DeepSeek 能以更低的成本 訓練 AI 模型,主要有 以下幾個關鍵優勢,即使其他 AI 公司也在使用 MoE(Mixture-of-Experts)架構,DeepSeek 仍能顯著降低開發成本: --- 1. MoE 架構的極致優化 DeepSeek 並非只是 採用 MoE,而是 將 MoE 的計算效率進一步極限優化,這與 Google 的 Switch Transformer、Mistral Mixtral 有所不同: Sparse Activation(稀疏激活): DeepSeek 在 6,710 億參數 的模型中,每個 token 只用 370 億參數 進行運算(Google Switch Transformer 可能啟用更多)。 更少的計算量 = 更低的 GPU 運行成本,相比 OpenAI 全參數 GPT-4,DeepSeek 可以大幅降低推理成本。 專家權重分配更智能: DeepSeek 的 MoE 採用更精細的路由機制,將不同的 token 智慧分配給最合適的專家網絡,讓 GPU 運算更有效率,減少計算浪費。 極致的訓練數據壓縮: 資料清洗 & Token 選擇:DeepSeek 可能只選擇高價值的語料,減少低質量的 token,從而用更少的 token 訓練出更有效的 AI。 資料增強技術:透過數據擴增,DeepSeek 可能用更少的資料達到更好的效果。 --- 2. 低成本 GPU 使用策略 DeepSeek 的 GPU 運行成本比 OpenAI、Google 低,可能來自以下策略: (1) 使用 H800 而非 H100 DeepSeek 使用的 NVIDIA H800(中國版 H100),性能比 H100 稍低,但價格便宜。 H800 受中國出口管制影響,雖然比 H100 慢,但 DeepSeek 可能獲得了 更優惠的價格 或 政府補助,進一步降低硬體成本。 (2) 高效的 GPU 佈局 & 並行計算 DeepSeek 可能採用了類似 Google TPU Mesh 的架構,讓 2,000 張 H800 GPU 更有效地協作。 這意味著即使 GPU 數量較少,DeepSeek 仍能透過更高效的計算架構達到類似 GPT-4 的訓練效果。 (3) 可能利用中國自研 AI 晶片 由於美國對中國限制高階 GPU 出口,DeepSeek 可能部分使用華為 Ascend 910B、寒武紀 MLU、比特大陸 AI 晶片。 這些國產 AI 晶片雖然效能不如 H100,但成本更低,可以進一步節省支出。 --- 3. 省下昂貴的雲端訓練成本 大部分 AI 公司(如 OpenAI、Anthropic、Mistral)都依賴雲端訓練,需要付給 AWS、Azure 高昂的 GPU 計算費用。 DeepSeek 自建數據中心,而非租用 AWS: OpenAI 訓練 GPT-4 時,花費了數億美元在 Azure 的 GPU 雲端運算。 DeepSeek 可能直接自建數據中心,這樣可以避免長期的雲端租用成本,雖然前期投入較大,但長期來看更具成本優勢。 --- 4. 可能獲得政府支持 & 補助 DeepSeek 作為中國 AI 領域的代表,極有可能獲得中國政府的大力支持,這可能來自: 政府提供 GPU 資源補助(降低 NVIDIA H800 購買成本)。 國家級超算資源支援(可能利用中國的超算中心來降低運算成本)。 本土 AI 生態鏈優惠(中國 AI 產業鏈成熟,減少依賴昂貴的進口技術)。 這使得 DeepSeek 能夠 比 OpenAI、Google、Anthropic 更低成本地訓練 AI 模型。 --- 5. 軟體層面高度優化 DeepSeek 可能透過以下技術進一步降低成本: DeepSpeed / FlashAttention:加快訓練速度,減少 GPU 訓練時間。 進階壓縮技術(如 LoRA, QLoRA):讓模型在 不降低效果的情況下大幅減少計算資源。 更高效的分佈式訓練:讓 2,000 張 H800 GPU 充分發揮計算能力,避免計算閒置。 --- 結論:DeepSeek 的「低成本」= 全面技術優化 DeepSeek 並非只是「砸錢少」就能做到這點,而是: 1. 極致優化 MoE 架構(稀疏激活 + 智慧專家選擇)。 2. 高效 GPU 運算策略(便宜的 H800 + 國產 AI 晶片)。 3. 避免昂貴的雲端租用成本(自建數據中心)。 4. 可能獲得政府支持(資金補助 + 超算資源)。 5. 使用最先進的 AI 訓練優化技術(DeepSpeed, FlashAttention, QLoRA)。 這些因素疊加起來,讓 DeepSeek 在僅使用 2,000 張 H800 GPU 的情況下,達到媲美 GPT-4 的 AI 競爭力,大幅降低成本。 這也解釋了為何 OpenAI、Google、Meta、Anthropic 在投入數億美元後,仍然面臨高昂的 AI 訓練與推理成本,而 DeepSeek 則能以更小的投資獲得類似的效果。
留言

