本篇使用 AI 翻譯濃縮原文,筆者人工校稿完成!
本篇適合正在摸索如何設計 AI Agent,Anthropic 團隊現身說法,告訴大家他們如何製作 AI Agent。
名詞定義
以下是筆者認為很重要的一部分,所以閱讀這篇文時,想先跟大家釐清幾個「我認為」可以先好好思考下面釐清幾個概念:「Agent」、「Tool」
- 代理人、代理(Agent):可以視為跟 AI 互動的節點。AI 在接收使用者問題後、至回答使用者問題前,可能使用各種「Tool」、參考各個跟使用者互動的「Memory」,經過思考、選擇,就是一個完整的「AI Agent」。
- 工具(Tools):任何可以讓 AI 選擇使用的工具。可能是一隻 API、一個 MCP、一個簡單的函式。
全文長話短說
- MCP(Model Context Protocol)讓 LLM Agent 結合大量工具來解決真實問題,但關鍵在於這些工具是否品質高且適用性佳。
- 多利用 Claude Code 快速 prototype,並結合 MCP Server 或桌面外掛程式(Desktop extension, e.g. DXT),可快速測試工具。
- 檢驗 Agent 設計:詳細記錄 Agent 使用工具的情形,包含呼叫次數、錯誤、token 用量等指標;測試時,讓 Agent「在工具使用之前」輸出各種思考過程(chain-of-thought, CoT),藉此可以識別 Agent 如何理解目前既有的工具、檢驗是否在工具的描述上存在不足,並反覆改良。
- 高效工具設計原則:選對工具且精簡功能數量以降低 Agent 決策混亂、明確命名降低工具混淆、回傳有意義的上下文資訊、 持續優化工具輸出節省 token (有效率地使用)。
Okay,摘要完畢,接著我們來好好閱讀這篇文章吧!
MCP 讓 Agent 可以串接與管理大量工具,讓 Agent 能自動完成各種需求(如查詢、排程、資料處理等複雜任務),但能夠串很多 API 不代表 Agent 真的會高效率且正確地用好每個工具,工具本身的設計與整合扮演非常關鍵的角色。
因此,「好好使用『工具』」是一件超級無敵重要的事,正文開始。
什麼是工具
傳統系統(deterministic system)是「確定型」(deterministic)的概念,也就是說,給定一組輸入,結果永遠一樣。例如 getWeather("NYC") 這個函式,每次呼叫都會用同樣的方式取得紐約天氣。
然而,Agent 並不同,它是屬於「不確定型」(non-deterministic)概念,即使輸入相同,有時也可能產生不一樣的結果,像 LLM 會根據上下文、隨機性,有不同回應策略。
Agent 會根據任務需要「選擇」用或不用某個工具、可能順序不一,甚至有時誤用、亂用、或未調用。舉例而言,使用者若詢問「我今天要帶傘嗎?」AI Agent 可以:
- 呼叫 weather 工具查天氣、
- 直接用背景知識回答、
- 先反問用戶你的位置是?
- 甚至可能「胡扯」或理解錯題意。
傳統 API/函式設計者總預期「程式一定這麼跑」,但設計給 Agent 的工具要預期 Agent 可能會「奇怪地用」或偶爾用錯!這也是設計工具時需要轉變思維之處。
工具的目的,是「拓寬」Agent 可以解決問題的範圍與「策略空間」──能讓 Agent 有更多種、不同但合理的解題方法。 「最適合代理人的工具」通常也容易讓人類理解和使用(即語意清楚、介面直觀)。
如何規劃工具(Tools)
建立 Prototype
- 先快速實作一版工具原型(prototype):不要等所有規格定完才正式開發,先建立一個基本可運行的版本。
- 可使用 Claude Code 這類 AI 寫程式工具來「協助撰寫程式、API 化」,如果用一次性 prompt(one-shot)就能產生初步可運行工具更好。
Anthropic 團隊認為 Claude Code 表現相當優秀!
