NLTK(Natural Language Toolkit)是一個流行的Python套件,專門用於處理自然語言處理(NLP)任務。它提供了各種工具和資源,幫助開發者進行文本分析、語言處理和機器學習等任務。
NLTK 主要專注於英文語言處理,可以使用其他工具庫如 Jieba 來實現中文分詞。以下是一些NLTK的主要特點和功能:
- 文本處理工具:NLTK包含了多種用於標記、分詞、解析和標準化文本的函式和類。這些工具可以幫助你將原始文本轉換成機器可理解和處理的格式。
- 語料庫和資源:NLTK包含了大量的語料庫和資源,涵蓋了不同語言和主題。這些資源可以用來訓練模型、進行研究或開發NLP應用。
- 分析和可視化:NLTK提供了各種分析文本和語言模型的工具。這些工具包括統計分析、語法分析、情感分析等,還可以通過統計圖表和可視化工具展示分析結果。
安裝套件
pip install nltk下載資料包
nltk.download()
nltk.download() 是 NLTK 中用來下載和更新資料庫、資源和語料庫的函式。
Colab上執行步驟,全部下載步驟,d) -> all 。
VScode上執行,選擇all,Download
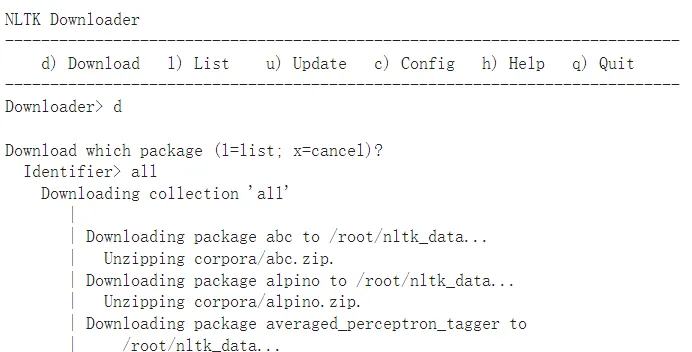
colab上的下載畫面
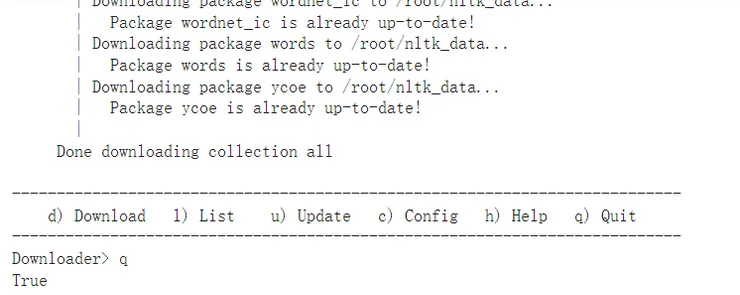
colab上的下載畫面
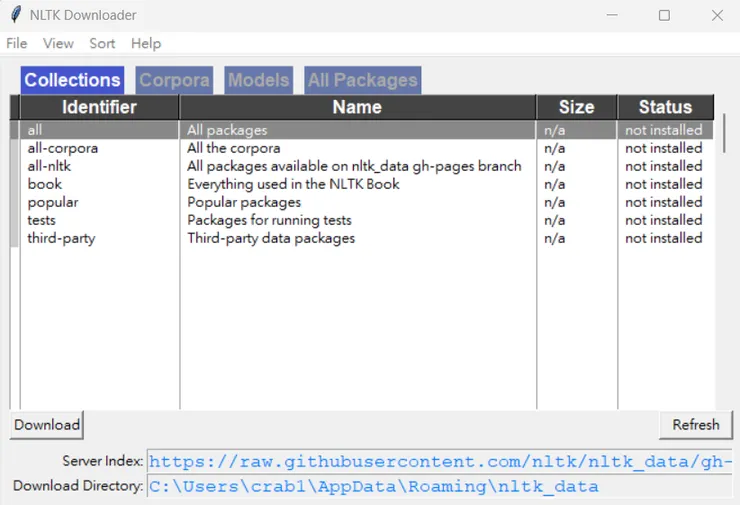
vscode執行畫面
NLTK的簡單應用範例
分詞(Tokenization):
分詞是將文本分割成個別的詞或詞彙的過程。NLTK 提供了各種分詞器,可以根據需要選擇適合的方法。from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
text = "NLTK is a powerful tool for natural language processing." # 原始文本
tokens = word_tokenize(text) # 使用 word_tokenize 函數將文本進行分詞,得到 tokens
print(tokens) # 輸出分詞後的 tokens
輸出:['NLTK', 'is', 'a', 'powerful', 'tool', 'for', 'natural', 'language', 'processing', '.']
