兩款最新的開源大型語言模型正以其突破性的能力,掀起一場新的風暴:阿里巴巴的 Qwen3-235B 系列,以及月之暗面的 Kimi K2。它們以其「開源」姿態,將頂尖 AI 技術推向更廣闊的開發者與研究社群。這兩款模型代表了當前 AI 發展的兩大重要方向:一是追求更通用的理解與推理能力,另一則是專注於打造更強大的智能代理。TN科技筆記帶各位來深入了解這兩款模型,幫助你掌握 AI 領域的最新趨勢。
Qwen3-235B:全能型選手的再次進化

Qwen3: Think Deeper, Act Faster
由阿里巴巴雲「通義千問」團隊打造的 Qwen3 系列,其中旗艦模型 Qwen3-235B-A22B 在 2025 年 4 月 29 日首次亮相,並於 7 月 21 日推出了最新的 Qwen3-235B-A22B-Instruct-2507 更新。這是一款基於 MoE(Mixture-of-Experts,專家混合)架構的模型,總參數高達 2350 億,但在推論時僅啟動 220 億參數,實現高性能與高效率的平衡。Qwen3-235B 的核心亮點是其獨特的「混合思考模式」(Hybrid Thinking Modes),能夠在需要深度推理的複雜任務(如數學、程式碼)和需要即時回應的對話場景之間無縫切換。此外,它在多語言支援方面也表現出色,訓練數據涵蓋 119 種語言和方言,語料庫規模達到驚人的 36 兆 token,顯示其放眼全球市場的野心。Qwen3 系列採用 Apache 2.0 許可證開源,高度自由的授權方式讓它迅速成為開發者社群的新寵。
Kimi K2:智能代理的破局者

Kimi K2: Open Agentic Intelligence
緊隨其後,由中國新創公司月之暗面(Moonshot AI)於 2025 年 7 月 12 日發布的 Kimi K2 模型,同樣採用 MoE 架構的模型,雖然總參數高達 1 兆(10000 億),但每次推論僅啟動 320 億參數,展現出極致的稀疏性設計。
Kimi K2 的設計理念明確:專注於「智能代理能力」(Agentic Capabilities)。它能自主執行多步驟任務,例如程式碼撰寫、數據分析,並能靈活運用工具。這得益於其創新的「MuonClip 優化器」以及專為智能代理任務設計的訓練範式。開發社群對其在代理與程式碼領域的強大表現讚譽有加,甚至認為它在某些方面已超越了部分閉源模型。
核心技術剖析:MoE、思維模式與智能代理的幕後推手
這兩款模型之所以能夠達到領先地位,都離不開其背後精妙的架構設計與訓練創新。
Qwen3 的「混合思考模式」與多語言支持
Qwen3-235B 的 MoE 架構包含 128 位專家,每次推論過程啟用 8 位專家。其最引人注目的創新無疑是「混合思考模式」。這個機制允許模型在「思考模式」(Thinking Mode)下進行分步推理,適用於數學、邏輯推理等需要深度思考的複雜問題,此時模型會花費更多時間以確保結果的準確性;而在「非思考模式」(Non-Thinking Mode)下,模型則能快速提供近乎即時的回答,適合對話、資訊檢索等對速度要求較高的場景。這種靈活性讓使用者能根據任務需求,在模型響應速度和深度之間進行動態平衡。值得注意的是,其指令微調版本 Qwen3-235B-A22B-Instruct-2507 則不具備明確的「思考模式」開關,而是設計為直接提供答案,顯示阿里巴巴在特定模型變體上追求特定優化的策略。
