↑看個小廣告,支持好內容↑
我們這樣來讀題目:今天班級裡突然闖進一個陌生人,你拿著兩張相片,分別代表正常和「混入陌生人」的狀況,該如何在最快時間內抓出他呢?
威利在哪裡!我們就從有多一個人的照片著手,每看到人就去另一張照片檢查他有沒有出現。這樣確實能找出混進來的人,可是每個人都要重找一次照片,這太花時間了,有沒有比 O(n^2) 更好的做法?
❶ Sorting
老師於是叫大家照座號排成一列,看看會發生什麼:
s="dabe" -> 排列得到 "abde"
t="beacd" -> 排列得到 "abcde"
前兩項都相同,但由於第三項混入了 c,導致往後的項次都沒對上。從中可發現長字串裡,排序後第一個匹配不到的字母,必然是多出來的那個!
最起碼這避免了土法煉鋼,但排列仍需 O(nlogn),通常不會是最佳解。
❷ Hash Table (索引、桶子)
一般為了避免重找,直觀方式就是做個索引表,把看過的資料記錄下來。這通常也是大家的直覺做法:
1. 對 s 出現之字母累加正數
例: map["a"]=1, map["n"]=2 代表字母 a,n 出現 1,2 次
2. 將 t 出現的字母逐一扣除,會出現以下狀況:
1) 索引 key 不存在:代表該字母在 s 未出現過
2) 扣完出現負數:代表該字母在 t 出現次數比 s 多
兩種狀況都表示有找到多餘的字母!這個解法只要遍歷 s,t 字串各一次,複雜度因而降至線性 O(n)。
話說回來,英文字母也才 26 種,開個長度 26 的陣列 (我習慣稱它桶子) 來計數也可以吧?實際上「桶子」和索引是很類似的概念,差別在於索引並不預知總共的類別 (key) 數量,桶子則一開始就定義 26 類並都填上了初始值 0。
❸ Sum
索引很安全穩固,但這題還有其他可愛的方法,記得上篇教過的 ASCII 嗎?假設
- T = Σ (
t所有字母的 ASCII 值) - S = Σ (
s所有字母的 ASCII 值)
最後再反查 T-S 代表哪個字母,一樣可用 O(n) 優雅得出所求。
❹ XOR
位運算的掌握,很有可能替面試畫上點睛之筆!
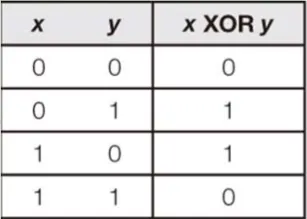
有沒有找到規律?當 x,y 相同時運算結果即為 0,換言之,它能將重複出現的元素成對抵銷,留下落單也就是混入的字母:
// s="dabe", t="beacd"
(d XOR a XOR b XOR e) XOR (b XOR e XOR a XOR c XOR d)
= (d XOR d) XOR (a XOR a) XOR (b XOR b) XOR (e XOR e) XOR c
= 0 XOR 0 XOR 0 XOR 0 XOR c
= c
篇幅不長也易懂的題目,解法居然出奇多種,試著動手一一實作它們,這是一道蘊含許多演算精華的超值經典:)
- 本題分類標籤:
Hash Table、String、Bit Manipulation、Sorting - 本題正解率=
60.4%


























