
在《聰明思考》(中)篇裡,我們談到人類主觀從接收外部資訊到產生回應,會經歷感受、認知、基模、回應四個階段。今天這篇我們脫離上次的主觀思維,改來談談客觀分析資訊的方式!
如果我們眼前有個資訊,要怎麼判斷它是正確可吸收的?說到客觀資訊可定脫離不了實驗與實驗結果的解讀,而判斷這些事情正是數學中統計上在做的事!欸欸!等等!別看到數學就想關掉啊!其實要理解這些不需要用到艱澀的數學概念,我們只要理解它們可以用在怎麼樣的情境裡、如何避免偏誤解讀,就可以利用統計的想法來幫助我們的思考。
如果眼前有項統計結果,那要怎麼推導出可相信的結論?
回到前面的兩個問題,第一個問題稱之為詮釋問題,即「怎麼詮釋哪部分是正確可信的」;第二個問題則稱之為試驗問題,即「眼前有一個現象,我們要怎麼確認它能夠導出正確的結論」。今天我們就來聊聊這兩個問題吧!
詮釋問題

樣本的性質
二零零七年德州州長 Ricky Perry 宣布行政命令,規定全州十二歲女孩都要施打人類乳突病毒的疫苗,預防子宮頸癌。二零一二年共和黨總統初選時,Michele Bachman 為了讓自己的聲勢超過 Ricky,就對外宣稱「小女兒接種疫苗之後,就因為疫苗的緣故出現了智能障礙。」
這句話有哪些問題?你可以先想想看!我們要準備來解答囉!
第一個問題:因果不合理。疫苗跟智能障礙的因果性在哪?「先打疫苗之後出現智能障礙」並不能描述兩者之間有足夠強的關聯、具備因果性。否則吃早餐之後死亡,難不成我們要解讀成不吃早餐才能避免死亡?這很明顯有點牽強吧!
第二個問題:誘導偏誤。雖然語句上只有講小女兒,但想要凸顯的重點卻是後面的疫苗引發智能障礙,試圖以以偏概全的方式傳達概念。
第三個問題:抽樣不隨機。可以想像這是一個針對接種疫苗者的實驗,觀測其施打疫苗後的症狀與智能障礙的關係。而這個實驗所觀察的對象,也就是樣本,是她的女兒。然而這個選擇並非「隨機(每個樣本被選到的機率都一樣)」,甚至並非「隨意(不特別指定對象也不關心各樣本被抽到的機率是否相等)」,而是挑一個「特定」明顯有偏誤的對象去為實驗結果進行解釋。
所以這告訴我們什麼?以後看到「有人…」「有一個…」「誰XXX…」千萬要避免以偏概全的謬誤。
母體群的性質

醫院裡新生男寶寶超過百分之六十的天數,是小醫院比較多還是大醫院比較多?
一樣可以先想想這個問題,你直覺的答案是什麼呢?

第一個觀點:大數法則。如果你學過統計,大概會知道上面這是什麼,但不知道也沒有關係,翻成白話就是「同樣的實驗做越多次,其實驗結果的平均值會接近『真實平均值』。」在現實中,往往真實平均值是找不到的,尤其是像這種小孩出生的人數是男是女的比例根本是未知,但我們還是希望知道男女新生兒的比例啊!於是大數法則就是利用逼近的方法來解決這樣的問題。
此時,我們假設「真實平均值」約莫是男女新生兒各50%,如果小醫院只有十個新生兒,七男三女,那就符合條件,直觀上也滿合理的;然而像大醫院一天有一萬個新生兒好了,如果是男生六千女生四千,總會有哪裡覺得怪怪的。而這種「怪怪的」感覺真的沒錯,因為這種情形發生的機率很低。大數法則就是在講說當你觀察越多新生兒時,男女新生兒比例應該要接近一半,也就是真實平均值。

