# [已修改] 函式名稱: audit_weekly_high_consistency
def audit_weekly_high_consistency(market_key: str, week_path: str):
"""
[🌟 修正路徑] QA 稽核路徑:改為讀取本地快取。
"""
qa_dir = Path(f"{DRIVE_BASE}/{market_key}/_qa"); qa_dir.mkdir(parents=True, exist_ok=True)
if not Path(week_path).exists():
(qa_dir / "weekly_high_mismatch.csv").write_text("", encoding="utf-8-sig")
print("❌ QA: 找不到週K Parquet,跳過週高一致性。")
return
dfw = pd.read_parquet(week_path).copy()
dfw['日期'] = pd.to_datetime(dfw['日期'], errors='coerce').dt.tz_localize(None)
dfw = dfw[(dfw['日期'] >= DATE_START) & (dfw['日期'] <= DATE_END)]
# 🌟 關鍵修正:從 Drive 路徑改為本地快取路徑
local_dayk_dir = Path(f"{LOCAL_DAYK_CACHE}/{market_key}")
day_cache = {}
for f in local_dayk_dir.glob("*.csv"): # 從本地快取讀取
sid = f.stem.split("_")[0]
try:
d = _read_csv_fast(str(f))
dc = _pick(d, DATE_COLS); hc = _pick(d, HIGH_COLS)
d = d.rename(columns={dc:'日期', hc:'最高'})
d['日期'] = pd.to_datetime(d['日期'], errors='coerce').dt.tz_localize(None)
d = d.dropna(subset=['日期','最高']).sort_values('日期')
d = d[(d['日期'] >= DATE_PAD_START) & (d['日期'] <= DATE_END)]
day_cache[sid] = d[['日期','最高']]
except:
pass
bad = []
for sid, g in dfw.groupby('StockID'):
d = day_cache.get(sid)
if d is None:
continue
for _, r in g.iterrows():
iso = d['日期'].dt.isocalendar()
wk = r.get('ISO_Week')
mask = (iso.year.astype(str) + '-' + iso.week.astype(str).str.zfill(2)) == wk
if not mask.any():
continue
week_max = float(d.loc[mask, '最高'].max())
if np.isfinite(week_max) and np.isfinite(r['最高']) and abs(week_max - r['最高']) > 1e-6:
bad.append({'StockID': sid, 'ISO_Week': wk, '週末日': r['日期'], '週高(weekK)': float(r['最高']), '日高max(week)': week_max, '差額': float(r['最高'] - week_max)})
pd.DataFrame(bad).to_csv(qa_dir / "weekly_high_mismatch.csv", index=False, encoding='utf-8-sig')
print(f"🧪 QA 週高一致性完成 → {qa_dir/'weekly_high_mismatch.csv'}")
def audit_weekly_high_tail(market_key: str, week_path: str):
# ... (函式內容保持不變) ...
qa_dir = Path(f"{DRIVE_BASE}/{market_key}/_qa"); qa_dir.mkdir(parents=True, exist_ok=True)
if not Path(week_path).exists():
(qa_dir / "weekly_distribution_summary_high.csv").write_text("", encoding='utf-8-sig')
(qa_dir / "weekly_top_outliers_high.csv").write_text("", encoding='utf-8-sig')
print("❌ QA: 找不到週K Parquet,跳過週高分布/厚尾。")
return
dfw = pd.read_parquet(week_path).copy()
dfw['日期'] = pd.to_datetime(dfw['日期'], errors='coerce').dt.tz_localize(None)
dfw = dfw[(dfw['日期'] >= DATE_START) & (dfw['日期'] <= DATE_END)]
edges, labels = _week_bins()
wk = dfw[['ISO_Week','StockID','日期','PrevC_W','最高','Ret_Max_H_W']].dropna(subset=['Ret_Max_H_W']).copy()
wk['ret_pct'] = (wk['Ret_Max_H_W'] * 100).astype('float64')
wk['bin'] = pd.cut(wk['ret_pct'], bins=edges, labels=labels, right=False)
dist = wk.pivot_table(index='ISO_Week', columns='bin', values='StockID', aggfunc='count', fill_value=0)
dist = dist.div(dist.sum(axis=1).replace(0, np.nan), axis=0)
dist.sort_index().to_csv(qa_dir / "weekly_distribution_summary_high.csv", encoding='utf-8-sig')
tail_bins = ['100~200%', '200~1000%', '1000~10000%', '-1000~-200%', '-200~-100%']
outliers = wk[wk['bin'].isin(tail_bins)].copy()
outliers['abs_z'] = outliers.groupby('ISO_Week')['ret_pct'].transform(lambda s: (s - s.mean()) / (s.std(ddof=1) if s.std(ddof=1) else np.nan)).abs()
outliers['abs_z_rank'] = outliers.groupby('ISO_Week')['abs_z'].rank(ascending=False, method='first')
outliers.sort_values(['ISO_Week','abs_z_rank']).groupby('ISO_Week').head(200)[['ISO_Week','日期','StockID','ret_pct','abs_z','bin']].to_csv(qa_dir / "weekly_top_outliers_high.csv", index=False, encoding='utf-8-sig')
print(f"🧪 QA 週高分布/厚尾完成 → {qa_dir/'weekly_distribution_summary_high.csv'}, {qa_dir/'weekly_top_outliers_high.csv'}")
# [***新增 QA 函式 5***] 統計週 K 的 NaN 過濾數量 (補充週 K 統計報告)
def audit_weekly_nan_filter(market_key: str, week_path: str):
print("\n📊 週 K 過濾統計摘要:")
if not Path(week_path).exists():
print(" ❌ 週 K: Parquet 檔案不存在,無法統計過濾數量。")
return
try:
