結論直接看
整體來看,兩者的基礎 CPU 架構一致,因此在 科學計算 (Rodinia, NAMD)、基礎壓縮/解壓縮、系統微基準 (ctx_clock, Sysbench CPU) 上,效能差異極小,幾乎完全相同。
但在 需要持續高性能的多執行緒負載(編譯、渲染、影音編碼、演算法 AI)上,m8i.large 明顯優於 m8i-flex.large:- m8i.large:
適合 長時間持續高效能任務,如大型專案編譯、渲染、影片轉碼、演算法/AI 模擬,效能領先 m8i-flex.large 10% 到 20%。 - m8i-flex.large:
適合 一般計算、間歇性工作負載,在多數基礎測試與科學計算上表現相近,性價比佳,但在長時間編譯/渲染/編碼上略遜色。
Wei 啥的結論
考量到兩者的價差真的很小... AWS 計算機
隨需的價格為 m8i.large $0.10584/hr 及 m8i-flex.large $0.10055/hr。
Web 仔就用 m8i-flex,足夠把所有的需求都搞定了。
運算仔直接開 m8i,開完就關掉。
自己付錢的 RI 仔 你買不到 RI 了,這個世代沒賣了。
吃代理商大鍋飯 SP 的用 m8i。理論上比較通用,拿來當 EKS node 什麼的。
至於老闆一直說很貴的還是去用 t3,出事再改 m8i 吧。
還有想要從 m7i 或是 m7a 上來的,下面是價格。
m7i.large $0.1008/hr、m7i-flex.large $0.09576/hr 及 m7a.large $0.11592/hr。
m7i 來的:
漲價但值得。預算不差那一點的,可以升級 m8i。
m7a 來的:
如果你本來就是 AMD yes 的真核仔,那繼續用 m7a,等 m8a 出來應該會很香。
從 intel 不得不轉 AMD 的,也不討厭超執行緒的,可以回來 m8i 了,這顆 CPU 挺香的,還可以跟老闆一直說很貴的在安利一下,順勢回到 intel 擁抱。
起因
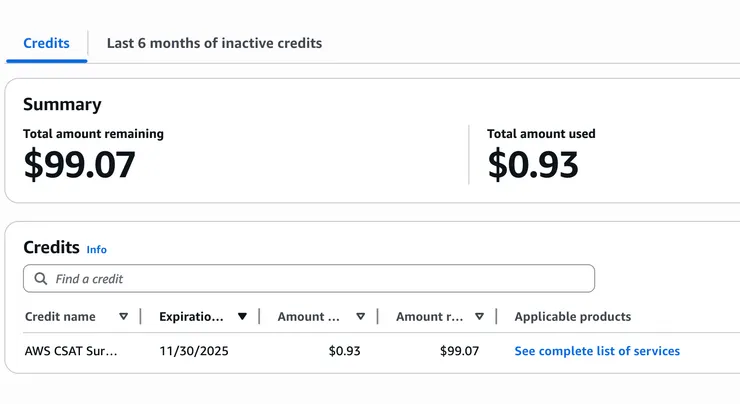
突然發現自己那時候填的 AWS 問卷送的 $100 鎂會在十一月底到期...
那...就來跑個分好了?反正是白嫖的。
這次用 phoronix-test-suite 來跑跑看,有興趣的可以去 Github 上看看。
用一些比較可能會用在線上服務的 instance type 來跑跑。
測試的 Region 選在 Oregon。
OS 選擇 Amazon Linux 2023 AMI 2023.8.20250915.0 x86_64 HVM kernel-6.1。
EBS 選用普遍的 gp3 IOPS 3000,Throughput 125。
用 lscpu 來看 CPU 參數。
過程
安裝 phoronix-test-suite
# 需要 git 與 php-cli
sudo yum install -y php-cli php-xml git gcc unzip wget
# clone 最新版
git clone https://github.com/phoronix-test-suite/phoronix-test-suite.git
cd phoronix-test-suite
# 安裝
sudo ./install-sh
m8i 與 m8i-flex的差別
兩個的 CPU 都是 AWS 向 Intel 訂製的 Intel Xeon 6975P-C。
Processor: Intel Xeon 6975P-C (1 Core / 2 Threads), Motherboard: Amazon EC2 m8i.large (1.0 BIOS), Chipset: Intel 440FX 82441FX PMC, Memory: 1 x 8GB DDR5-7200MT/s, Disk: 107GB Amazon Elastic Block Store, Network: Amazon Elastic
Processor: Intel Xeon 6975P-C (1 Core / 2 Threads), Motherboard: Amazon EC2 m8i-flex.large (1.0 BIOS), Chipset: Intel 440FX 82441FX PMC, Memory: 1 x 8GB DDR5-7200MT/s, Disk: 107GB Amazon Elastic Block Store, Network: Amazon Elastic
有趣的是高負載情況下 m8i-flex.large 在跑滿兩小時後,會自動把使用率壓制在 80% 附近,難道這就是 flex 的機制?