第二個觀點:測量誤差。一般來說我們測量的結果是由實際值與誤差組合而成,誤差的來源又分為兩個,一個是每次實驗都會有的系統誤差,一個是每次實驗隨機變化的隨機誤差。
系統誤差是指某些因素使得每次測量結果趨向非真實平均值。例如上面的醫院問題時間若發生在 1990 年代的中國,在一胎化政策下,男生的比例就會偏高,這種因為外在而非自然性原因的即為系統誤差,一般常出現在社會性因素、抽樣方法偏差(例如只觀察中國地區就擴大解釋成全球),所以觀察數據結果的時候,要注意到系統誤差可能對實驗結果產生錯誤的結論。
第三個觀點:樣本結果不能解釋群體平均。這算是第一點大數法則的舉一反三,當我們看見一個結果的時候,記得它只是一個抽樣點,並不能代表整個實驗。這是什麼意思?你學測一次考試的結果,並不能 100% 說明你的數學能力;你面試當下的反應,並不能 100% 展現你的能力。可能有人狀況較好、可能有人拉肚子、可能有人昨晚沒睡好、可能有人看到面試官讓他想起他父母等等之類很扯的因素,都有可能影響我們面試當下的表現,時好時壞。
以球員的表現為例,教練跟球探的觀察誰會比較準確?教練觀察一位球員多年,他可以知道好幾次下來這位球員的實力變化與平均表現,然而球探卻不同,他只能以一次的球員表現去衡斷他的實力,相較來說更不準確,甚至只是剛好更這位球探來的時候失準特別嚴重。同樣的情節套用在面試情境也是如此,受試者的當天表現與其性格能力的關聯更是超低,所以透過面試來判斷受試者...其實跟憑直覺差不了多少。
離散與回歸

有兩名老師針對各自班級該次段考成績最爛的學生採用不同的教育方式,A老師採用體罰,B老師則採用鼓勵,但是最後兩名老師都說學生下次段考的成績都變好了,是因為自己的方法比較有效,所以哪一種方法真的比較有用呢?
一樣稍微想一下這個問題,可以利用前面的測量誤差想想有沒有什麼關聯?

第一個想法:中央極限定理。上面列的是它的意義,意思是當一個試驗做無限多次時,其統計分配會趨近於常態分佈。一個試驗做第一次,可能比平均好一點點;一個實驗做第二次,可能比平均差一點點;當做了無限多次,其平均的結果會接近真實平均值。
第二個想法:均值回歸。可以把學生的考試成績當作一場試驗,其中該名學生做過無數多場考試,如果單純抓其中一次「最爛的」出來看,有沒有可能只是觀察到表現特別不好的這一次,那下次不論如何,無論「教育方式」是否有效或者根本不特別去處理,學生的成績下次也會提高、回到正常的平均水準,只是解釋上必須說成績看起來變好了。
第三個想法:以偏概全。要評論一個方法是否有效,只找一個特定人物可以嗎?這一樣犯了以偏概全的謬誤。如果對全校不管成績是好是壞都採用這樣的方法,成績都有「顯著」提昇的話,我們才能說這樣的方法有效。
第四個想法:怎樣算「顯著」提升。在數學上判定是否「顯著」時,我們必須先決定一個顯著水準的數值、明定有顯著變化與無顯著變化的情形,通常前者稱為對立假說、後者稱為虛無假設,再判定「原本的情況」與「變化後的情況」之間差異的機率有沒有在顯著水準之內,如此一來即可斷定在該顯著水準之下,到底是「有」還是「沒有」「顯著」變化。
相關性