此外,Qwen3 龐大的 36 兆多語言訓練數據集是其能夠處理 119 種語言和方言的基礎。這不僅僅是一個「功能」,更是一個戰略性的佈局,將 Qwen3 定位為真正的全球性 AI 解決方案,以滿足全球多元語言市場的需求。
Kimi K2 的「MuonClip 優化器」與智能代理訓練
Kimi K2 雖然總參數達到 1 兆,但其 MoE 架構的稀疏性高達 32:1000,即每 token 僅激活 320 億參數。這使得它在極端規模下仍能保持高效推論。其最核心的技術創新是「MuonClip 優化器」,特別是其中的「qk-clip」技術。這項技術透過在每次更新後重新縮放查詢 (Wq) 和鍵 (Wk) 的權重矩陣,來穩定注意力分數,從而實現了萬億參數模型在極大量數據(15.5 兆 token)上的穩定訓練,解決了大型模型訓練中常見的「注意力 logits 爆炸」問題。這被視為一個數學上的突破,強調底層優化演算法對 LLM 擴展能力的關鍵作用。
Kimi K2 的另一個重大特點是其「智能代理訓練」。模型在涵蓋數百個領域、使用數千種工具的模擬場景中進行訓練,包括 API 調用、Shell 命令和 SQL 查詢。高品質的互動數據由一個 LLM 評審模型進行篩選。這種專業訓練賦予 Kimi K2 自主分解複雜任務、選擇合適工具並糾正錯誤的能力。它展現出獨特的「任務執行韌性」,即一種「行動偏好」,能夠不知疲倦地執行多輪迭代搜索和指令,而非僅僅依賴現有知識。這將 LLM 從被動的資訊提供者轉變為主動的問題解決者,能夠執行複雜的多步驟工作流程。
參數規模與上下文窗口的軍備競賽
兩款模型都在參數規模和上下文窗口上持續推進界限。Qwen3-235B 原生支援高達 262,144 個 token 的上下文窗口(262K),這對於處理超長文檔或程式碼庫相當重要。Kimi K2 其上下文窗口也達到 128,000 個 token(128K),同樣能高效處理大量資訊。這些數字共同反映出業界對「長上下文」能力的高度重視,因為它直接決定了模型處理複雜、多層次資訊的能力。
基準測試對決:誰是各領域的真正霸主?
在當前競爭激烈的 AI 領域,基準測試成績是衡量模型實力的重要指標。Qwen3-235B 和 Kimi K2 在各自專長的領域都展現了令人印象深刻的表現。
Qwen3-235B 的綜合實力展現
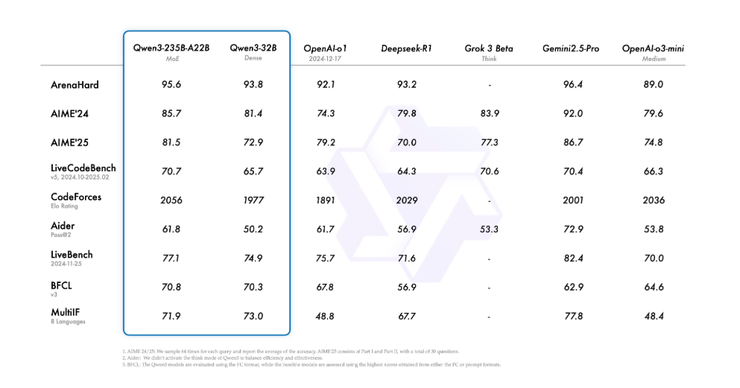
Qwen3-235B-A22B 在「思考模式」下,面對 MATH-500、AIME(數學競賽)、LiveCodeBench v5(程式碼)和 CodeForces(程式碼評級)等多項基準測試時,與 OpenAI-o1、DeepSeek-R1、Grok-3-Beta 和 Gemini2.5-Pro 等領先模型相比,表現出高度競爭力,甚至在多數情況下超越它們。例如,在 AIME'24 和 AIME'25 測試中,Qwen3-235B-A22B 分別獲得 85.7 和 81.5 分,幾乎超越了所有比較模型。
