我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
先用一張圖概括 Attention 機制的輸入與輸出:

Attention 機制縱覽
- 以一個句子包含四個字為例子
- a1、a2、a3、a4 是四個字各自對應的向量
- 每個向量可以是 Input Layer 輸入也可以是 Hidden Layer 輸出
- 這四個向量經過 Attention 機制會轉成向量 b1、b2、b3、b4
- 我現在就是要來闡述 Attention 中間步驟
計算 Query 與 Key:

- 向量 a1 乘上矩陣 Wq 變成向量 q1
- 向量 a2 乘上矩陣 Wk 變成向量 k2
- 向量 a3 乘上矩陣 Wk 變成向量 k3
- 向量 a4 乘上矩陣 Wk 變成向量 k4
- 向量 q1 乘上向量 k2 變成純量 a1,2 ,以此類推得到 a1,3 與 a1,4
然後算 Attention Score:

- 向量 a1 乘上矩陣 Wk 變成向量 k1
- 向量 q1 乘上向量 k1 變成純量 a1,1
- 將手上有的 a1,1、a1,2、a1,3、a1,4 做正歸化得到 a'1,1、a'1,2、a'1,3、a'1,4
再來計算輸出:

- 向量 a1 乘上矩陣 Wv 變成向量 v1
- 向量 a2 乘上矩陣 Wv 變成向量 v2
- 向量 a3 乘上矩陣 Wv 變成向量 v3
- 向量 a4 乘上矩陣 Wv 變成向量 v4
- 向量 v1 乘上 a'1,1 、 向量 v2 乘上 a'1,2、 向量 v3 乘上 a'1,3 、 向量 v4 乘上 a'1,4 , 這四項相加得向量 b1
同理可以計算 b2 、 b3 、 b4 ,現在我要闡述矩陣做法:

- 向量 a1 乘上矩陣 Wq 變成向量 q1 、 向量 a2 乘上矩陣 Wq 變成向量 q2 、 向量 a3 乘上矩陣 Wq 變成向量 q3 、 向量 a4 乘上矩陣 Wq 變成向量 q4 ,然後堆疊q1 、 q2 、 q3 、 q4 變成矩陣 Q
- 同理整理出矩陣 K 與矩陣 V
接著計算 Attention Score:
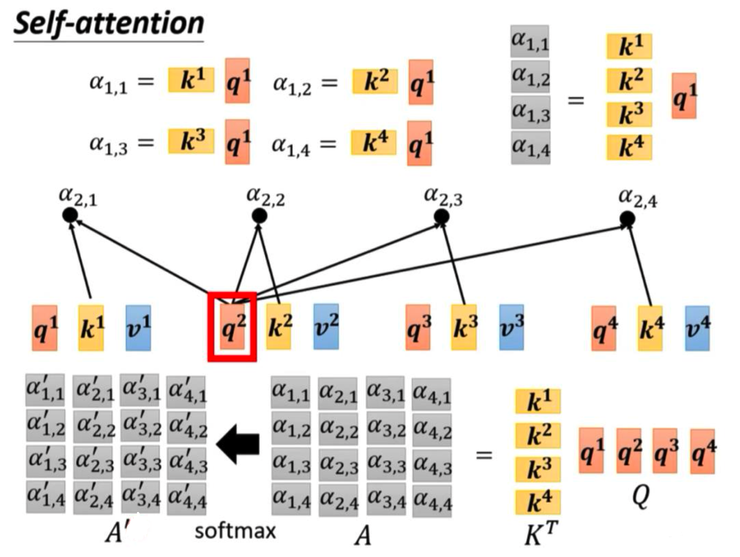
- 之前說向量 q1 乘上向量 k1 變成純量 a1,1 、 向量 q1 乘上向量 k2 變成純量 a1,2 、 向量 q1 乘上向量 k3 變成純量 a1,3 、 向量 q1 乘上向量 k4 變成純量 a1,4 ,這用矩陣來說就是:矩陣 KT 乘上矩陣 Q 的第一欄變成矩陣 A 的第一欄
- 以此手法可以堆出整個矩陣 A
- 矩陣 A 執行正歸化即可得到矩陣 A'
最後算輸出:

- 之前說向量 v1 乘上 a'1,1 、 向量 v2 乘上 a'1,2、 向量 v3 乘上 a'1,3 、 向量 v4 乘上 a'1,4 , 這四項相加得向量 b1
- 上述作法是矩陣 V 乘上矩陣 A' 的第一欄,做堆疊之後就是矩陣 O 是矩陣 V 乘上矩陣 A'
最後總整理為:

- 向量 a1 、 向量 a2 、 向量 a3 、 向量 a4 以欄為堆疊方向行成矩陣 I
- 矩陣 I 和矩陣 Wq 相乘得到矩陣 Q,同理得到矩陣 K 與矩陣 V
- 矩陣 KT 乘上矩陣 Q 形成矩陣 A
- 矩陣 A 做正規化得到矩陣 A'
- 矩陣 V 乘上矩陣 A' 得到矩陣 O
















