
📢 NVIDIA($NVDA-US)在推出Blackwell系列的B200與GB200僅半年後,迅速推出全新升級版的B300與GB300,這次升級不僅是性能提升(尤其針對AI推論模型進行性能優化),更是一場供應鏈的變革,其中也產生供應鏈中股票的受惠者、受害者。
✨ 性能升級
1. 性能提升:B300基於台積電半導體4NP製程,提供比B200高出50%的算力FLOPS,為此,B300的TDP提升至1.2KW、GB300的TDP增加至1.4KW。除了功耗增加以外,B300與GB300的其餘性能提升則來自於架構的優化與系統級增強,如CPU與GPU之間的動態功率分配技術。
2. 記憶體升級:B300、GB300採用了12層HBM3E記憶體,相較於B200的8層大幅提升,每顆GPU的HBM容量達到288GB,不過記憶體針腳速度不變,因此頻寬仍為8TB/s。
✨ 為AI推論模型量身打造的硬體架構
1. 推論性能優化:此次升級專注於解決推論模型中的KV Cache限制問題,也就是隨著序列長度的增加,批量處理大小與延遲成為推論模型的瓶頸。因此,GPU VRAM容量提升對於OpenAI O3這類大模型的推論與訓練至關重要。
2. 效益提升:參考H200的測試數據,H200相較H100在推論性能上提升了43%,而每秒生成的tokens數量提升了3倍。同時,由於更高的批量處理能力,整體成本降低了約3倍,這使得H200在性能與經濟效益方面都具備了極大的優勢,應可期待B系列晶片達成一樣或更高的效益提升。
3. NVLink技術突破:相對ASICs、AMD GPU等競爭對手,NVIDIA($NVDA-US)的NVL72技術允許多達72個GPU進行超低延遲、高速互連的協同運算,並且能夠在大型推論任務中共享記憶體,這在長序列推論任務中尤為重要,使得每個GPU的經濟效益提高了10倍以上,競爭對手僅能依稀窺見NVLink的車尾燈。
✨ 供應鏈變革、ODM模式轉變
1. HBM:三星(005930.KS)無法取得HBM供應資格,至少在未來9個月內無法進入B300 or GB300供應鏈,顯示SK海力士(000660.KS)、美光($MU-US)將成為主要受益者。
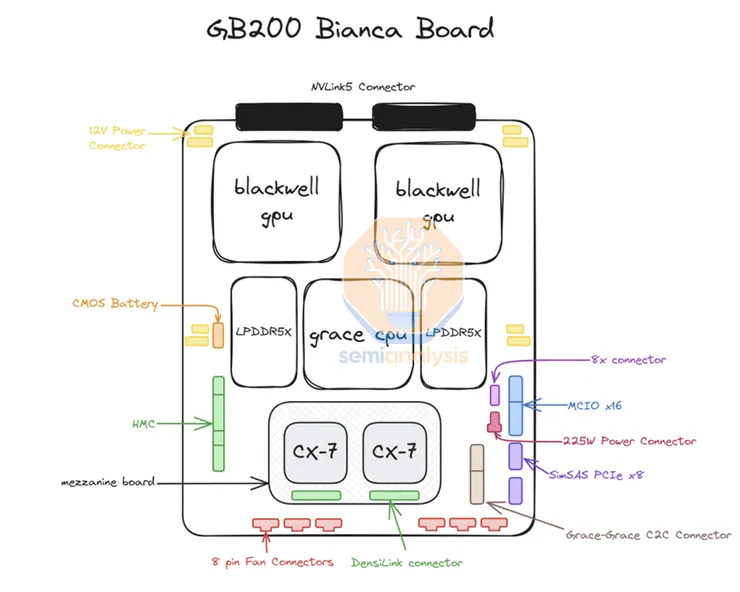
2. HMC:B300/GB300選擇Axiado(新創)取代信驊(5274 TT)作為供應商。
3. VRM:由於主要的VRM模組由雲端巨頭與OEM直接採購,原有的供應商如Monolithic Power Systems($MPWR-US)市場份額大幅縮減。
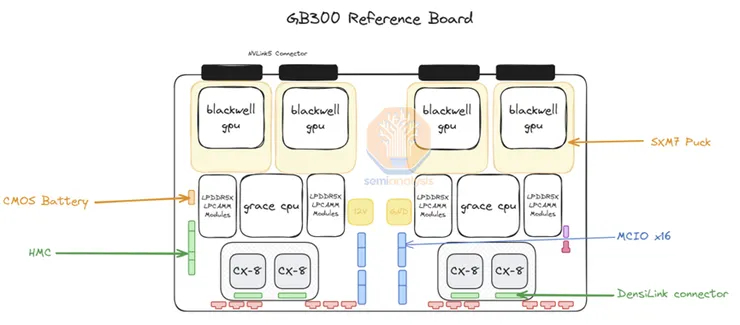
4. 伺服器ODM/OEM:與GB200不同,NVIDIA($NVDA-US)在GB300中僅供應核心模組(B300、Grace CPU和HMC控制器),其他零組件由終端客戶自行採購,這使得OEM與ODM的參與範圍更加廣泛,也讓原先主導Bianca主板的緯創(3231 TT)失去market share,而鴻海FII則憑藉獨家生產SXM Puck模組的優勢,在市場中占據新的主導地位。
✨ 雲端巨頭的戰略調整
1. 訂單轉向:由於GB200的上市延遲,及因為GB300提供了更高的性能與更大的設計自由度,Hyperscalers有轉向採用GB300方案的狀況。
2. Amazon($AMZN-US)策略變更:放棄自研網卡方案,轉而採用NVIDIA($NVDA-US)的解決方案,並計劃在未來引入更多自主設計的主板與散熱系統。
✨ 價格與毛利分析
1. 成本與價格:GB300的ASP比GB200高出約4000美元,其中HBM記憶體升級成本增加約2500美元。然而,NVIDIA($NVDA-US)通過削減部分組件供應(如LPDDR5X記憶體與PCB),抵消了大部分成本上升的壓力。
2. 毛利率穩定:儘管GB300的物料成本增加,但由於銷售價格大幅提升,其毛利率仍可達到73%(與GB200持平),顯示出其定價與成本控制方面的成功策略。
🔎 懶人包:NVIDIA下一代AI晶片B300/GB300供應鏈變革下的股票受害/受惠者
1. 受害者:緯創(3231 TT)、信驊(5274 TT)、三星(005930.KS)、Monolithic Power Systems($MPWR-US)
2. 影響小:鴻海FII(601138.SS),和緯創一樣流失Bianca主板訂單,但獲得SXM Puck模組與插座的獨家供應權,能在一定程度上彌補流失影響。
3. 受惠者:Axiado(新創)、SK海力士(000660.KS)、美光($MU-US)、ODM/OEM
參考資料
⚠️ 附註:所有資訊內容均僅供參考,不涉及買賣投資之依據。使用者在進行投資決策時,務必自行審慎評估,並自負投資風險及盈虧。


