text = "NLTK is a powerful tool for natural language processing." # 原始文本
tokens = word_tokenize(text) # 使用 word_tokenize 函數將文本進行分詞,得到 tokens
print(tokens) # 輸出分詞後的 tokens
停用詞移除(Stopwords Removal):
停用詞是在文本處理中常見但通常無意義的詞彙,例如“the”,“is”,“at”等。NLTK 可以幫助去除這些停用詞。from nltk.corpus import stopwords # 引入 NLTK 的停用詞庫模組
from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
text = "NLTK is a powerful tool for natural language processing." # 原始文本
tokens = word_tokenize(text) # 將文本進行分詞,得到 tokens
stopwords_list = set(stopwords.words('english')) # 使用 NLTK 提供的英文停用詞列表
filtered_tokens = [word for word in tokens if word.lower() not in stopwords_list] # 過濾掉文本中的停用詞
print(filtered_tokens) # 輸出過濾後的 tokens
輸出:['NLTK', 'powerful', 'tool', 'natural', 'language', 'processing', '.']
from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
text = "NLTK is a powerful tool for natural language processing." # 原始文本
tokens = word_tokenize(text) # 將文本進行分詞,得到 tokens
stopwords_list = set(stopwords.words('english')) # 使用 NLTK 提供的英文停用詞列表
filtered_tokens = [word for word in tokens if word.lower() not in stopwords_list] # 過濾掉文本中的停用詞
print(filtered_tokens) # 輸出過濾後的 tokens
詞性標註(Part-of-Speech Tagging):
詞性標註是將句子中的每個詞彙標註為其詞性(名詞、動詞、形容詞等)的過程。from nltk import pos_tag # 引入 NLTK 的詞性標註模組
from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
text = "NLTK is a powerful tool for natural language processing." # 原始文本
tokens = word_tokenize(text) # 將文本進行分詞,得到 tokens
pos_tags = pos_tag(tokens) # 對 tokens 進行詞性標註,得到 pos_tags
print(pos_tags) # 輸出詞性標註結果
輸出:[('NLTK', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('powerful', 'JJ'), ('tool', 'NN'), ('for', 'IN'), ('natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('.', '.')]
