Chat GPT - 用RLHF做Fine Tuning
回顧ChatGPT回答不是你要的怎麼辦?這篇文章,Chat GPT回答的結果常常不如人意,因此有個Facebook提出的技術,叫做RAG,它是提升Chat GPT回答品質的方式之一,詳細實作步驟可以參照自己做免錢Chat GPT吧。
這次我們來換個方法,今天要介紹Reinforcement Learning from Human Feedback (RLHF)
- 背景
大型語言模型 (LLM)訓練過程中,受到網路提供的資料品質而有影響,此外LLM訓練過程中用到的監控指標BLEU、ROUGE也無法闡述人類對於語言的偏好,這些種種都又發了一種想法:「直接利用人類的喜好、價值觀等等因素來對一段話評分」,這樣的評分資料將有助於LLM的學習。
- 圖示

圖片出處:https://openai.com/index/chatgpt
- 步驟說明
步驟一:訓練Supervised Policy
- 網路上蒐集各種對話紀錄,因此這裡有非常多的Input Pair與Output Pair
- 標註者挑選期望的Output Pair,因此有Input Pair與期望的Output Pair
- 有Input Pair與其對應的期望Output Pair,即可用監督式學習進行訓練
步驟二:訓練Reward Model
- Input Pair匯入其它語言模型,產生諸多Output Pair
- 標註者對每一個Input Pair所對應的諸多Output Pair進行評分
- Input Pair & Output Pair當作輸入而評分作為輸出,即可訓練Reward Model

步驟三:透過Reward Model精進Supervised Policy
- 網路上蒐集各種對話紀錄,因此這裡有非常多的Input Pair與Output Pair
- 以步驟一的結果 - Supervised Policy當作步驟三的起始,並以Input Pair當作輸入 (計為I),匯入Supervised Policy得到輸出語言 (計為O)
- 輸出語言(計為O)連同I一起匯入Reward Model得到語言的評分 (計為R)
- 至次我們已經收集Reinforcement Learning的關鍵要素,分別為I、O、R,因此就能以PPO演算法進行Supervised Policy的品質提升

對於Reinforcement Learning中的Objection Function有必要於這裡特別說明,首先參照圖示:

注意事項:
- 我現在專注要調整的模型為Tuned Language Model,而原先的模型為Initial Language Model,但我又希望兩者之間不要差異太多,於是我用KL Divergence來做約束,而且將PPO Policy置於前位,而Base Policy置於後位,亦即將PPO Policy當作目前真實的機率分佈,而Base Policy作為近似的機率分佈,這部分需要了解Information Theory才可以
- 上圖是以Gradient Ascent為例子,所以一部分的元素是Reward,另一部分是象徵距離的KL Divergence,那因為我希望距離最小化,所以可以看到在KL Divergence那邊會多加一個負號

195會員
510內容數
這裡將提供: AI、Machine Learning、Deep Learning、Reinforcement Learning、Probabilistic Graphical Model的讀書筆記與演算法介紹,一起在未來AI的世界擁抱AI技術,不BI。
留言
留言分享你的想法!
你可能也想看







Google News 追蹤


提供 AI 下指令或提問題的提示(Prompts)範例及介紹相關外掛工具或擴充功能,還有實用的英文句型,讓你跟 ChatGPT 沉浸式練習視訊會議情境英語會話。

提供 AI 下指令或提問題的提示(Prompts)範例及介紹相關外掛工具或擴充功能,還有實用的英文句型,讓你跟 ChatGPT 沉浸式練習求職面試情境英語會話。


提供 AI 下指令或提問題的提示(Prompts)範例及介紹相關外掛工具或擴充功能,還有實用的英文句型,讓你跟 ChatGPT 沉浸式練習海關情境英語會話。


這篇文章探討了情緒勒索的定義、影響及如何應對,以及金錢在情緒索中扮演的角色。情緒勒索是一種心理暴力,它通常發生在親密關係中,例如夫妻、父和子女之間。情緒勒索者會利用他們對受害者的情感依賴,來控制和操縱他們的行為。本文提供了應對情緒勒索的方法,包括學會設定健康的邊界、拒絕情緒勒索者的要求,以及學會自我

