Reinforcement Learning (強化學習) 的理論非常有趣,可能是因為其中許多方法,與人類的學習歷程極為相似,如試錯,獎懲,改進策略,持續優化等等。現在準備來爬這座山了,我把學習階段大致分成三個小山峰,依序為 Q-Learning --> DQN --> Actor-Critic,準備好好享受這段旅程。
小孩乖乖就有獎賞,小狗坐好就有點心,小生命的習性,自然而然就被塑造了;若再加上負面的「懲罰」效果更加立竿見影,這是很初階的學習行為。概念延伸,一個人能夠努力不懈,得到傲人的成就,不也是「社會」這個環境不斷給予回饋的結果嗎?所以「環境」中的「行為」加上「獎懲」,應該可以算是學習過程中,非常底層的邏輯。雖然現實世界中,似乎很多「努力卻得不到回報」,「環境詭譎觀察不出頭緒」的狀況,但其實原則並未失效。
比如說「錢多事少離家近」可能是許多人的有效獎賞,但對於某些歷盡滄桑人士,或是功成名就人士,獎賞已經失效,取而代之的也許是,平靜與恬淡的舒爽自在,才能給予最大的生活驅動力。其實因著看世界的角度改變,「環境」維度也就跟著改變,也許從來沒有「客觀存在的事實」,當事人完全可以主導,對環境結構的認知,而形塑獨特的一套「行為 -> 獎懲」的機制。對環境的認知,可以到「見山不是山」的境界,行為可以是「心思裡的柔細思想」(沒錯,思想是是一種內部行為),獎賞可以是「自我實現的意義感」等等。總之,這門學問很有意思就是了。
Q-Learning
在開始爬山以前,當然要先準備一些裝備,數學就是輕薄短小,功能強悍的好工具,用精簡的代號描述複雜的現象。在一個環境狀態 S (State) 中,做出動作 A (Action),得到獎賞 R (Reward),然後環境因著動作的影響,就變成 S′ 狀態,如此週而復始,無限循環。當然我們可以設定一個終止條件,讓遊戲結束,但數學的領域是可以處理「無限步數」的情形,非常強大。而隨著學習步驟的進行,期望做出的動作將越來越好,所謂的好,不僅是使「當下立即」的獎賞最大,更要考慮未來的每一步能獲取的獎賞,合理的期望就是「未來無限步的獎賞」總和。
而很久之後的獎賞,不應該跟立即性的獎賞,產生同樣的效益。比如說某個投資策略,將在「一百年後」,產生驚人效益,使當事人成為富翁!這是無意義的,也許只會讓「當事人的兒子」成為富翁,所以效益應該是隨著步驟的進行而遞減的。描述此現象只要引進「效益遞減因子 𝛾 」(gamma),0 < 𝛾 < 1,第 t 步驟就乘以 𝛾 的 t 次方,如此得出以下這個優美的式子,就是鼎鼎大名的 Q-value:
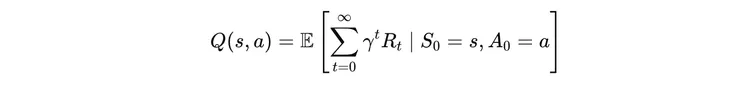
意義就是在環境在 s 狀態下,做出 a 動作,產生立即獎賞 R,和未來每一個步驟,打折的 R,加總起來的期望值。期望值,是因為未來每個步驟所採取的 Action 有隨機成分,其計算就是靠不斷遞迴的實驗,蒐集 Reward 而得,這種算法就是經典的 Bellman Equation:
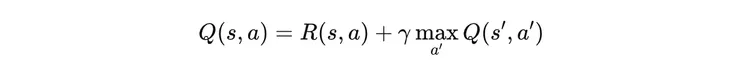
在一個陌生環境中,每一個動作會產生的回饋皆不知,只能隨機亂試,也就是 Q 的初始值是隨機給定的。但隨著試驗的次數增多,回報的平均值就會逐步趨於穩定,然後就可以選最大 Q-value 的動作執行。但如此又產生了「先入為主」的問題,比如說,像吃角子老虎的多選一遊戲,或類似多個廣告版位的選擇問題,先得獎的或先被點閱的選擇動作,因為被賦予的 Q-value 比較高,就會「永遠選擇」,而其他選擇有可能更好,只是因為初期探索,「尚未發現」而已。這是個困難的問題,就是探索 (Exploration) 和利用 (Exploitation) 的兩難。若我們只有有限賭注的機會,比如說 100 元可以賭 100 次,到底先用幾次隨機探索,再根據探索結果去下好注?這沒有答案,難啊。(好像人生,幾歲要嫁娶啊?要交幾任才夠啊?)