# 只讀取 StockID 和 Ret_Trad_W 欄位
dfw = pd.read_parquet(week_path, columns=['StockID', 'Ret_Trad_W'])
# 統計 Ret_Trad_W 為 NaN 的行 (即被過濾的行)
filtered_mask = dfw['Ret_Trad_W'].isna()
df_filtered = dfw[filtered_mask].copy()
total_filtered_rows = len(df_filtered)
total_filtered_stocks = df_filtered['StockID'].nunique()
if total_filtered_rows > 0:
# 輸出詳細清單到 QA 資料夾
qa_dir = Path(f"{DRIVE_BASE}/{market_key}/_qa"); qa_dir.mkdir(parents=True, exist_ok=True)
summary_df = df_filtered.groupby('StockID').size().reset_index(name='Filtered_Count')
summary_df.sort_values('Filtered_Count', ascending=False, inplace=True)
summary_path = qa_dir / f"weekly_nan_filtered_summary.csv"
summary_df.to_csv(summary_path, index=False, encoding='utf-8-sig')
print(f" ✅ 週 K: 共 {total_filtered_rows} 筆報酬被過濾為 NaN (涉及 {total_filtered_stocks} 檔股票)。")
print(f" 📜 過濾清單儲存至: {summary_path}")
else:
print(f" ✅ 週 K: 沒有報酬被過濾為 NaN。")
except Exception as e:
print(f" ⚠️ 讀取/統計 週 K 檔案失敗: {e}")
# [***修正後的 QA 函式 4***] 讀取 M/Y Parquet 並統計過濾數量
def audit_monthly_yearly_filter(market_key: str, month_path: str, year_path: str):
print("\n📊 月/年 K 過濾統計摘要:")
def _report(path, freq_name_cn, freq_name_en):
if not Path(path).exists():
print(f" ❌ {freq_name_cn} K: Parquet 檔案不存在,無法統計過濾數量。")
return
try:
# 只讀取 StockID 和 IsFiltered_QA 欄位以節省記憶體
df = pd.read_parquet(path, columns=['StockID', 'IsFiltered_QA'])
df = df[df['IsFiltered_QA'] == 1]
total_filtered_rows = len(df)
total_filtered_stocks = df['StockID'].nunique()
if total_filtered_rows > 0:
# 輸出詳細清單到 QA 資料夾
qa_dir = Path(f"{DRIVE_BASE}/{market_key}/_qa"); qa_dir.mkdir(parents=True, exist_ok=True)
summary_df = df.groupby('StockID').size().reset_index(name='Filtered_Count')
summary_df.sort_values('Filtered_Count', ascending=False, inplace=True)
summary_path = qa_dir / f"{freq_name_en}_filtered_summary.csv"
summary_df.to_csv(summary_path, index=False, encoding='utf-8-sig')
print(f" ✅ {freq_name_cn} K: 共 {total_filtered_rows} 筆報酬被過濾 (涉及 {total_filtered_stocks} 檔股票)。")
print(f" 📜 過濾清單儲存至: {summary_path}")
else:
print(f" ✅ {freq_name_cn} K: 沒有報酬被過濾。")
except Exception as e:
print(f" ⚠️ 讀取/統計 {freq_name_cn} K 檔案失敗: {e}")
_report(month_path, '月', 'monthly')
_report(year_path, '年', 'yearly')
# --------------------------------------------------------------------------------
# Colab Cell 5: 主流程執行 (Part 5)
# --------------------------------------------------------------------------------
if __name__ == "__main__":
print(f"⏳ 僅處理期間:{DATE_START_STR} ~ {DATE_END_STR}(含起始緩衝 {PAD_DAYS} 天)")
print(f"⚠️ 月K/年K 報酬過濾已啟用:小於 {MIN_DAYS_MONTH} / {MIN_DAYS_YEAR} 交易日,或遇停牌/極端跳空報酬,該期報酬將被設為 NaN。")
print(f"🛠️ [時區修正已啟用] 修正月份邊界錯誤(如 9/1 誤算進 8 月)。")
for MK in MARKET_LIST:
print(f"\n{'='*20} 處理市場:{MK}(W-FRI + 玩股口徑 + 本地快取 + 7 QA) {'='*20}")
# 1. 生成新的 Parquet 檔案
w, m, y = build_wmy_parquets(MK)
if w:
# 2. 運行週 K QA
audit_weekly_parquet(MK, w) # 收盤對收盤:分箱/漂移/厚尾
audit_weekly_vs_daily(MK) # 週 vs 日 幾何連乘
audit_weekly_high_consistency(MK, w) # 週高一致性(weekK 高 vs 週內日高 max)
audit_weekly_high_tail(MK, w) # 週高相對上週收的分布/厚尾
# 3. 新增 週 K 過濾統計 (基於 Ret_Trad_W = NaN)
audit_weekly_nan_filter(MK, w)
# 4. 新增 月/年 K 過濾統計 (基於 IsFiltered_QA)
audit_monthly_yearly_filter(MK, m, y)
qa_dir = Path(f"{DRIVE_BASE}/{MK}/_qa")
if qa_dir.exists():
print("\n🌟 QA 報表輸出確認:")
for filename in [
"skip_pingpong.csv",
"weekly_distribution_summary.csv",
"weekly_drift_alerts.csv",
"weekly_top_outliers.csv",
"weekly_vs_daily_diff.csv",
"weekly_high_mismatch.csv",
"weekly_distribution_summary_high.csv",
"weekly_top_outliers_high.csv",
"monthly_filtered_summary.csv",
"yearly_filtered_summary.csv",
"weekly_nan_filtered_summary.csv", # <-- 新增週 K 清單
]:
f = qa_dir / filename
status = "✅" if f.exists() and f.stat().st_size > 0 else ("✅ (空表)" if f.exists() else "❌")
print(f" {status} {filename}")
else:
print("\n⚠️ 找不到 QA 資料夾,請檢查 DRIVE_BASE 設定或寫入權限。")
print(f"\n🗃️ 本地日K快取保留:/content/_wmy_tmp/dayK_cache")
股票數據清洗與日K轉換周月年K工具 - 完整功能解析-4
更新 發佈閱讀 24 分鐘
投資理財內容聲明
留言

