

協作關係:不是取代,而是互補
• ESLint 負責第一線的「防禦」,確保團隊代碼風格一致,且沒有低級語法錯誤。
• Claude Code 負責深層的「代碼評審 (Code Review)」,確保系統架構合理、沒有邏輯漏洞,甚至能根據自然語言指令直接完成複雜的功能開發。
🧠 核心概念:從「單兵作戰」到「專家團隊」
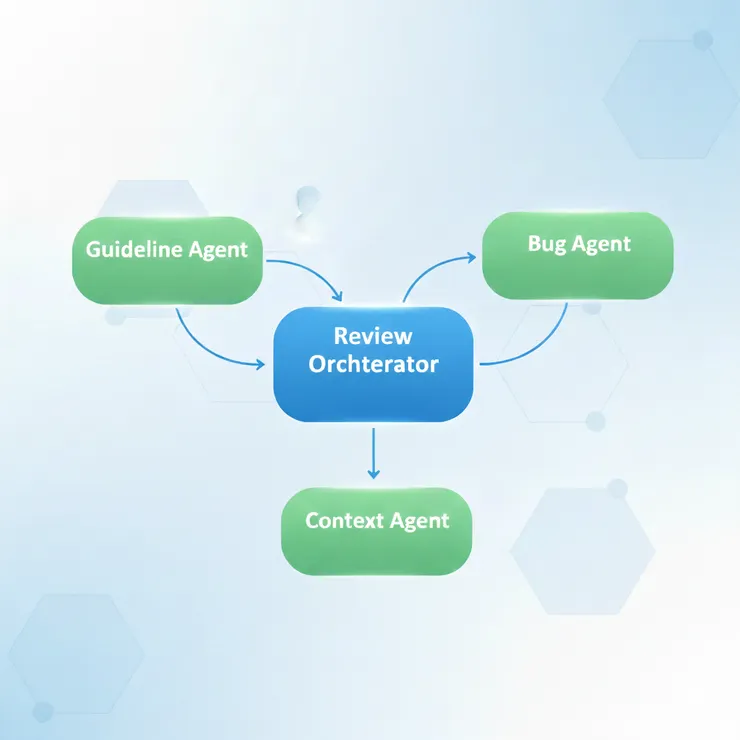
Multi-agent 協作:並行分析的深度
• Guideline Agent:它會先掃描專案中的 .editorconfig、README 或自定義的 CONTRIBUTING.md,確保建議不會違背團隊既有的命名慣例。
• Bug Agent:專攻「邊界情況」(Edge Cases)。例如:當它看到一個 API 請求,它會同步模擬「網路斷線」、「回傳 500」等場景,看你的代碼是否能存活。
• Context Agent:這是最強大的部分。它會去翻閱 Git Tree,理解這段代碼在兩週前是為什麼被改動的,避免給出「回歸性錯誤(Regression)」的建議。
Confidence Score (置信度評分):內建的質量過濾器
這是專業工具與玩具的分水嶺, 模型在內部生成建議時,會對該建議的準確性進行數學建模, 系統會計算出信心權重, 其中:
• 內部打分機制:當模型產生一條審閱評論(Comment)時,它必須同時輸出一個 0.0 ~ 1.0 的分數。
• 嚴格門檻:系統預設會丟棄低於某個閾值(通常是 0.8)的評論。這解釋了為什麼 Claude Code 的 Noise(雜訊)比一般 AI 工具低, 它寧可保持沈默,也不願給出錯誤的建議。
🛠️ 環境準備:工欲善其事,必先利其器?
在 Claude Code 的架構中,code-review 被定義為 「核心插件 (Core Plugin)」,這意味著:
• 當你安裝了 claude-code CLI 時,code-review 的功能就已經存在於系統中。
• 它不像 VS Code 需要去 Marketplace 下載。它更像是一種 「能力 (Capability)」,只要你在 Git 專案目錄下啟動 Claude,它就會自動加載這個插件。
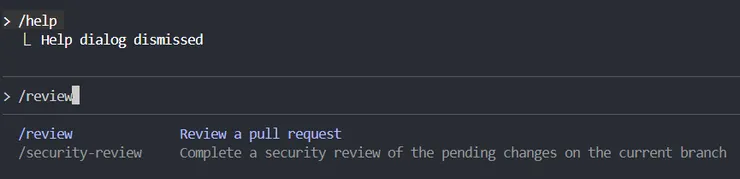
如何確認插件已啟動?
當你啟動 claude 並進入互動介面後,你可以輸入 /help,你會看到 /review 已經列在可用的斜槓指令中。
🚀 實戰演練:常用的情境有這些
我們會實際以「【🧠 LLM智能應用系列】Spec-Kit × FastRTC:打造高效語音 VoiceBot」分享的專案來進行Code Review的實際演練, 讓我們兼顧品質與功能吧!
審閱整個工作目錄
如果你想讓 Claude 掃描目前所有改動過(包含未 add)的檔案:
/review workdir
以 https://github.com/weihanchen/ai-voice-assistant-fastrtc 為例:
/review src/voice_assistant/handlers
針對我們目錄內的程式碼評估其優缺點與改善之處。

