Civitai 提供整合性平台、LoRA 開放大家參與,每天上傳到網站的檔案越來越多。自 12 月注意力回到 Stable Diffusion,探尋選項變多帶來倍增的可能性,我卻發現此刻的 Civitai ,以西洋風格的角色或風格為大宗,日式風格的角色範例圖片則有點...像我用 waifu diffusion 模型生成的角色???那我直接用已經有的模型產圖有什麼差別 ?
找不到載來嘗試的動力... 我不想下載好幾 GB 的 Checkpoint 就為了生成一個角色、嘗試畫風更不是我感興趣的範疇,只要 AI 生成的產物繼續人物四體畸拙、空間扭曲破碎,產出來的圖永遠都是超現實主義,不管作者自稱追求擬真或其他什麼畫風。
所以回去研究場景吧。

這個階段,只要忽視細節+模糊背景,單憑 AI 就能輕易生成美圖
說實在的,一個明顯主體站在那,人們注意力就會集中觀察這個主體,這種原理應用在人像攝影或許有加分效果,但用在 AI 圖片只會更快被看穿人物缺陷吧 ? 既然人工智慧有所不足,使用者做為發號司令的角色,應該想辦法替它藏拙,讓對的人擺在對的位置上,這也是為何有些作者會讓 AI 生成的人物把手擺身後的原因。
希望這張圖裡的女僕能稍微退後,以呈現城市工業革命與蒸氣龐克的光輝。若說工業革命展現技術為產業帶來突破性進展、蒸氣龐克象徵人類對技術的樂觀與狂想,那 AI 顯然是工業革命加蒸氣龐克啊,那時網上某些討論人工智慧是否會導致某些職業消失,即便誰也沒說服誰,往往常見這句「就算現在 AI 做不到,AI 發展那麼快,一定會 !」一錘定音,拿未發生的趨勢和現況攪和,豈不是現實與虛幻的第三類接觸 ?



AI 成功降低人物存在感了,好欸
然後我繼續嘗試,能夠調整人物在畫面中偏大還偏小了,試著讓畫面出現特定物體吧。
要呈現英倫風格,當然要出現大笨鐘。

????????????????????????????????????????????????
之所以在 AI 生成選擇探索二次元風格,就是因為這時期的 AI 追求擬真只會害自己被恐怖谷嚇死。現在我竟然因為一棟鐘樓產生恐怖谷效應了??????????
跑出幾張「擬大笨鐘」,它的非大笨鐘特徵顯眼到令我產生古怪感,只能放棄讓 AI 產出著名地標,因為要鐘面正常就像要手指正常一樣困難。還有什麼能當作這種輝煌時代的象徵呢 ? 瓦特的蒸汽機 ? 史蒂芬生的蒸汽火車頭 ?
那些東西現身街道過於怪異,我想試試福特T型車。
以裝配線大規模作業代替傳統個體手工製作,福特T型車的低廉價格讓汽車走入尋常百姓家,不就像 Stable Diffusion 讓毫無繪畫技巧的普羅大眾,也能在家量產自己的作品嗎 ? 但我畢竟沒有對人工智慧抱持任何指望,出圖車輛別像現代交通工具就好了。
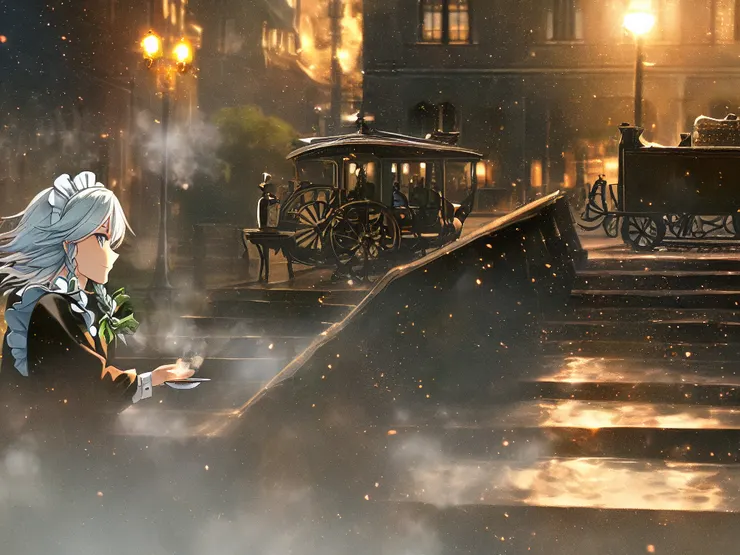
還真有點模樣?!
畢竟 Novelai 模型專門學習二次元圖像,如果幻想風格城市背景出現這些車輛,被模型學習也是可能的事,只是我尚未掌握什麼提示詞可以讓它穩定呈現。我試著加強車輛相關敘述的權重,讓 AI 暫且以汽車為主體——

