我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
回顧 AI說書 - 從0開始 - 129 中說,Bidirectional Encoder Representations from Transformers (BERT) 的訓練分為兩種,分別為:
- Masked Language Modeling (MLM)
- Next Sentence Prediction (NSP)
今天來介紹 Masked Language Modeling (MLM) 的核心想法,一樣舉句子「The cat sat on it because it was a nice rug」為例,在 Decoder 模式中,當我預測「it」這個字的時候,我需要把它後面的字掩蓋起來,因為不可以偷看未來的答案,句子會變成 「The cat sat on it <masked sequence>」,但是 BERT 的 Encoder 也會做掩蓋這動作,差別為它是隨機掩蓋,亦即句子有可能變成「The cat sat on it [MASK] it was a nice rug」
上述思想其實就是以克漏字為靈感,在任意段落中進行挖空,模型利用挖空的前後文來預測挖空部分應該填入的文字,實際運行上就是把最後一層的 Encoder 輸出向量餵進去一個 Classification Layer 並且轉換成與字典一樣大小的維度,再經過 Softmax 去看哪個維度的詞彙機率值最高,就取那個字為預測字,最後將預測結果與正確答案比對計算Cross Entropy Loss,將模型進行更新,圖示化呈現為:
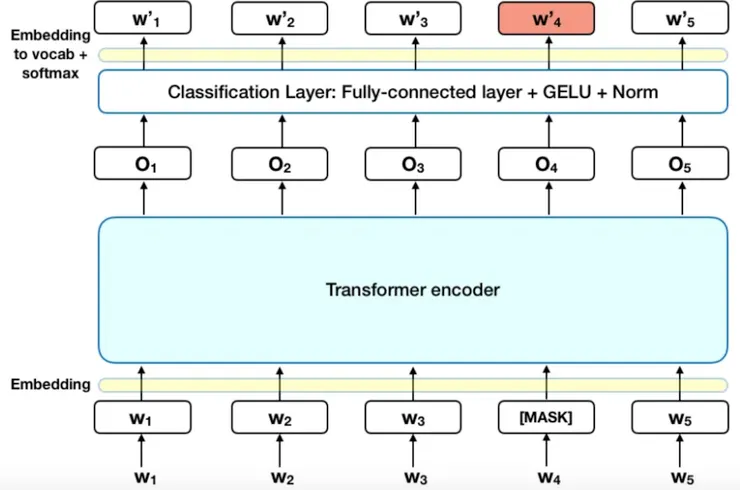
這邊會有一個問題是 Pre-Train 和 Fine-Tune 的不匹配 ,因為在 Fine-Tune 時,並不會像 Pre-Train 有 [MASK] 這樣的東西出現,此時,作者加入一些雜訊 (防止 Overfitting) 的概念來解決這樣的問題,其中 80% 就維持原先的 [MASK],有 10% 改成用隨機的文字取代,最後 10% 則是維持原先沒有被 [MASK] 的 Token,例子如下:
- 10% 維持不變:The cat sat on it [because] it was a nice rug
- 10% 變成隨機:The cat sat on it [often] it was a nice rug
- 80% 維持掩蓋:The cat sat on it [Mask] it was a nice rug


















