前面兩篇會刻意提到共變數,除了因為共變數在多變量統計裡面非常重要之外,最主要的原因其實是為了解釋皮爾森相關係數而做鋪陳。
相關係數的種類也相當的繁多,這裡介紹的皮爾森相關大概是最常看到的一種啦~為了方便起見,這篇文章後續在提到皮爾森相關係數時都會簡稱為「相關係數」。皮爾森相關係數的計算方式
在前一篇文章(統計急救箱──用共變數描述分數之間的關係(下))的最後,提到了共變數有一個不太方便的地方──那就是共變數會受到測量單位的影響,這讓我們沒辦法光憑共變數就知道兩群分數之間的關聯性到底有多高。
那有什麼方法可以消除測量單位的影響嗎?沒錯,就如同之前在介紹標準分數時所提到的,將一個分數進行標準化處理就能夠把單位給消去囉!
那標準化處理要怎麼做呢?就是將一個分數除以標準差。不過共變數裡面包含兩群數值,所以要除以兩群數值的標準差,於是我們就會得到下方的公式:

將共變數除以x和y的標準差就是標準化的共變數
這個公式其實就是大名鼎鼎的皮爾森相關係數公式。也就是說,相關係數就是標準化的共變數。
不過一般來說,分母的SD比較習慣寫成S,所以更常看到下面這樣的公式:

皮爾森相關就是標準化的共變數
公式左邊的r就是習慣用來表示相關性的符號了,r旁邊小小的x和y表示這是x跟y兩群分數的相關係數。
相關係數的特性與強弱
由於做了標準化處理,相關係數就變得很方便了,它讓我們可以直接根據相關係數的大小來判斷關聯性的強弱。不過首先我們要先知道相關係數的一個有趣特性,那就是相關係數必定會介於-1到+1之間 [*1]。
所以相關係數包含兩個部分,而這兩個部分各自告訴我們一些資訊:1. 正負號(表示關聯方向)。2. 數值(表示關聯強弱)。
正的數值表示正向關聯,x越大y就越大;負的數值表示負向關聯,x越大y就越小(或者x越小y就越大),這部份很容易理解。比較需要解釋的是關聯性的強弱,到底怎樣的關聯性算是高、怎樣算是低?雖然大致上的判斷標準差不多,但不同學者的看法仍有差異,因此往往在描述關聯強弱時也會附上參考文獻表示自己是根據誰的判斷標準來解釋的。
大多數的統計教科書上面都會列出判斷標準或者參考文獻,不過貼心如我特別找了兩個文獻給大家引用,一篇英文一篇中文的。對於相關強弱的判斷標準請見下圖,參考文獻列於文末。
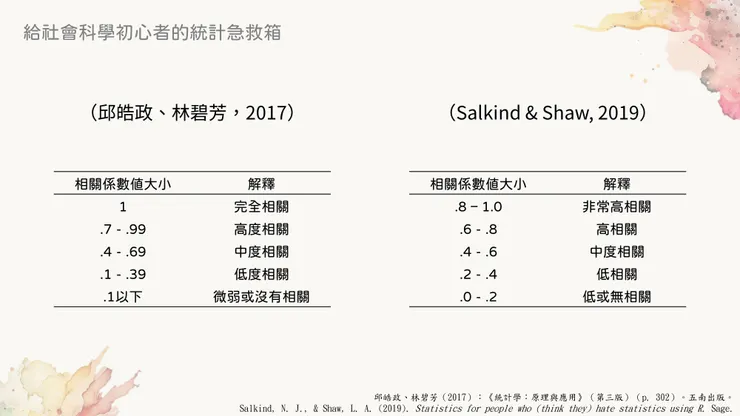
判斷相關高低的標準
可以看到左右兩者在強相關的判斷上面有些許差異。我自己在實務上的習慣是很粗略地將相關分為低、中、高三種,分別以0.4和0.6為界(低於0.4為弱相關、0.4~0.6之間為中等、高於0.6為強相關),這樣對我來說比較好記一些。如果我需要分得更仔細就會再去查書。
需要注意判斷相關強弱時,不會考慮前面的正負號,只會根據數值的絕對值大小來判斷喔!