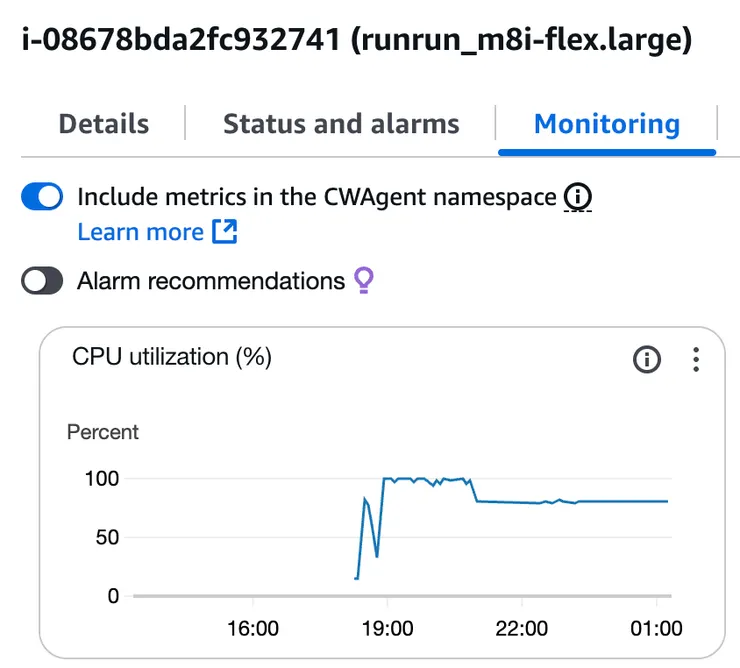
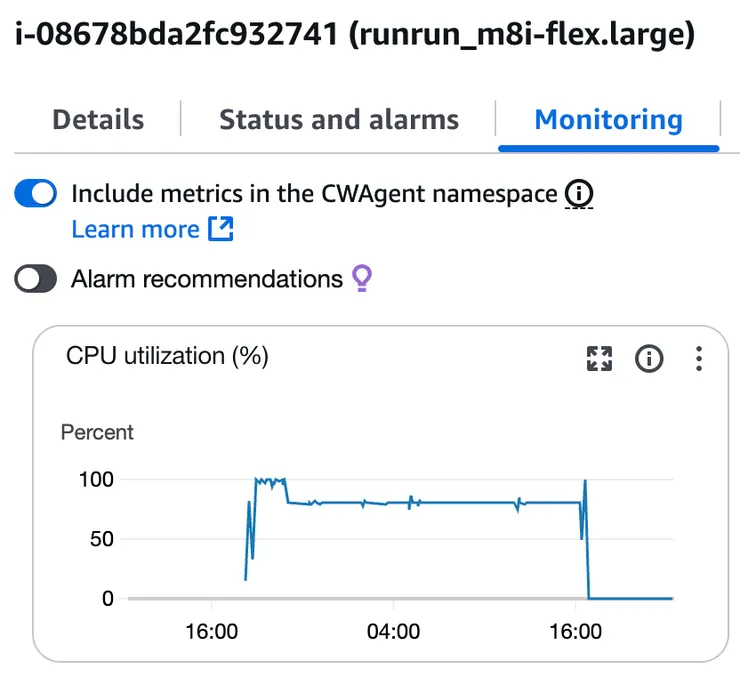
跑分比較
EC2 m8i.large vs m8i-flex.large
科學計算類
- Rodinia LavaMD:模擬分子動力學計算,考驗浮點數效能,越低越好。
- 1340.62 秒 vs 1341.68 秒(幾乎相同)
- Rodinia CFD Solver:計算流體力學求解器,測試記憶體與計算效能,越低越好。
- 95.42 秒 vs 95.67 秒 (幾乎相同)
- NAMD ATPase / STMV:分子動力學模擬,模擬蛋白質與病毒,單位 ns/day 越高越好。
- ATPase:0.24267 vs 0.24327(幾乎相同)
- STMV:0.07108 vs 0.06969(m8i.large 較佳)
影音編碼類
- Kvazaar (HEVC/H.265 Encoder):影片編碼效能,Frames Per Second 越高越好。
- 4K Slow:1.28 vs 1.07
- 4K Medium:1.31 vs 1.08
- 1080p Slow:7.15 vs 5.99
- 1080p Medium:7.34 vs 6.32
- 4K Very Fast:3.19 vs 2.63
- 4K Ultra Fast:5.33 vs 4.43
- 1080p Very Fast:15.03 vs 13.63
- 1080p Ultra Fast:24.92 vs 25.06(少數 m8i-flex 較佳)
- x264 / x265:常用影片編碼器 (H.264 / H.265),測 CPU 多媒體處理效能。
- x264 4K:4.20 vs 3.62
- x264 1080p:19.01 vs 18.89
- x265 4K:3.30 vs 2.81
- x265 1080p:14.71 vs 13.50 (m8i.large 完勝,m8i-flex.large 只有85%~95%間)
壓縮與解壓縮
- 7-Zip Compression / Decompression:壓縮與解壓縮速度,MIPS 越高越好。
- 壓縮:12244 vs 12537(幾乎相同)
- 解壓:7313 vs 7336(幾乎相同)
AI / 演算法類
- Stockfish 16.1:國際象棋 AI,每秒節點數 (Nodes/s) 越高越好。
- 1,704,166 vs 1,480,447(m8i.large 優勢明顯,m8i-flex.large 輸 13%)