- 給 Claude 相關說明文件(例如 MCP SDK 的文件、或各自 API 的 llms.txt 描述檔),可讓其更正確理解、使用這些函式或包裝。
- 可直接使用桌面版 Claude 或 MCP Server 直接快速實測。
如何評估工具好壞
讓 LLM 幫你自動生成測試題目、產生分析報告、指出錯在哪裡,甚至歸納哪類 prompt/功能易失誤、Agent 哪裡亂用或漏用工具,這樣節省人力、加速優化循環。Anthropics 提供 Cookbook 給大家參考(內容會收集正確率、每題耗時、工具使用次數統計等)。
- 產生測試任務(Generating evaluation tasks)
- 從真實世界出發:用實際業務需求(而不是人為簡化的小範例)來出題,讓工具面對「夠難」的問題。好的任務如「安排會議+附加文件+訂會議室」、「日誌問題追蹤+篩查是否還有其他受害客戶」、「用戶流失請 agent 綜合分析原因與對策」,不好的任務可能太單一、過於工程化,無法測 agent 完整決策能力,如「只查找某個 email」、「只搜尋某關鍵字」、「只找某個表單」
- 設計驗證方法(Generating evaluation tasks)
- 每個 prompt-response 都需有「可驗證」結果,方便自動化比較。
- 可以是驗證簡單的相等字串,也可以讓 Agent 自身給出評判
- 避免過於死板的比對規則(格式、標點、措辭不同而被錯誤判失敗)
- 可另外標註「預期 agent 該用哪些工具」來檢查 Agent 對工具理解度,但要注意可能有多種解法,所以不要把策略「綁死」。
- 執行評測(Running the evaluation)
- 建議自動化運行:不要人工操作執行測試,提高自動化可能性,如 while-loop 包裹 Agent 的 API 呼叫和工具呼叫,一題一輪次。每次丟進去一個任務的 prompt 和你的工具清單。
- 評測時 agent 系統 prompt 設計
- 請 Agent 除了 output 回答本身外,也給出「推理與反饋區塊」,理想流程是「 CoT——先輸出理由/計劃,再開始依序呼叫工具,最後合成回答」。
- 若使用 Claude,可開啟 interleaved thinking,方便觀察 Agent 具體決策步驟。
- 統計多元評估數據
- 準確率(問題成功解決率)
- 工具調用次數、token消耗量、每工具/任務的執行時間和錯誤率……
- 這些指標有助於找出瓶頸、重複步驟、設計不佳之處。
- 追蹤結果
- Agent 在工具設計與實作過程中需注意(團隊再次強調),「沒說的部分往往比說出來的還重要。」大語言模型不一定完全表達它的真實意圖。
- 觀察 Agent 何時卡住或困惑,仔細閱讀評估代理人的推理與回饋(如 chain-of-thought),找出設計上的瑕疵。
- 檢查原始使用過程(transcripts,包括所有工具呼叫與回應),發現行為模式與潛在問題,尤其是那些代理人在檢查理由時沒描述到但實際出現的狀況。換句話說,「要讀行間之意」,因為評估代理人未必知道正確答案或最佳策略。
- 要分析工具呼叫數據(metrics):如果出現大量重複呼叫,可能需要調整分頁(pagination)或 token 限制參數;如果有很多因參數錯誤導致的工具錯誤,可能是工具描述太不清楚或缺乏好範例。
如何設計有用的工具
給 Agent 設計一個合適的工具
請為 Agent 量身定作工具。常見錯誤是直接包裝既有軟體功能或 API,但 agent 和傳統軟體有不同的行動特性(affordance),這會影響工具設計。例如 Agent 處理資訊有 context 限制,因此如果像傳統程式一筆筆檢查通訊錄去設計 Agent,可能使得 LLM 會浪費許多 context 空間,導致效率低下。正確方式是像人類查找資料一樣,先跳到可能相關的區塊而非逐行搜尋。
Anthropics 建議設計「少量針對需求量高的」工具,並逐步延伸。像以「通訊錄工具」為例,應該設計 search_contacts 或 message_contact 而不是單純 list_contacts。
工具也能整合多步驟功能、一併處理相關操作並回傳更有用的資訊,例如 schedule_event 工具同時查詢時程空檔及建立活動,search_logs 工具只回傳有意義的日誌片段,get_customer_context 工具一次彙整所有客戶重要資訊。
不過,選擇合適的 AI agent 工具時,工具數量並非越多越好。