在某一地區隨機抽取一百五十人,其有症狀A與症狀B的情況如上表所示,你認為可以拿症狀A判斷有沒有症狀B嗎?
答案是不行。或許有些人會想如果患有症狀A,好像患有症狀B的人也會變多,所以兩者應該是有關連的。但是仔細看,不管有沒有得症狀A,有症狀B的人都是 1/5,這種情形在數學上稱為「獨立」,意即「不管有沒有A條件,其有B症狀的機率皆相等。」
如果班上數學成績好ˇ的人,國文也很好,那麼可以說數學好才會導致國文很好嗎?
這個問題很顯然答案是否定的。數學成績好、國文成績剛好也很好,頂多只能說兩者分數有相關性,詳細的計算就是大家在高中學過相關係數!有相關不能說有因果,甚至「原因」可能是在這之外的。我們曾在《黑馬思維》中說到高爾頓提出優生學,認為數學好、國文好的原因是此人基因較好,但是現在發現更可能是成績好的學生擁有較多的社會資源能夠幫助他學習。
有個實驗是心理學家將鴿子放進裝有食物飲食器的裝置裡,並在地上擺了一個會發光的圓盤。如果圓盤發光鴿子沒有去啄它,飲食器裡就會出現食物,反之則會消失。在這樣的情況,鴿子幾乎無法學習獲取食物的方式。相反地,要是機制設計成有啄光盤才會有食物,鴿子卻能夠快速學習,這是為什麼?
這種現象稱之為錯覺相關 illusory correlation。在一般的巴夫洛夫的狗的實驗中,操作制約的機制是有聲音就會有食物,這是可以引起連結的,在鴿子的實驗中也是如此,但反過來卻學不了,原因是因為在學習過程中,我們傾向發現正相關而非負相關,所以在鴿子的腦中難以學習「不努力才會有食物」的運作機制。
而這種對於相關性的錯誤判斷的相關錯覺也可以聯結到傳統療法中的以形補形、羅夏克墨跡測驗等等。我們如果先入為主地假定有關係,就會試圖找出有關係的證據,忽略掉反對的證據。然而要是我們沒有辦法覺察到關聯性,即便相關性再高,大部分的人也看不出來。
你有沒有過經驗,忽然間晚上拉肚子,讓你開始懷疑是剛剛吃的晚餐裡面有什麼不好的東西?但你為什麼不會懷疑是早餐或昨天的東西出問題呢?
人類要能夠發現因果關係,還有一個很重要的因素是時間,其他動物也一樣。在老鼠按壓開關然後獲得食物的實驗中,如果兩者間隔時間很短,老鼠很快就能學到其關聯性,但要是兩者間隔時間拉很長,老鼠就完全無法發現其相關性。
信度與效度

一個試驗的好壞與信度、效度有關,舉例來說今天做一個英文能力測驗,效度是指能夠測驗你的英文程度,例如題目必須要是真的英文,而且是聽說讀寫,不是什麼畫圖或心理測驗;信度則是指每一次測出來的結果的接近程度。
可以想像是在射標靶,效度是你有沒有射在自己的標靶上而不是別人的標靶,信度則是有沒有每一次都射中紅心。好的試驗應該要讓受試者在測驗時都能夠具有高度的信度與效度。
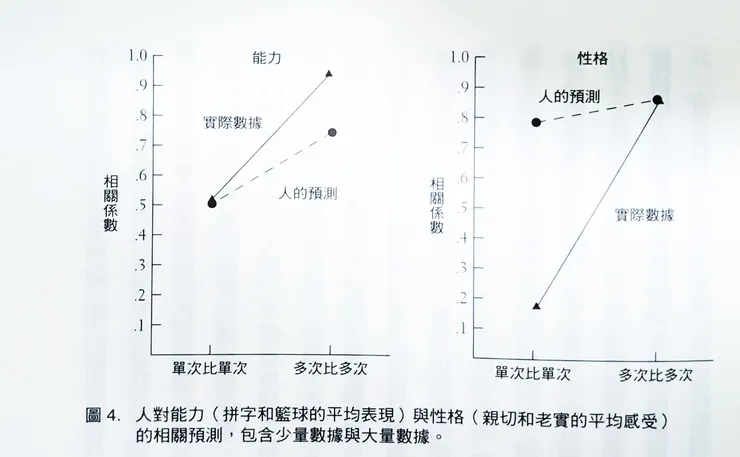
預測慣性
人們對於他人的預測會有個慣性,這也會影響我們的詮釋方式,來看兩個例子。
問題一:如果在球季中前二十場A君的得分比B君高,那麼A君在接下來二十場依舊比B君高的機率大概是多少?
問題二:如果初次見面時A君感覺相處下來比B君還要親切,接下來A君還是比B君親切的機率大概是多少?(我知道這很難量化,但就試著回答看看吧!)
人往往認為他人的能力會隨情況變化大,對於他人性格的預測則認為比較穩定。但事實卻剛好相反,人們的能力通常不會變化太大,觀察越多次越準確,然而性格卻會因爲認識越久而看到這個人越多不同的樣貌,甚至初次見面更容易受到距離感、初次見面、見面場地等等背景因素所影響,所以不能從少量行為性格去判斷這個人「就是」怎樣。
實驗問題
如果我們要做出一個結論若A則B,例如「把商品擺在結帳櫃檯附近會賣得比較好」,要怎麼得出呢?簡單來說就是做實驗嘛!實驗解讀的方式有很多種,書中分為自然實驗、真正實驗、隨機控制實驗與多元迴歸分析四種。

