這是去年在PHUSE社群貢獻的成果,最後沒被採用,但有被其中一位計畫主持人借去上課,應該是Johns Hopkins University的健康資料課程。
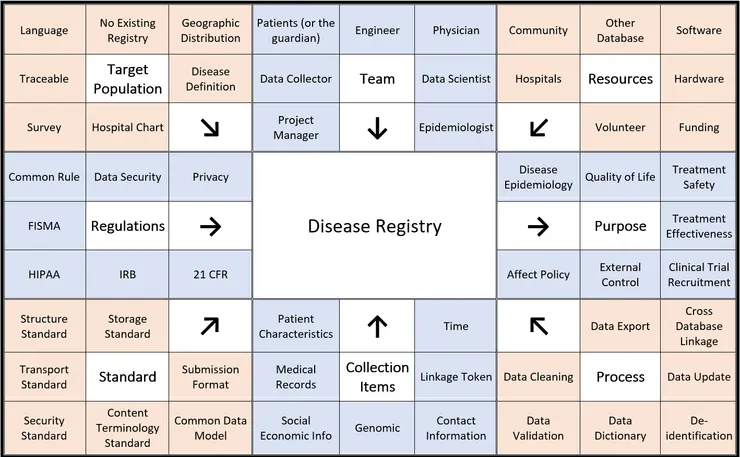
基本上這是個規劃疾病登錄應注意事項的重點摘要:從右上方的Resources開始逆時針看,要建立疾病登錄所需要的資源、團隊、考慮病人的特徵、須遵守的規範 (這邊以美國為例,各國需求不同)、要遵循的各種標準、要蒐集甚麼資料、要怎麼處理資料,最後則是資料可以怎麼應用。每個步驟再舉了七個例子,但不會只有這七個。以下則是我當初寫的說明文件:
--
Here are some concerns with regard to collecting data related to setting up a rare disease registry. A number of concerns must be addressed in a counterclockwise order of the matrix: resources, team, target population, regulation, standards, collection of items, and process. After database established, the data could be analyzed for different purpose. This is a summary matrix that is not very detailed. It’s not an encyclopedia, it is an index. We hope patient groups could have a good starting point and cooperate with professionals.
RESOURCES
Every project requires money. Even though we may have some volunteers on staff, we will need funding for hardware and software. In some cases, accessing the data or even data itself from another health database could be a part of funding. Meanwhile, we will need the cooperation of hospitals and communities in order to identify and collect patient information.
TEAM
The top block addresses which people should be on the team. While physicians may know the patients well, you need epidemiologists and data scientists to help understand the data. The registry system needs engineers to build and maintain. Data would be collected from patients or their family, but there must be someone do the work. A project manager is also necessary if we are looking at a long-term project.
TARGET POPULATION
Target population requires a disease definition first. We need to consider geographic distribution in terms of whether this data collection is local, national, or global. It should be considered whether there is an existing registry. If there is an existing registry, you may wish to join forces. The language of the target population should be also considered as some diseases are more prevalent among certain races. You may be assisted by surveys and hospital charts. If there is a higher incidence in a specific physician’s practice, you may wish to reach out to that physician to assist you in obtaining data.
REGULATIONS
Any data related to personal information needs to consider about the privacy and the data security issues. Every data collection effort is controlled by various rules and regulations such as Common Rule and FISMA. Common rule protects personal identification FISMA refers to the federal information security management act. Data collection for a disease registry does not apply to HIPAA and IRB, but they would be necessary while the data transferring to another researcher. If the data will be used in FDA-regulated food or drug, or HHS-regulated study, 21 CFR should be followed.
STANDARDS
Standards refer to how we describe things. How data would be storage, what is the data structure, and what is the communication protocol for data transport/exchange between devices, these all have standards. Data security standard is regulated under guidelines such as HIPAA. Terminology standards are the coding system we use to describe the diagnosis, medicine, surgery, procedure, etc. If we want to use the data for different purpose and need to cooperate with other researchers, common data model would be helpful. If the data will be used for new drug application, there are some submission formats for FDA.
COLLECTION ITEMS
We need basic information such as sex/gender and birthdate. Some risk factors related to many comorbidities such as smoking status or BMI would be good to have. Medical records would be the cord of the registry, including diagnosis and treatment. Sometimes, socioeconomic information is valuable, but may be somewhat difficult to obtain; this information can be inferred from zip code or insurance status. Genomic data refers to genetic information, which is often a factor in rare diseases. This information, however, is difficult to obtain because it may not be in the patient file, but rather in some hospital files or biobank files. Contact information is how we would provide follow-up to a patient. A linkage token can help to link one set of data to another. It is usually a serial number or an encrypted social security number. When the data is used, this identifying information will be deidentified. The most important factor in a dataset is time. All entries should be accompanied by a date. Without references to time, the information would be useless.
PROCESS
When we consider the data process, we need to look at what we need to do in order to analyze the data. First, we need to clean the data in order to remove/correct data that has been misfiled. Data validation could provide the data quality information to the data user. For convenience, we need to consider creating a data dictionary, and we will see the format and expressions used to identify the data. An updatable database is more valuable than a fixed data. If we want to link the registry database to another database such as claims data, a process of re-identification, third-party linkage and de-identification would be required. We also need to consider whether the data is exportable or analyzed on-site. It’s about the balance between data protection and using convenience.
PURPOSE
Here we talk about the purpose of the data, so the direction of the arrow is opposite. These are how and where the information could be used. It can provide basic epidemiology of the disease, describe the patients in population level, and evaluate the safety and effectiveness of the treatment. For drug development, a registry data can provide the insight of patient distribution, or even as an external control of the clinical trial. Some information might affect the policy of health or social benefit. Afterall, we hope the registry data could improve patients’ life.


