決定係數
如果把相關係數做平方,會得到所謂的r2,念作r square,中文翻譯為決定係數。
這個r2的意思,其實指的是x和y的變異數重疊的部分。我們用文氏圖來理解會比較清楚:
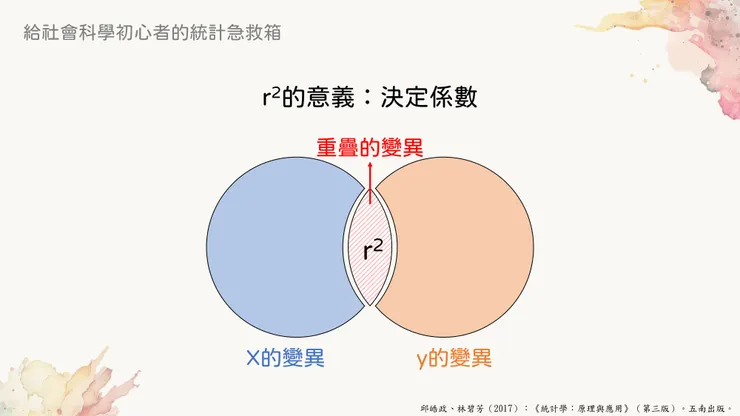
決定係數的意義
左邊藍色的圓代表x的變異數大小,右邊橘色的圓代表y的變異數大小,而中間重疊的部分就是決定係數囉。
有些書本上面會寫說,決定係數代表x的變異可以被y所解釋的程度。之所以會這樣說,就是因為y的變異數和x有所重疊的緣故。不過什麼叫做「解釋變異」,最快應該也要等到變異數分析或者迴歸分析的時候才會說明。以現在而言,這句話的概念其實也可以等同於「x的變異數當中有多少是跟y有關的」來理解。
使用相關係數時的注意事項
首先,我們要知道皮爾森相關係數的使用時機。基本上皮爾森相關係數適用於描述兩個連續變數之間的關聯性。如果x或者y其中之一不是連續變數(如果忘記變數的類型,可以回到統計急救箱─變數與變數類型 複習喔!),那皮爾森相關係數並不是描述他們關聯性的好選擇,應該考慮其他相關係數(例如肯德爾和諧係數、點二系列相關等等)。
另外要注意在使用相關係數時有兩個容易掉入的陷阱。
第一個陷阱──皮爾森積差相關描述的是線性相關,所以係數很低僅能表示線性關聯性很低,未必表示兩群數值之間沒有關聯性。
我們用兩張圖來瞭解這是怎麼一回事。首先假如我有以下四個資料點,並計算x和y之間的相關值,可以得到.94的結果,屬於相當高的相關。
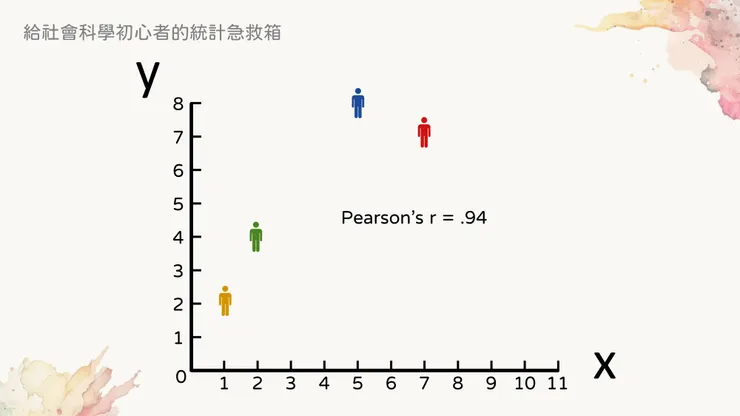
圖中的x和y有相當高的關聯性
這個時候如果我加入下圖中的紫色資料點,會發現相關係數瞬間降到.12,從高相關掉到低相關。可是仔細觀察這五個數值,其實它們之間有可能存在著曲線關係(如紅色線段所示)。在心理學中最有名的曲線相關,大概就是所謂的壓力─表現曲線了,有興趣的讀者可以去查詢一下。
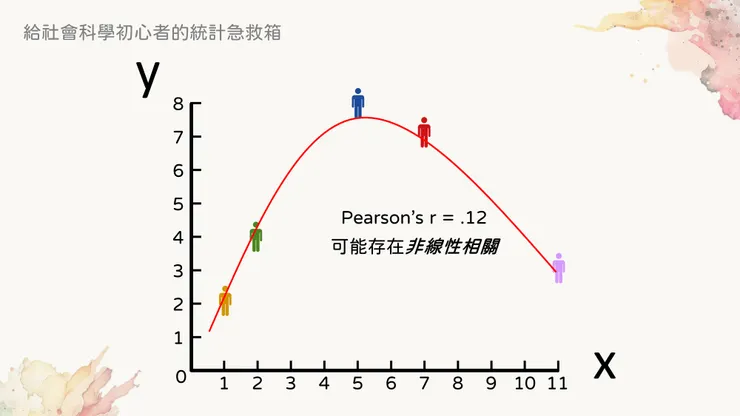
線性相關值很低,但可能存在曲線相關
因此在描述數值相關性的時候,皮爾森積差相關係數只能提供線性關聯性的資訊,還是會建議把散布圖畫出來稍微觀察一下資料點之間是否有某種規律存在。
第二個陷阱──相關不表示具有因果關係

相關不等於因果!