所以此模型多了一個參數 ε (epsilon) 用來表示「隨機探索」的機率,只能靠人工憑經驗設定。而隨著實驗次數的增加,這探索機率也可以遞減,所有再加一個 ε 遞減因子,當「經驗非常豐富」時,就不再需要探索了,除非環境又產生結構性變動,才需要重新探索。這個過程,非常合理也充滿美感。以下為當選定某個動作後,Q-value 更新的邏輯,由原本的 Q-value,加上「與新的 Q-value 的差值」乘以 α ,α 就是「學習率」:
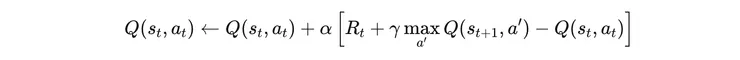
爬呀爬,以上已經完成 Q-Learning 的全部過程。如果 State and Action 的數量是有限且不是誇張多的狀況下,只要用一個 Q-table 紀錄 Q-value 更新的結果,可以輕易地解決。如「井字遊戲」這種問題,隨便訓練個幾百次就永不會輸了。這之前做過,但不需在此著墨過多,因為顯然問題太過簡化,現實世界的大部分問題,根本就列舉不出來,到底有幾種狀態!比如以投資問題來說,「當前的市場狀態」,這啥,有幾種?n 種嗎,無限種吧。如此 Q-Table 已經無用武之地了,需要來攀第二個山頭:DQN。
DQN
DQN (Deep Q-Network) 就是把原本用「查表」的 Q-value,改為一個神經網路,基本觀念就這樣而已。但幾個衍伸的問題必須解決:一是訓練的目標值如何決定,二是資料量如何提升。
Q-Learning 的任何一個列舉的 (S, A),目標值皆可精確算出,如規定某個迷宮遊戲,達到目的的那一步獎賞值就是 1,其他步數也能遞迴的算出;經由 Q-value 現值與目標值的差異計算,可順利完成訓練程序。而 DQN 的情形呢,其現值是取決於特定的 (S, A),加上神經網路的參數 θ,以式子 Q(s,a;θ) 表示,而其目標值呢?會用到同樣的網路,只是輸入變成 s′ 和「所有可能的 a′」,取最大的輸出值為主。如此導致在每步驟優化網路參數的同時,目標也不斷改變!當學習基準不固定,結果可想而知,就是容易「大幅震盪」,誤差值不易收斂,學不到規則。
因此 DQN 引入另一個網路,稱為「目標網路」,其結構與主網路一模一樣,只是在訓練過程中不要每次更新參數,而是每隔一段時間才更新一次,且是將主網路的參數,原封不動的 copy 到目標網路。也就是在學習的初期,先假設一個目標,因為有學習率 α 小於 1 的關係,學習的方向會介於「經驗值」與「假設的目標」之間;而在一段時間之後,把學習結果保存下來,作為新的目標,如此不斷重複,可使誤差值比較容易收斂。基本上還是「自己跟自己學習」的神奇過程,覺得會設計出這種算法的人,真的很厲害。
以上是針對「目標值」的巧妙設計,接下來要設法增加「資料量」,因為神經網路需要大量資料才能發揮效果。基本想法就是盡量「重複利用」既有資料。假設以金融交易日頻資料為例,雖然是典型的時間序列,但對於「狀態」的判斷是否真的跟時序資料相關?這取決於對狀態「屬性」的設計,我想應該是可以找到不相依於時序關係的屬性描述的。假設每一天面對金融市場盤面時,都能就當下的狀況「就事論事」,而不是被已經過去的事影響決策,這應該是還不錯的態度。因此每一組資料,包含 (S, A, R, S′),應該可以儲存起來,重複隨機抽取以供訓練。
以上已經大致爬了兩個山頭,觀念建立的差不多了,下次要進到程式實作部分,實際在金融交易的領域把它套用上去。站穩腳步之後,再來爬 Actor-Critic 這第三個山峰。
Newman 2025/4/1
導覽頁:紐曼的技術筆記-索引
就是先建立基本觀念,而先搞清楚其中一些名詞的定義,是很好的方法。第一個名詞稱為「環境」,數學代號為 S (State)。

