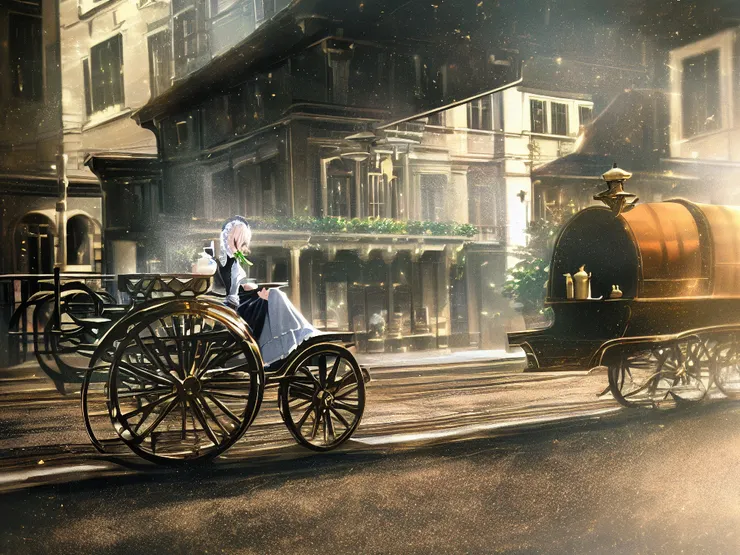
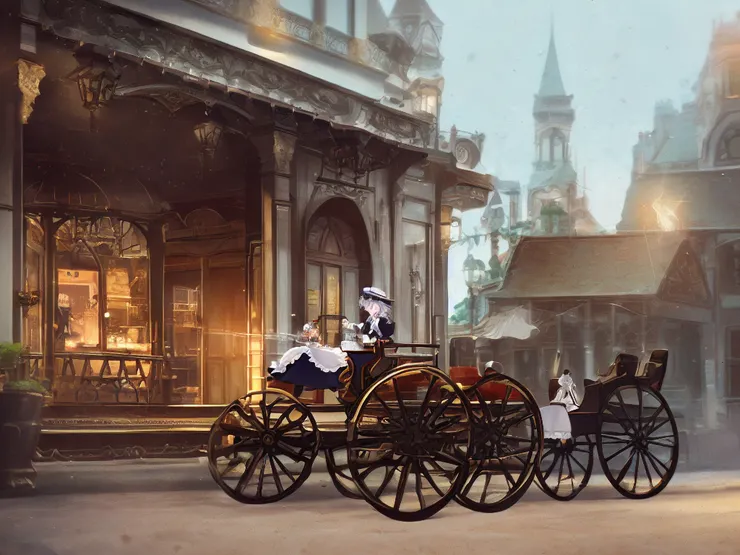
............................我感受到 AI 的努力,雖然它失敗了。
於是我回到了 2022 年 10 月使用 SD 的思維:既然 AI 沒辦法畫正常的構造物,就給它畫渾沌、毀滅、破壞的場景,反而能畫得比較自然!!!

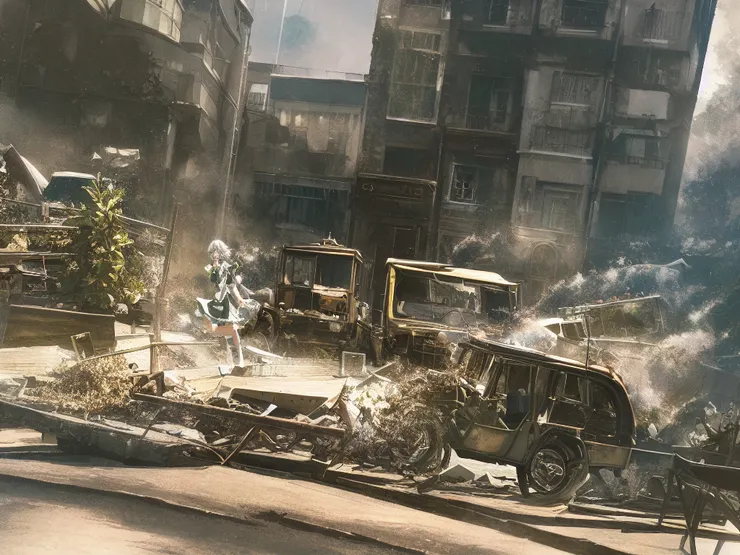

結論是,這時候的 AI 依然難以分心多用,當我對背景有要求、對前景有要求、對人物有要求,即使是人工智慧也無法成人之美。
最後還是要選取背景範圍給 AI 重繪才能達到效果 :

我知道福特T型車不見,但我已經懶得吐槽了。
LoRA 普及前某段時間,我進行著如此無聊的測試,
不是 2D 或擬真美女,失敗了連上傳社群騙讚的價值都沒有。
但我認為如果要讓畫面產生意義,身為使用者必須設法找到操控 AI 呈現各種鏡頭的方式。當人工智慧生成技術蓬勃發展、各種繪圖風格都可以學習,一張圖的意義或許不再屬於怎麼畫,而在於用這張圖傳達出什麼,但 2022 年底的 AI 無法生成文字,
那麼 AI 圖片唯一能傳遞價值的管道,只剩鏡頭語言了吧。
兩年後將同樣提示詞給 Stable Diffusion 重新跑,即便不修圖的情況下只靠抽卡,成品已接近想呈現的畫面,當時的未盡之業竟然有達成的一天。

「前面撞成一團了 ? 放寬心,喝杯茶~」
「向前奔馳偶爾也要停下來,想想自己與目標與行動的關聯性。」
「追逐最新的 AI 技術時,有沒有遺漏什麼正發生的事情 ?」
「至少這裡的時間軸是緩慢的,寫了超過二十篇才突破 2022 年。」
「想必今後也會如此慢吞吞地寫下去,來享有反思與喝茶的時間吧。」

「Keep Calm And Drink Tea.」
「致美好的黎明。」



