德魯的文明觀測站|一直都放在房間
14會員
948內容數
萬物皆空..
需要的
只是一個乾淨明亮的地方
「如果文明是一場巨大的實驗,這就是我的觀測報告。」
拒絕平庸的無病呻吟,德魯帶你撕開時間的邊界,讓我們在宇宙的底層邏輯裡熱血重逢。
德魯的文明觀測站|一直都放在房間的其他內容
2025/04/27
夜裡,鄒縱天翻身無數次,床單皺成一片陌生的海。
他拿起手機,指尖滑過冷冷的螢幕。
社群平台影片跳了出來。
標題寫著:
【1秒都不能餓到】
貪吃兔守候餵食機 飼料掉落秒歪頭大口吃取
畫面裡,兔子蹲坐在機器下,眼睛圓滾滾,耳朵緊貼著背脊,身子微微發抖。
飼料落下的聲音很輕,
2025/04/27
夜裡,鄒縱天翻身無數次,床單皺成一片陌生的海。
他拿起手機,指尖滑過冷冷的螢幕。
社群平台影片跳了出來。
標題寫著:
【1秒都不能餓到】
貪吃兔守候餵食機 飼料掉落秒歪頭大口吃取
畫面裡,兔子蹲坐在機器下,眼睛圓滾滾,耳朵緊貼著背脊,身子微微發抖。
飼料落下的聲音很輕,
2025/04/24
114.4.24
今天早上,我驚覺樓下起火。濃煙竄升至樓梯間,幾乎無法視物。
我奪門而出、逃至室外,所幸無恙。但回頭望著那吞噬空氣與秩序的黑煙,我問自己:
如果火煙源自樓梯口,怎麼辦?
如果門打不開?消防隊還沒到?我,還能活嗎?
這篇文章,寫給每一個住在高樓、以樓梯為唯一出路的
2025/04/24
114.4.24
今天早上,我驚覺樓下起火。濃煙竄升至樓梯間,幾乎無法視物。
我奪門而出、逃至室外,所幸無恙。但回頭望著那吞噬空氣與秩序的黑煙,我問自己:
如果火煙源自樓梯口,怎麼辦?
如果門打不開?消防隊還沒到?我,還能活嗎?
這篇文章,寫給每一個住在高樓、以樓梯為唯一出路的
2025/04/23
Alginate Gel Immobilized Algae:創新的藻類固定技術,解決環境問題
在當今環境保護與可持續發展的背景下,藻類的應用已經成為研究的熱點之一。特別是海藻酸鹽凝膠包埋藻類技術,作為一種新型的環境修復方法,受到了廣泛的關注。這項技術不僅能夠有效處理水中的污染物,還能夠提高藻類的
2025/04/23
Alginate Gel Immobilized Algae:創新的藻類固定技術,解決環境問題
在當今環境保護與可持續發展的背景下,藻類的應用已經成為研究的熱點之一。特別是海藻酸鹽凝膠包埋藻類技術,作為一種新型的環境修復方法,受到了廣泛的關注。這項技術不僅能夠有效處理水中的污染物,還能夠提高藻類的
你可能也想看




















5 月,方格創作島正式開島。這是一趟 28 天的創作旅程。活動期間,每週都會有新的任務地圖與陪跑計畫,從最簡單的帳號使用、沙龍建立,到帶著你從一句話、一張照片開始,一步一步找到屬於自己的創作節奏。不需要長篇大論,不需要完美的文筆,只需要帶上你今天的日常,就可以出發。征服創作島,抱回靈感與大獎!
5 月,方格創作島正式開島。這是一趟 28 天的創作旅程。活動期間,每週都會有新的任務地圖與陪跑計畫,從最簡單的帳號使用、沙龍建立,到帶著你從一句話、一張照片開始,一步一步找到屬於自己的創作節奏。不需要長篇大論,不需要完美的文筆,只需要帶上你今天的日常,就可以出發。征服創作島,抱回靈感與大獎!


AI 世界正掀起一場變革!🔥 近期,DeepSeek 這家來自中國的 AI 公司,以開源策略、知識蒸餾(Distillation)、混合專家(Mixture of Experts, MoE)技術,成功挑戰 OpenAI,震撼了全球 AI 社群。這不只是技術的突破,更是一場「成長戰略」的最佳示範!
AI 世界正掀起一場變革!🔥 近期,DeepSeek 這家來自中國的 AI 公司,以開源策略、知識蒸餾(Distillation)、混合專家(Mixture of Experts, MoE)技術,成功挑戰 OpenAI,震撼了全球 AI 社群。這不只是技術的突破,更是一場「成長戰略」的最佳示範!