from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
text = "NLTK is a powerful tool for natural language processing." # 原始文本
tokens = word_tokenize(text) # 將文本進行分詞,得到 tokens
pos_tags = pos_tag(tokens) # 對 tokens 進行詞性標註,得到 pos_tags
print(pos_tags) # 輸出詞性標註結果
- 這些是詞性標註(Part-of-Speech Tagging)過程中的標籤,每個標籤表示了相應詞彙在句子中的詞性(parts of speech)信息。
- 以下是每個詞彙及其對應的詞性標籤:
- 'is' ('VBZ'):
- 'is' 是一個動詞,標記為 VBZ。
- VBZ 表示現在單數第三人稱動詞
- 'a' ('DT'):
- 'a' 是一個冠詞,標記為 DT。
- DT 表示限定詞(determiner),用來指示名詞的特定性或泛指性。
- 'powerful' ('JJ'):
- 'powerful' 是一個形容詞,標記為 JJ。
- JJ 表示形容詞(adjective),用來描述名詞的屬性或特徵。
- 'tool' ('NN'):
- 'tool' 是一個名詞,標記為 NN。
- NN 表示名詞(noun),用來指稱人、事物、地方或概念。
- 'for' ('IN'):
- 'for' 是一個介詞,標記為 IN。
- IN 表示介詞(preposition),用來表達位置、方向、時間、原因等關係。
- 'natural' ('JJ'):
- 'natural' 是一個形容詞,標記為 JJ。
- JJ 同樣表示形容詞,描述名詞的屬性或特徵。
- 'language' ('NN'):
- 'language' 是一個名詞,標記為 NN。
- NN 表示名詞,用來指稱語言。
- 'processing' ('NN'):
- 'processing' 是一個名詞,標記為 NN。
- NN 同樣表示名詞,指稱處理的動作或過程。
- '.' ('.'):
- '.' 是一個句點,標記為 '.'。
- '.' 表示句點,用來結束句子。
這些詞性標註能夠幫助理解每個詞在句子中的語法角色和功能,進而進行更深入的語言分析和處理。
命名實體識別(Named Entity Recognition, NER):
NER 可以識別文本中具有特定意義的命名實體,例如人名、地名、日期等。from nltk import ne_chunk # 引入 NLTK 的命名實體識別模組
from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
from nltk.tag import pos_tag # 引入 NLTK 的詞性標註模組
# 原始文本
text = "Barack Obama was born in Hawaii."
# 將文本進行分詞,得到 tokens
tokens = word_tokenize(text)
# 對 tokens 進行詞性標註,得到 pos_tags
pos_tags = pos_tag(tokens)
# 使用命名實體識別器對 pos_tags 進行命名實體識別,得到 ner_tags
ner_tags = ne_chunk(pos_tags)
# 輸出識別結果
print(ner_tags)
輸出:(S
(PERSON Barack/NNP Obama/NNP)
was/VBD
born/VBN
in/IN
(GPE Hawaii/NNP)
./.)
from nltk.tokenize import word_tokenize # 引入 NLTK 的分詞模組
from nltk.tag import pos_tag # 引入 NLTK 的詞性標註模組
# 原始文本
text = "Barack Obama was born in Hawaii."
# 將文本進行分詞,得到 tokens
tokens = word_tokenize(text)
# 對 tokens 進行詞性標註,得到 pos_tags
pos_tags = pos_tag(tokens)
# 使用命名實體識別器對 pos_tags 進行命名實體識別,得到 ner_tags
ner_tags = ne_chunk(pos_tags)
# 輸出識別結果
print(ner_tags)
(PERSON Barack/NNP Obama/NNP)
was/VBD
born/VBN
in/IN
(GPE Hawaii/NNP)
./.)
- 它使用了一種稱為 IOB(Inside-Outside-Beginning)格式的標註方式來標識文本中的命名實體
- (PERSON Barack/NNP):
- 在這個標註中,'Barack' 被標識為 PERSON,表示這是一個人名。
- NNP 表示 'Barack' 是一個專有名詞,通常代表人名、地名等。
- (PERSON Obama/NNP):
- 同樣地,'Obama' 被標識為 PERSON,表示這也是一個人名。
- was/VBD:
- 'was' 被標識為 VBD,表示過去式動詞。
- born/VBN:
- 'born' 被標識為 VBN,表示過去分詞形式的動詞。
- in/IN:
- 'in' 被標識為 IN,表示這是一個介詞,用來表達位置或方向。
- (GPE Hawaii/NNP):
- 'Hawaii' 被標識為 GPE,表示這是一個地理位置的名稱。
- NNP 表示 'Hawaii' 是一個專有名詞。
- ./.:
- '.' 被標識為 '.',表示這是句子的結束。




