《炒股不看周月年K漲幅機率就是耍流氓》
16會員
290內容數
普通上班族,用 AI 與 Python 將炒股量化。我的數據宣言是:《炒股不做量化,都是在耍流氓》。
《炒股不看周月年K漲幅機率就是耍流氓》的其他內容
2025/11/08
# --------------------------------------------------------------------------------
# Colab Cell 4: QA 稽核函式 (Part 4)
# ----------------------------
2025/11/08
# --------------------------------------------------------------------------------
# Colab Cell 4: QA 稽核函式 (Part 4)
# ----------------------------
2025/11/08
因為程式碼太常超過篇幅字數限制所以分段
2025/11/08
因為程式碼太常超過篇幅字數限制所以分段
2025/11/08
📋 程式概述
這是一個企業級股票數據清洗與時間週期轉換系統,專門處理日 K 線數據並轉換為週/月/年 K 線,同時進行多層次的數據品質控管與異常偵測。程式採用玩股網口徑標準,確保數據品質符合量化交易需求。
🎯 核心功能架構
1. 數據來源與處理範圍
時間範圍:2000-01-01
2025/11/08
📋 程式概述
這是一個企業級股票數據清洗與時間週期轉換系統,專門處理日 K 線數據並轉換為週/月/年 K 線,同時進行多層次的數據品質控管與異常偵測。程式採用玩股網口徑標準,確保數據品質符合量化交易需求。
🎯 核心功能架構
1. 數據來源與處理範圍
時間範圍:2000-01-01
#股票 的其他內容