見諸參與鄧伯宸口述,鄧湘庭於〈那個大霧的時代〉記述父親回憶,鄧伯宸因故遭受牽連,而案件核心的三人,在鄧伯宸記憶裡:「成立了成大共產黨,他們製作了五星徽章,印刷共產黨宣言——刻鋼板的——他們收集中共空飄的傳單,以及中國共產黨中央委員會有關文化大革命決議文的英文打字稿,另外還有手槍子彈十發。」
見諸參與鄧伯宸口述,鄧湘庭於〈那個大霧的時代〉記述父親回憶,鄧伯宸因故遭受牽連,而案件核心的三人,在鄧伯宸記憶裡:「成立了成大共產黨,他們製作了五星徽章,印刷共產黨宣言——刻鋼板的——他們收集中共空飄的傳單,以及中國共產黨中央委員會有關文化大革命決議文的英文打字稿,另外還有手槍子彈十發。」

當代名導基里爾.賽勒布倫尼科夫身兼電影、劇場與歌劇導演,其作品流動著強烈的反叛與詩意。在俄烏戰爭爆發後,他持續以創作回應專制體制的壓迫。《傳奇:帕拉贊諾夫的十段殘篇》致敬蘇聯電影大師帕拉贊諾夫。本文作者透過媒介本質的分析,解構賽勒布倫尼科夫如何利用影劇雙棲的特質,在荒謬世道中尋找藝術的「生存之道」。
當代名導基里爾.賽勒布倫尼科夫身兼電影、劇場與歌劇導演,其作品流動著強烈的反叛與詩意。在俄烏戰爭爆發後,他持續以創作回應專制體制的壓迫。《傳奇:帕拉贊諾夫的十段殘篇》致敬蘇聯電影大師帕拉贊諾夫。本文作者透過媒介本質的分析,解構賽勒布倫尼科夫如何利用影劇雙棲的特質,在荒謬世道中尋找藝術的「生存之道」。


詳述DeepSeek與其他AI模型的比較,並探討優勢、劣勢及應用領域。
DeepSeek優勢在於中文語義理解,以及金融和法律領域的專業知識,但創意多樣性略遜於GPT-4。
詳述DeepSeek與其他AI模型的比較,並探討優勢、劣勢及應用領域。
DeepSeek優勢在於中文語義理解,以及金融和法律領域的專業知識,但創意多樣性略遜於GPT-4。


DeepSeek技術的優缺點分析,以及在LLM開發和商業化應用上的潛力評估。文章探討DeepSeek的蒸餾學習機制,並與傳統的生成式AI訓練方法進行比較,同時也提及強化學習在提升模型性能中的關鍵作用。最後,作者從企業資安角度出發,對DeepSeek的應用提出保留意見,但仍肯定其發展前景。
DeepSeek技術的優缺點分析,以及在LLM開發和商業化應用上的潛力評估。文章探討DeepSeek的蒸餾學習機制,並與傳統的生成式AI訓練方法進行比較,同時也提及強化學習在提升模型性能中的關鍵作用。最後,作者從企業資安角度出發,對DeepSeek的應用提出保留意見,但仍肯定其發展前景。


DeepSeek以557.6萬美元訓練成本,顛覆AI行業規則!從「架構瘦身」到「數據煉金」,再到「硬體巫術」,這家中國AI新星用技術與商業策略的組合拳,將成本壓縮至GPT-4的1/20。未來,AI競爭將從「算力軍備」轉向「效率革命」。
DeepSeek以557.6萬美元訓練成本,顛覆AI行業規則!從「架構瘦身」到「數據煉金」,再到「硬體巫術」,這家中國AI新星用技術與商業策略的組合拳,將成本壓縮至GPT-4的1/20。未來,AI競爭將從「算力軍備」轉向「效率革命」。


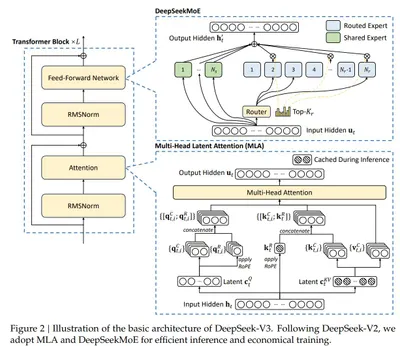
本文探討大型語言模型的發展趨勢,並以DeepSeek-V3為例,分析其在模型架構、訓練方法和效率成本上的改進。作者指出,大型語言模型的競爭焦點已轉向實際應用和數據的運用,而非模型間微小的性能差異。
本文探討大型語言模型的發展趨勢,並以DeepSeek-V3為例,分析其在模型架構、訓練方法和效率成本上的改進。作者指出,大型語言模型的競爭焦點已轉向實際應用和數據的運用,而非模型間微小的性能差異。