我相信有超過8成的統計書籍,在解釋相關性的時候會特意提到「相關不等於因果」這個觀念。既然大家都有提,那我也要講一下......不是,是因為這件事情真的太重要了。
我先來舉個生活中常見到的例子。假如今天看到一個斗大的新聞標題寫著:「最新研究顯示,遊玩暴力遊戲的時數與暴力認知之間具有顯著的關聯性。」這時候大多數人會非常容易解讀成「研究發現遊玩暴力遊戲會導致暴力認知的增加」。
仔細思考一下,玩暴力遊戲和暴力認知之間有關,就可以認為暴力遊戲會導致暴力認知嗎?其實是不行的,我可以用一個很簡單的方式反駁:也可能是暴力認知比較高的人比較喜歡玩暴力遊戲。除此之外,當然還有其他可能造成兩者有關聯的狀況。
在一些實驗方法或者研究方法的書籍當中,會提到相關性只是判斷因果關係的前提之一 (巴比,2021;Christensen et al., 2015),所以我們不能光是從相關與否判斷因果關係。不過當我們說某兩件事情有因果關係的時候(例如下雨會導致地面有積水),這兩件事情就一定是有關聯的(下雨與地面有積水是有關的)。換句話說,關聯性是因果關係的必要條件,但不是充分條件。
人類是一種很直覺就會去尋找因果關係的生物,在閱讀關聯性的描述時很容易會把先講出來的變數視為因,後講出來的變數視為果。所以相關不等於有因果這個觀念,一定要銘記在心。
我本來以為前面提過標準分數和共變數,相關可以寫得簡短一點,但在構思的過程中又發現有許多重要觀念必須說明,結果不斷的加東西進來...
相關係數其實並不止於此,假如涉及到抽樣(推論統計),在判斷相關強弱之前必須要先判斷相關係數是否為0,不過這部分就先賣個關子,留到t檢定的段落再說明吧。
到相關為止描述統計大概可以先告一段落,接下來會從觀念開始說明推論統計是什麼,之後再介紹推論統計所使用的統計技術。不過描述統計裡的觀念不能忘記,因為之後還是會一直用到它們。
註記
[*1]:這件事情是可以用數學來證明的,不過本文的目的是解除初學者對統計的恐懼,所以沒有打算詳細解釋。有興趣的讀者可以參考《機器學習的數學基礎》與《機器學習的統計基礎》,前者使用向量內積的方式證明;後者則提供柯西不等式和變異數轉換兩種證明方法。
參考文獻
厄爾‧巴比(2021):《社會科學研究方法》(林秀雲譯)。雙葉書廊。(原著出版年:2020)
邱皓政、林碧芳(2017):《統計學:原理與應用》(第三版)。五南出版。
Christensen,L. B., Johnson, R.B., & Turner, L. A. (2015). Research methods, design, and analysis (global edition, 12th ed.). Pearson.
Salkind, N. J., & Shaw, L. A. (2019). Statistics for people who (think they) hate statistics using R. Sage.