自然實驗
有些實驗是在自然沒有特意處理的情況下產生的,例如對抗天花的過程,是金納醫生發現擠牛奶的女工很少感染天花,這才懷疑是不是感染牛痘能夠讓身體對抗天花。於是金納醫生用了看起來很違反現在道德的方式,找了個小男孩,讓他先感染牛痘後再接觸天花病毒,果真第一次感染牛痘後雖然有發燒,但是之後感染天花時卻毫無症狀。這種基於觀察自然情況下所發現的實驗相當具有效力。
真正實驗
比起自然實驗,真正實驗聚焦在觀察對象上,通常要處理的情境不會自然發生,例如我想要測試一款新藥是否有效,但不會有人無緣無故吃到新藥,所以只能找受試者來吃吃看,觀察會有怎麼樣的結果。
隨機控制實驗
最常見的隨機控制實驗就屬AB測試,這是經由改動一小部分,來看看結果會怎樣變化的方式。例如我想知道洋芋片擺在入口右側、入口前方、入口左側哪一邊可以賣比較好,我就可以利用更改商品的陳列位置來進行實驗,經由最後的銷售結果得出結論。
當然可以改變的因素很多,牽涉到的因素也很多,例如不同時節洋芋片的購買量、當季的促銷活動、競品的拍賣行為、不同的分店、對照組與實驗組的順序等等,都可能是影響因素,我們只能盡量保持其他因素(通稱為誤差變異數)都是相同的。
統計上對象有沒有相互獨立也是要注意的點,盡量每次實驗觀察對象選的不要彼此互相影響,例如商品個數有限、走道狹窄只能讓一人拿取購買等等,都可能是會影響消費者購買的因素。
另外,當受試者人數或次數越大時,AB測試的威力就越強大,能夠減少隨機誤差。例如只觀察一百次的購買行為跟一億次的購買行為,後者的數據若有比較大幅的變化,就表示AB測試的效果較為顯著,然而次數太少的情況下,就很難判斷這次消費者的行為改變只是剛好想換口味還是真的受到擺放位置影響。
多元迴歸分析

