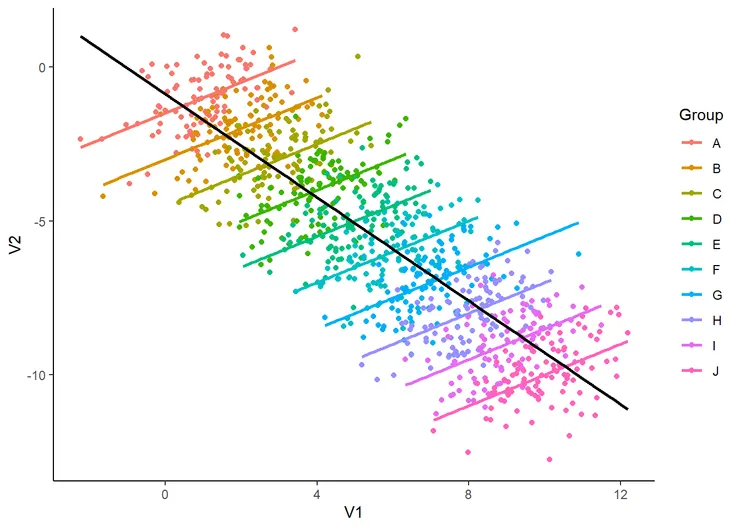
在心理學研究中,我們確實意識到個體的行為不僅受到自身特質的影響,還受到周圍環境和脈絡的影響。這些脈絡特性包括文化、社會互動和他人的行為,它們都可能對個體的行為和心理過程產生重要影響。
如果研究者忽略這些脈絡特性,僅僅假設資料之間是相互獨立的,並使用傳統的統計方法進行分析,那麼就有可能產生偏差的結果。這種偏差可能導致型一誤差的產生,也就是誤判了研究結果的統計顯著性。
多層次模型(HLM)或階層線性模式(MLM)在這種情況下就非常有用了。這些模型可以考慮到個體間的相互依賴關係,並且能夠結合個體層次和群體層次的資料進行分析。透過這樣的模型,研究者可以同時考慮到個體和脈絡特性之間的關係,進一步了解個體行為的多重因素。如果對分析有興趣,可以看接下來一系列的更詳細多層次分析介紹和統計操作文章(請點我)。
心理學研究已經證明了個體的行為受到脈絡特性的重要影響。若忽略這些特性並僅假設資料間相互獨立,使用傳統統計方法進行分析,可能導致偏差的結果。MLM或HLM考慮到個體間的相互依賴關係,能更好地處理這種情況
您的研究遇到了統計分析的困難嗎?您需要專業的統計諮詢和代跑服務嗎?請點我看提供的服務






