- asmFish:另一款高效象棋引擎,測演算法與記憶體效能。
- 3,657,558 vs 2,961,258(m8i.large 優勢明顯,m8i-flex.large 輸 19%)
編譯與建構
- GCC Compilation:C/C++ 編譯時間,越低越好。
- 4748.84 秒 vs 5606.78 秒 (m8i.large 比 m8i-flex.large 快了 15%)
- Linux Kernel Compilation (defconfig / allmodconfig):核心編譯,測試系統 I/O 與 CPU 整體效能。
- defconfig:661.38 vs 788.13(m8i.large 比 m8i-flex.large 快約 16%)
- allmodconfig:9969.90 vs 12185.35 (m8i.large 比 m8i-flex.large 快約 18%)
- POV-Ray:光線追蹤渲染,模擬 3D 場景,越低越好。
- 274.01 秒 vs 328.70 秒(m8i.large 比 m8i-flex.large 快約 17%)
- Radiance (Serial / SMP):建築光照模擬,單執行緒與多執行緒效能。
- Serial:489.28 vs 489.04(幾乎相同)
- SMP:426.84 vs 443.56(m8i.large 比 m8i-flex.large 快約 4%)
系統測試
- ctx_clock:系統 context switch(上下文切換)時間,越低越好。
- 194 vs 193(幾乎相同)
- Sysbench CPU:CPU 基準運算效能,Events/s 越高越好。
- 3532.75 vs 3532.74(幾乎相同)
結論
整體來看,兩者的基礎 CPU 架構一致,因此在 科學計算 (Rodinia, NAMD)、基礎壓縮/解壓縮、系統微基準 (ctx_clock, Sysbench CPU) 上,效能差異極小,幾乎完全相同。
但在 需要持續高性能的多執行緒負載(編譯、渲染、影音編碼、演算法 AI)上,m8i.large 明顯優於 m8i-flex.large:
- m8i.large:
適合 長時間持續高效能任務,如大型專案編譯、渲染、影片轉碼、演算法/AI 模擬,效能領先 m8i-flex.large 10%–20%。 - m8i-flex.large:
適合 一般計算、間歇性工作負載,在多數基礎測試與科學計算上表現相近,性價比佳,但在長時間編譯/渲染/編碼上略遜色。