本文探討了漫畫《鋼之鍊金術師》中的等價交換概念以及在現實生活中實現等價交換所面臨的困境。文章提到,在漫畫中,等價交換是一個非常重要的概念,人們必須付出相等的代價才能改變物質。然而,在現實生活中,人們的社會地位、財富和權力等因素會影響等價交換的實現。文章強調,真正的等價交換需要追求公平、正義和互惠主義


這段代碼會創建一個黑色正方形,其中包含一個螢光綠色邊條和一個顯示 "Line" 文字的正方形,邊條會逆時針旋轉。使用CSS中的position和transform屬性可以將正方形放置在畫面中央。使用animation屬性可以實現旋轉動畫。


今天,我想要分享一個更為完整的攻略,每次需要花費50分鐘,能夠有效地強化聽、說、讀、寫的能力。


今天文章目的很簡單,就是要其他的題目考倒Chat GPT!證明人類還沒有輸!!不過我知道正常考Chat GPT肯定是不行的,人類根本不是對手,這次就要來玩陰的,用六個題目考倒Chat GPT!!進來看看這場Chat GPT跟人類最終之戰!!
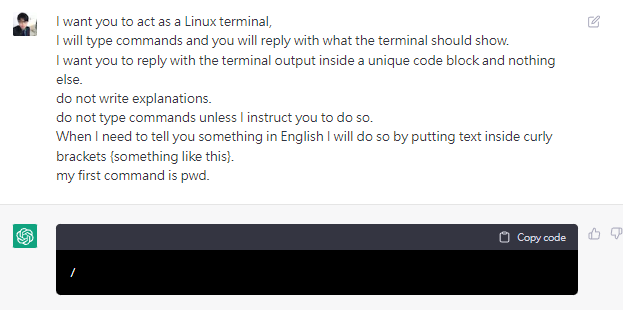
首先可以這樣寫告訴chatgpt你希望他表現得像個linux terminal
不用寫解釋,只要回覆linux terminal應該回復的東西即可
提供 AI 下指令或提問題的提示(Prompts)範例及介紹相關外掛工具或擴充功能,還有實用的英文句型,讓你跟 ChatGPT 沉浸式練習視訊會議情境英語會話。
提供 AI 下指令或提問題的提示(Prompts)範例及介紹相關外掛工具或擴充功能,還有實用的英文句型,讓你跟 ChatGPT 沉浸式練習求職面試情境英語會話。
提供 AI 下指令或提問題的提示(Prompts)範例及介紹相關外掛工具或擴充功能,還有實用的英文句型,讓你跟 ChatGPT 沉浸式練習海關情境英語會話。
這篇文章探討了情緒勒索的定義、影響及如何應對,以及金錢在情緒索中扮演的角色。情緒勒索是一種心理暴力,它通常發生在親密關係中,例如夫妻、父和子女之間。情緒勒索者會利用他們對受害者的情感依賴,來控制和操縱他們的行為。本文提供了應對情緒勒索的方法,包括學會設定健康的邊界、拒絕情緒勒索者的要求,以及學會自我
本文探討了漫畫《鋼之鍊金術師》中的等價交換概念以及在現實生活中實現等價交換所面臨的困境。文章提到,在漫畫中,等價交換是一個非常重要的概念,人們必須付出相等的代價才能改變物質。然而,在現實生活中,人們的社會地位、財富和權力等因素會影響等價交換的實現。文章強調,真正的等價交換需要追求公平、正義和互惠主義
這段代碼會創建一個黑色正方形,其中包含一個螢光綠色邊條和一個顯示 "Line" 文字的正方形,邊條會逆時針旋轉。使用CSS中的position和transform屬性可以將正方形放置在畫面中央。使用animation屬性可以實現旋轉動畫。
今天,我想要分享一個更為完整的攻略,每次需要花費50分鐘,能夠有效地強化聽、說、讀、寫的能力。
今天文章目的很簡單,就是要其他的題目考倒Chat GPT!證明人類還沒有輸!!不過我知道正常考Chat GPT肯定是不行的,人類根本不是對手,這次就要來玩陰的,用六個題目考倒Chat GPT!!進來看看這場Chat GPT跟人類最終之戰!!
首先可以這樣寫告訴chatgpt你希望他表現得像個linux terminal
不用寫解釋,只要回覆linux terminal應該回復的東西即可