這是一種分析方法,實驗人員透過將想觀察的結果設為依變項,可控制的原因設為自變項,觀察兩者間的變化。使用多元迴歸分析的最大限制就是要將每一個可能的影響因素「控制住」。
例如想要觀察抽煙、喝酒、嚼檳榔三個自變項與死亡機率這依變項的關係,如果我們假定抽煙越多、喝酒越多死亡機率越高,結果可能會這樣嗎?說不定不會。因為影響死亡的因素還有很多,例如疾病、肥胖、血壓過高等等都是現代容易造成人們的死亡因素。所以在觀察數據結果時會發現,即便把抽煙、喝酒、嚼檳榔的觀察數值控制住,其死亡機率的變動還是很大,這種多元迴歸分析就不值得相信。
除了確認每個自變項都控制住以外,還要考慮每個自變項之間是否相關,如果具相關性就必須考慮進迴歸分析裡頭,變成很複雜的數學分析,而這關聯性的數值也是很難以被找到的。
多元迴歸分析一樣有每一項自變項數值與依變項數值的相關係數,然而相關係數正如前述所講,並不能代表說兩者就有肯定的因果關係,例如抽煙一定會死亡,還是要靠其他說明去輔助才能說明兩者的因果關係。
實驗中的偏誤
上面講了幾種實驗的方式,我們來講講這些實驗裡面比較容易遇到的偏誤。
- 假定多半錯誤:例如「若懲罰加重,則犯人願意改邪歸正」這樣的假設是正確的嗎?往往我們直覺認為是正確的事情,可能是錯誤的。後來利用了上面的隨機控制實驗發現,加重罰責不僅不會讓犯人改邪歸正,反而更容易讓犯人多了報復心態、失去回歸社會的能力。
- 觀察即偏誤:有個很有趣的例子是「老闆來評鑑員工時,員工會表現得特別認真」,所以「觀測」這件事情本身就可能會影響實驗的結果。
- 盲目試驗:為了避免比馬龍效應、自我應驗效應、觀察者偏差效應等等,在真正實驗中為了避免受實驗人員影響而導致實驗結果的產生偏差,所以發展出來雙盲、三盲試驗,在數據公佈之前,受試者、實驗人員、數字分析員可能都不清楚到底誰拿到的是真東西、誰拿到假東西。
- 參照框架:在問「你最近過得好嗎?」之類的問題時,人們傾向找最近且有印象的事情去比較,又或者跟身邊的人比較,甚至只是現在外面天氣是晴天,比昨天好我們可能就會回答「是」。因為這個答案並沒有客觀結果,所以當在想這個問題時,我們會受到參照樣本的比較來回答,甚至人們潛意識框架傾向回答「是」也有可能造成誘答。
- 言詞不等於行為:有些時候我們做實驗會採口頭詢問,但往往詢問的結果是「人們傾向表現出的那一面」,實際上的行為並非如此。例如問路人想吃什麼,大家都會盡量說自己想吃健康的東西,但其實可能更想吃麥當勞。
- 臨場建構:態度與內容有時是臨場建構的,例如別人問你怎麼會做出現在的職涯選擇時,有時你覺得自己的答案太膚淺「就考上啊」「就覺得這邊校園漂亮」「就想賺大錢啊」,就會改以其他比較合理的講法來建構自己選擇的過程。
- 自我選擇偏誤:多元迴歸分析再選擇自變項的時候,研究人員只能選擇自己看得見的自變項,卻容易忽略自己沒觀察到的自變項,導致結果失準。
- 觀察者偏差效應:觀察者容易將實驗結果帶往自己所想證明的方向。
實驗的綜合比較
就上面的實驗方法進行比較,其效力由好到壞依序是自然實驗、真正實驗、隨機控制實驗、多元迴歸分析,但容易執行的程度就恰恰相反。多元迴歸分析雖然效力最差,但調查起來最快、最容易,又或者有些牽涉人數過多、因素難以控制時都會採用這種方法。隨機控制實驗則是比較需要花時間去看看結果的變化。真正實驗則需要有夠大的樣本數,像是安慰劑或者是新藥上市的三期臨床試驗這種大規模的,都需要開銷相當大的成本。至於自然實驗則是可遇不可求,有些你想要處理的問題剛好自然情況下就會出現才能使用這樣的實驗方式。
結論
喔!這篇終於寫完了,我一月就在看這本書,二月看完,結果四月初寫第一篇到現在五月初才把上中下三篇全部補完,拖這麼久我對不起大家XD。回到這本書,今天講的這些詮釋問題與實驗問題最重要的應用在於看完這些例子之後,將來面對類似的問題,能不能夠回想起這些例子,並意識到對方講的是錯的(當然要怎麼回應就又是另外一回事了)。除此之外,看見自己的思考習慣與框架,也有助於在我們將來回答問題時,能夠稍微思考一下「這樣的講法是不是有點怪怪的?」。
三篇綜合下來,講的是對於資訊處理的方式,一般分為客觀與主觀。客觀的內容就屬於今天的如何去進行實驗,並且正確的加以詮釋得出結論。然而生活中那麼多事情,不可能每件事情都客觀觀察,大多時候眼前的立即回應我們只能依靠主觀的訊息處理,而這些又牽涉到我們意識、潛意識與框架的運作,其中框架的影響之大,從東西方的文化差異讓兩邊人習慣從各自的整體觀、個別觀來解讀事情。
這些思考方式真的是集思考之大全,在商業上、情感上、人際上、學習上幾乎適用,不枉費我覆讀這麼多遍,應該翻到快把整本書背起來了吧!這本書真的超推,你也快去買吧!沒業配的我都少見地大推了!
難易度:★★★★☆
可讀價值:★★★★★
保存價值:★★★★★
書名:《聰明思考》 《MINDWARE: Tools for Smart Thinking》
副標題:《大師教你100多種關於生活、財富、職場、人生的智慧推論新制工具,讓人做出正確抉擇》
作者:李察・尼茲比 Richard Nisbett
出版社:遠流出版
我累了不問問題了,喜歡的話幫我按讚收藏,愛你~

