每個工具都要明確獨立、能幫助 agent 有效分解和解決任務,同時減少中間資訊耗用 context 的風險。工具重疊或過多,反而會干擾 agent 的判斷與執行策略,因此慎選、少量且精準的工具設計有助於提升 agent 的效率與效能。
良好的「工具命名」
隨著 AI agents 可能存取數十個 MCP 和上百種不同工具(包含第三方開發者提供的工具),如果工具功能重疊或用途不明確,Agent 會混淆該選用哪個工具。
透過命名空間(Namespacing,把相關工具用共同字首分組),可以清楚劃分工具界線。例如,可以依服務把工具命名為 asana_search、jira_search(*_search),或依資源命名為 asana_projects_search、asana_users_search(asana_*),選擇用字首或字尾分組,對工具使用行為有顯著影響,這種命名規劃還能降低 agent 必須載入的工具/描述數量,把原本需在 agent 內部 context 處理的計算轉移到工具本身,降低 agent 出錯風險,提高工作效率。
從工具輸出中留下「對 AI 理解有用的內容」給 Agent,優化 context token 數量
工具回傳內容時,應該優先提供「具情境連結的資訊」給 agent,不應以追求靈活性或技術細節為主。例如 uuid、256px_image_url、mime_type 等,應避免這類技術型欄位,像 name、image_url、file_type 這類人類語意清楚的資訊才真正幫助 agent 做正確判斷和決策,Agent 對自然語言命名、詞語或識別符更容易理解。
編按:雖然乍看之下有點沒意義,但我覺得在實作上,很常為求簡便,就直接把工具輸出直接交給 Agent 理解,這樣會浪費掉很多 context windows 也可能讓 Agent 理解錯誤。
下方 Anthropics 提供兩個「詳細版」與「精簡版」的範例,分別耗費 206 tokens 和 72 tokens,但達成目的幾乎一致:
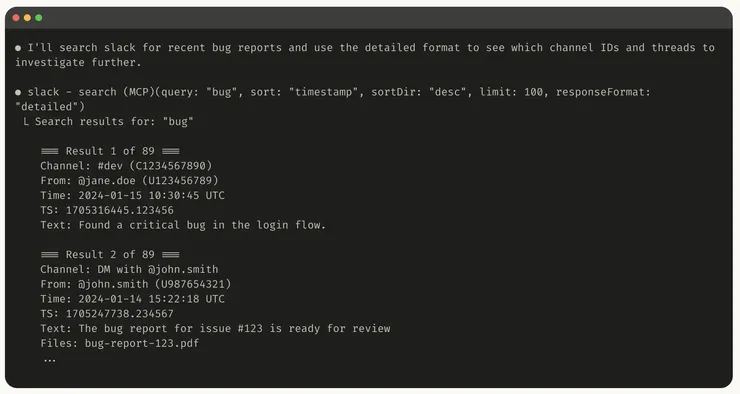
詳細版
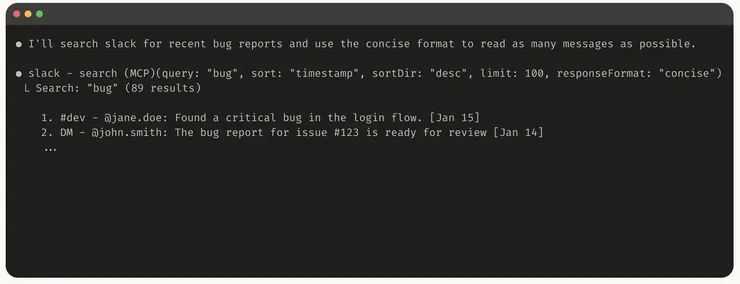
精簡版
優化 context 品質很重要,但也要重視工具回應給 agent 的「context 數量」是否有效率。建議所有可能消耗大量 context 的工具回應,都應結合分頁、範圍選取、過濾及截斷等機制,並設定合適的預設參數。像 Claude Code 預設就把工具回應限制在 25,000 tokens 以內,未來 agent 的 context 能力可能會提升,但「節省 context」的工具設計仍然十分重要。
如果你決定截斷工具回應,也必須用清楚指令引導 agent。例如,可以鼓勵 agent 以多次、小範圍查詢取代一次廣泛查詢,這樣更節省 token。若工具呼叫產生錯誤(如輸入驗證失敗),建議錯誤訊息要明確指示 agent 如何改進,而不是只給模糊的錯誤碼或程式 trace,這樣 agent 才能有效修正行為。
進行「提示工程」優化你的工具描述
撰寫工具描述和規格時,可以想像你要向新進同事介紹這個工具——需要將你腦中預設的操作方式、專用查詢格式、術語定義、資源關係更全面的展開,避免模糊空間的存在。
- 必須提供非常詳細的描述,說明工具用途、適用時機或不應使用時機、每個參數的意義與行為影響,以及任何重要限制或例外,尤其是工具名稱不明確時,必須補充說明。
- 詳細的描述有助於Claude判斷如何與何時使用工具,建議每個工具描述至少3-4句以上(複雜工具則更多)。
- 描述優先於範例。可以在補充完描述後再加入用法範例,但最重要的是清楚完整地解釋工具目的和參數。(上述列點參考此)
結語
未來,如果要打造高效率的 Agent 工具,必須改變傳統以「確定性、可預測」為主的軟體開發思維,轉向能應對「非確定性」需求。
Anthropics 在本文中,透過持續迭代、以評估為核心的流程,發現好的工具具有四個特點:
- 定義明確且有意圖(purposeful and clear)
- 充分且有策略地利用Agent 的 context
- 能靈活組合進各種工作流
- 讓 Agent 能直覺地解決真實世界任務
未來 Agent 與外界互動的方式(比如 MCP protocol 或 LLM 本身)都會持續進化。只要持續以系統化、以評估為核心的方法改良 agent 工具,工具也能和 agent 的能力一同成長進化。
查看全文請看:






