你可能也想看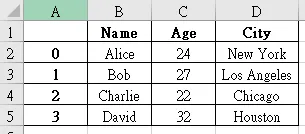
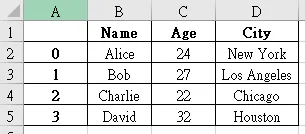










從基本概念開始,然後逐步深入學習 pandas 的各種功能。這是一個非常強大的 Python 資料分析工具,常用於處理結構化數據。
基本概念
pandas 主要有兩個核心資料結構:
Series: 一維的資料結構,類似於 Python 中的列表,但它可以帶有標籤(index)。
DataFr
從基本概念開始,然後逐步深入學習 pandas 的各種功能。這是一個非常強大的 Python 資料分析工具,常用於處理結構化數據。
基本概念
pandas 主要有兩個核心資料結構:
Series: 一維的資料結構,類似於 Python 中的列表,但它可以帶有標籤(index)。
DataFr


這是一場修復文化與重建精神的儀式,觀眾不需要完全看懂《遊林驚夢:巧遇Hagay》,但你能感受心與土地團聚的渴望,也不急著在此處釐清或定義什麼,但你的在場感受,就是一條線索,關於如何找著自己的路徑、自己的聲音。
這是一場修復文化與重建精神的儀式,觀眾不需要完全看懂《遊林驚夢:巧遇Hagay》,但你能感受心與土地團聚的渴望,也不急著在此處釐清或定義什麼,但你的在場感受,就是一條線索,關於如何找著自己的路徑、自己的聲音。