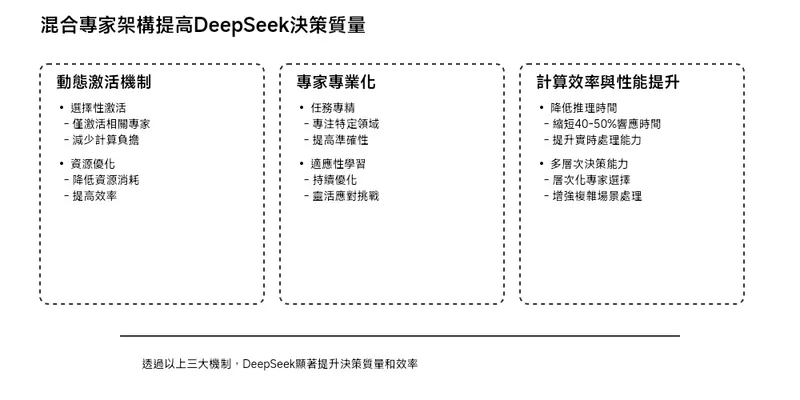
混合專家架構(Mixture of Experts, MoE)在DeepSeek中透過多種方式顯著提高了決策質量。
以下是該架構如何實現這一目標的幾個關鍵方面:
動態激活機制
選擇性激活
DeepSeek的MoE架構允許模型在處理查詢時,僅激活與該任務最相關的專家。
這種選
混合專家架構(Mixture of Experts, MoE)在DeepSeek中透過多種方式顯著提高了決策質量。
以下是該架構如何實現這一目標的幾個關鍵方面:
動態激活機制
選擇性激活
DeepSeek的MoE架構允許模型在處理查詢時,僅激活與該任務最相關的專家。
這種選


當時間變少之後,看戲反而變得更加重要——這是在成為母親之後,我第一次誠實地面對這一件事:我沒有那麼多的晚上,可以任性地留給自己了。看戲不再只是「今天有沒有空」,而是牽動整個週末的結構,誰應該照顧孩子,我該在什麼時間回到家,隔天還有沒有精神帶小孩⋯⋯於是,我不得不學會一件以前並不擅長的事:挑選。
當時間變少之後,看戲反而變得更加重要——這是在成為母親之後,我第一次誠實地面對這一件事:我沒有那麼多的晚上,可以任性地留給自己了。看戲不再只是「今天有沒有空」,而是牽動整個週末的結構,誰應該照顧孩子,我該在什麼時間回到家,隔天還有沒有精神帶小孩⋯⋯於是,我不得不學會一件以前並不擅長的事:挑選。


中國AI模型DeepSeek崛起,其低成本訓練模式引發市場關注,探討其對臺灣伺服器ODM產業的影響,以及長期發展潛力。
中國AI模型DeepSeek崛起,其低成本訓練模式引發市場關注,探討其對臺灣伺服器ODM產業的影響,以及長期發展潛力。

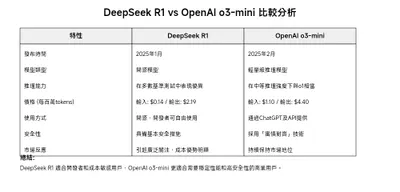
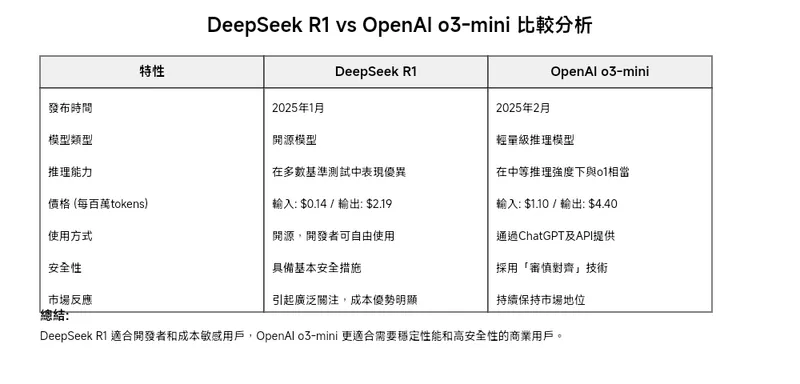
DeepSeek R1 與 OpenAI o3-mini 比較表:
成本與開源性:
DeepSeek R1 的開源特性和低成本使其對開發者和中小型企業更具吸引力,尤其是在需要大量處理 tokens 的應用場景中。
OpenAI o3-mini 的價格相對較高,但其輕量化設計和穩定的推理能力
DeepSeek R1 與 OpenAI o3-mini 比較表:
成本與開源性:
DeepSeek R1 的開源特性和低成本使其對開發者和中小型企業更具吸引力,尤其是在需要大量處理 tokens 的應用場景中。
OpenAI o3-mini 的價格相對較高,但其輕量化設計和穩定的推理能力