Qwen3: Think Deeper, Act Faster
更令人驚訝的是,Qwen3-235B-A22B 在「非思考模式」下的表現。它在 23 個基準測試中有 18 個超越了 GPT-4o,這表明即使不進行多步驟推理,模型本身也具備強大的固有能力,這對需要快速、直接回應的應用場景提供了巨大的效率優勢。
Kimi K2 在代理與程式碼的突出表現
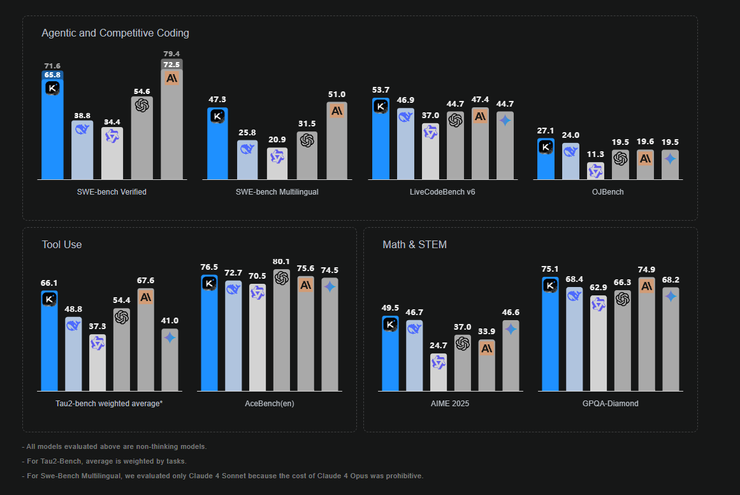
Kimi K2 則在軟體工程和智能代理任務上展現出卓越的性能。在 SWE-bench Verified 基準測試(軟件工程)中,Kimi K2 的 pass@1 分數達到 65.8%,與 Claude 4 Sonnet 持平,並超越 DeepSeek-V3 (56.1%) 和 GPT-4.1 (40.8%)。在有重試機會的情況下,其 SWE-bench 表現甚至達到 71.6%。這證明了其在自主程式碼開發和錯誤修復方面的強大能力。
Kimi K2: Open Agentic Intelligence
在數學推理方面,Kimi K2 在 MATH-500 上獲得 97.4%,超越 GPT-4.1 的 92.4%。對於程式碼任務,它在 LiveCodeBench 上獲得 53.7%,同樣超越 GPT-4.1 (44.7%) 和 DeepSeek-V3 (46.9%)。Kimi K2 在 AceBench 和 Tau-2 Bench 等代理任務上的出色表現,進一步證實了其作為智能代理的領先地位。尤其是在創意寫作和寫作基準測試上,Kimi K2 表現略優於 Qwen3。
TN科技筆記的觀點
- MoE 架構的成熟與普及: Qwen3 和 Kimi K2 都採用 MoE,且取得了令人信服的性能,這可能代表 MoE 將成為未來 LLM 的主流架構之一,尤其是在追求極大規模與推論效率的平衡時。
- 開源力量的崛起: 兩者都是開放權重(Open-weight)模型,這大大降低了開發者和研究人員進入尖端 AI 領域的門檻。這種趨勢將加速全球 AI 的創新速度,並可能孵化出更多樣化、更具針對性的應用。
- 專業化與通用性的並行發展: Qwen3 嘗試在通用性(多語言、混合思考模式)上做到極致,而 Kimi K2 則在智能代理、程式碼和優化器創新上實現了深度突破。這說明 AI 發展不再是單一賽道,而是走向了通用能力與垂直領域專業化並重的格局。
支持TN科技筆記,與科技共同前行
我是TN科技筆記,如果喜歡這篇文章,歡迎留言、點選愛心、轉發給我支持鼓勵~~~也歡迎每個月請我喝杯咖啡,鼓勵我撰寫更多科技文章,一起跟著科技浪潮前進!!>>>>> 請我喝一杯咖啡
在此也感謝每個月持續請我喝杯咖啡的讀者們,讓我更加有動力為各位帶來科技新知!





