甚至進行安全性檢核與綜合評分。

針對特定的 Commit 或 分支
如果你想看目前的開發分支(Feature)跟主線(Main)差在哪:
/review main..feature-branch
🎯 進階心法:調教你的 AI 審查標準並讓AI自動執行
調教的核心主要圍繞在一個名為 CLAUDE.md 的檔案, 假設你有使用 AGENTS.md 這類的標準文件, 也可以在裡面進行定義即可。
我們可以按照底下模版放入 AI Guideline,之後我們在commit之前AI Assistant就會依照這份準則進行代碼審查, 確保我們的軟體品質:
## Development Workflow
### Commit 前流程
1. Code Review - AI 審查
2. 修正問題
3. Lint + Format(pre-commit 自動執行)
4. Commit
### Review 標準
- 邏輯正確性與邊界條件
- 安全性(無硬編碼密鑰、無注入風險)
- 命名清晰度與可讀性
- 符合現有架構模式(BaseTool 繼承等)
- Boolean 命名:`is_*` / `has_*`
我們會使用 https://github.com/weihanchen/ai-voice-assistant-fastrtc/tree/main 這個專案進行示範, 而規則我們也分享在這邊「https://github.com/weihanchen/ai-voice-assistant-fastrtc/blob/main/AGENTS.md」, 歡迎自行取用。
試著提交
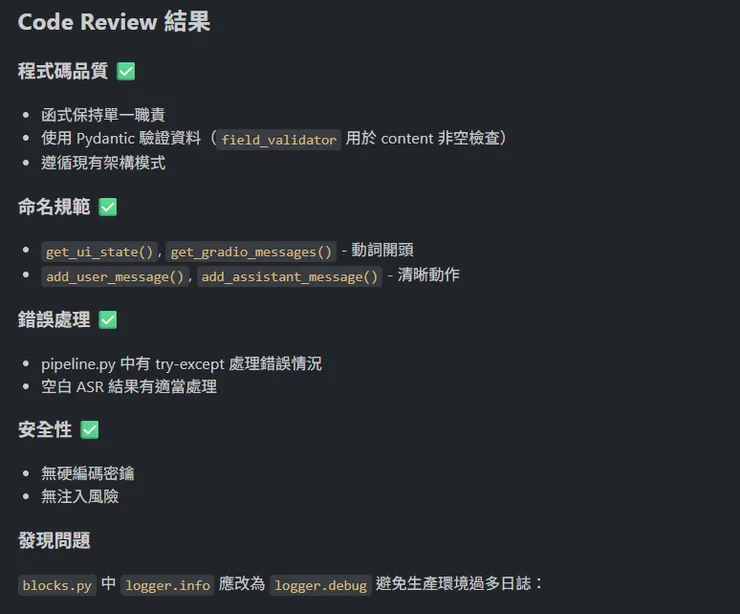
commit提交前, claude code會依照我們的規範進行Code Review:
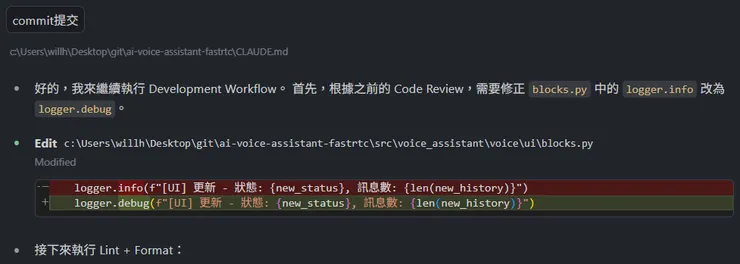
接著會進行修復後, 再執行lint:
完成提交

⚠️ 這邊需要注意,並不是每次提交時, Claude Code都會遵照規範執行Code Review,這也是目前正在想辦法解決的預計工作, 下一個篇章我們會針對這樣的痛點進行改善, 也就是建立一套標準SOP的Skills, 讓我們每次的產出都是一致的, 現階段還是建議我們可以手動進行 /review特定模組。
📌 結語: 從「抓錯」到「決策」,AI 賦予開發者的第二次解放
AI 不是要取代你的審查,而是要終結你的瑣事。
總結這套 Claude Code 插件,它為開發流程帶來了三個關鍵質變:
- ⚡ 雜訊過濾(Precision)
透過 0-100 置信度評分,AI 只會在你真的出錯時發言,拒絕無效的 AI 碎碎念,讓每一條建議都具備實質修正價值。
- 🧠 多維診斷(Multi-Agent)
不只看語法!多個 AI 代理人同步運作:Bug Agent 找漏洞、Guideline Agent 追規範。你得到的不是一個建議,而是一份專業診斷報告。
- 📜 規範自動化(Living Docs)
讓 CLAUDE.md 成為活的法律。規範不再是文件的冷文字,而是 AI 隨時為你站崗的執行準則,確保團隊風格永不走鐘。





