5 月將於臺北表演藝術中心映演的「2026 北藝嚴選」《海妲・蓋柏樂》,由臺灣劇團「晃晃跨幅町」製作,本文將以從舞台符號、聲音與表演調度切入,討論海妲・蓋柏樂在父權社會結構下的困境,並結合榮格心理學與馮.法蘭茲對「阿尼姆斯」與「永恆少年」原型的分析,理解女人何以走向精神性的操控、毀滅與死亡。
5 月將於臺北表演藝術中心映演的「2026 北藝嚴選」《海妲・蓋柏樂》,由臺灣劇團「晃晃跨幅町」製作,本文將以從舞台符號、聲音與表演調度切入,討論海妲・蓋柏樂在父權社會結構下的困境,並結合榮格心理學與馮.法蘭茲對「阿尼姆斯」與「永恆少年」原型的分析,理解女人何以走向精神性的操控、毀滅與死亡。


歡迎來到Scikit-learn教學系列的第二篇文章!在上篇中,我們介紹了Scikit-learn與機器學習基礎,並探索了Iris資料集。這一篇將聚焦於資料預處理,我們將學習如何使用Scikit-learn清理資料、處理缺失值、進行特徵縮放與類別編碼,並以真實資料集進行實作。
歡迎來到Scikit-learn教學系列的第二篇文章!在上篇中,我們介紹了Scikit-learn與機器學習基礎,並探索了Iris資料集。這一篇將聚焦於資料預處理,我們將學習如何使用Scikit-learn清理資料、處理缺失值、進行特徵縮放與類別編碼,並以真實資料集進行實作。


《轉轉生》(Re:INCARNATION)為奈及利亞編舞家庫德斯.奧尼奎庫與 Q 舞團創作的當代舞蹈作品,結合拉各斯街頭節奏、Afrobeat/Afrobeats、以及約魯巴宇宙觀的非線性時間,建構出關於輪迴的「誕生—死亡—重生」儀式結構。本文將從約魯巴哲學概念出發,解析其去殖民的身體政治。
《轉轉生》(Re:INCARNATION)為奈及利亞編舞家庫德斯.奧尼奎庫與 Q 舞團創作的當代舞蹈作品,結合拉各斯街頭節奏、Afrobeat/Afrobeats、以及約魯巴宇宙觀的非線性時間,建構出關於輪迴的「誕生—死亡—重生」儀式結構。本文將從約魯巴哲學概念出發,解析其去殖民的身體政治。


我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言:RoBERTa 預訓練前言
AI說書 - 從0開始 - 181 | 預訓
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言:RoBERTa 預訓練前言
AI說書 - 從0開始 - 181 | 預訓

為了讓資料更適合進行後續的分析、建立模型,模型的決策準確性,資料探索與清理是資料分析過程中非常重要的步驟,主要目的在於確保資料的品質和可靠性。
因為前幾篇的例子中的資料,並沒有缺失值與重複值的部分,我另外找了一份有包含的資料來做案例分析,由於找到的資料沒有重複值的部分,故本文主要解釋處理缺失值的部
為了讓資料更適合進行後續的分析、建立模型,模型的決策準確性,資料探索與清理是資料分析過程中非常重要的步驟,主要目的在於確保資料的品質和可靠性。
因為前幾篇的例子中的資料,並沒有缺失值與重複值的部分,我另外找了一份有包含的資料來做案例分析,由於找到的資料沒有重複值的部分,故本文主要解釋處理缺失值的部


本文分析導演巴里・柯斯基(Barrie Kosky)如何運用極簡的舞臺配置,將布萊希特(Bertolt Brecht)的「疏離效果」轉化為視覺奇觀與黑色幽默,探討《三便士歌劇》在當代劇場中的新詮釋,並藉由舞臺、燈光、服裝、音樂等多方面,分析該作如何在保留批判核心的同時,觸及觀眾的觀看位置與人性幽微。
本文分析導演巴里・柯斯基(Barrie Kosky)如何運用極簡的舞臺配置,將布萊希特(Bertolt Brecht)的「疏離效果」轉化為視覺奇觀與黑色幽默,探討《三便士歌劇》在當代劇場中的新詮釋,並藉由舞臺、燈光、服裝、音樂等多方面,分析該作如何在保留批判核心的同時,觸及觀眾的觀看位置與人性幽微。