現在可以靠機器學習的演算法,幫助自己找到筆記中有價值的洞見了。
近期 Obsidian 社群出現了一款非常有意思的插件 — Graph Analysis,它能依靠筆記之間的內部連結 (internal link) 計算相關性,讓我們在自己寫下的筆記中 “挖寶”。
我發現這對於寫「人物筆記」非常有幫助,這篇文章我分別舉張永錫老師、于為暢老師、孫治華老師作為演算法的應用場景介紹。Graph Analysis 是什麼 ?
Graph Analysis 是一款 Obsidian 插件。
開發者 SkepticMystic 基於 NEO4J Graph Data Science 的公開 Library,利用不同的機器學習演算法,去計算你的筆記關聯性。
Graph Analysis 插件中實作了 11 種演算法,一開始看到真的會讓人不知道如何使用。剛好這週看到 Ensley Tan 的文章,他介紹了 3 種應用場景,讓我認識到這款插件是威力非常強大的插件。
詳細的解說可參考 Ensley Tan 的 Medium 文章,下面僅分享最後的使用情境 (知道怎麼使用比較重要)。
我會在這 3 種應用場景加上自己的實際使用方法。
場景 1 : 尋找關聯度高的筆記 (Find very similar notes / clones)
我們能將關聯度高的筆記,整理成一個主題。
Graph Analysis 中有 6 種演算法專門尋找筆記關聯度:
- Co-citations
- Adamic Adar
- Jaccard
- Overlap
- Bag of Words (nlp)
- Otuska Chiai (nlp)
根據 Ensley Tan 實驗,除了 Co-citations 之外的 5 個演算法都可以使用。Co-citations 容易出現離群值,計算出來的筆記結果可能不準確。
我的應用
用來觀察「目前這則筆記」還可能跟哪些筆記產生連結,進而刺激想法。
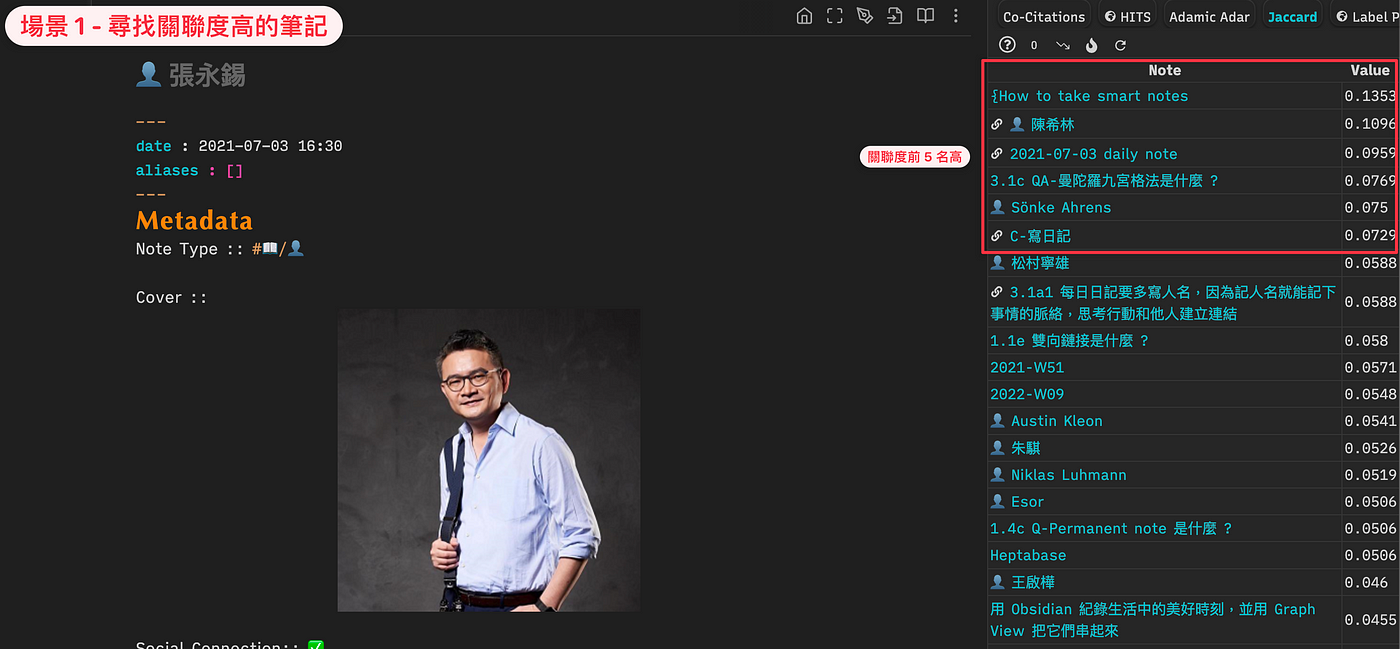
例如我寫「張永錫老師」筆記時,打開 Jaccard 演算法看到以下關聯筆記:
- How to take smart notes (因為這本書,開啟和老師的 2022 遠流出版社書籍翻譯專案)
- 陳希林 (遠流副總編輯,負責和老師/我接洽How to take smart notes 翻譯)
- 2021–07–03 daily note (和老師聊天,知道了他在 Roam Research 實作卡片盒筆記的方法)
- 曼陀羅九宮格法 (老師極度推崇的時間管理、思想整理框架,影響了我今年使用九宮格法的目標設定方式)
- 寫日記 (2017 年第一年開始寫晨間日記,就是受老師的《早上最重要的3件事》啟發)
場景 1 適合用在「補充筆記內容」。
場景 2 : 尋找影響力強的筆記 (Identify influential notes)
影響力指筆記「被連結 (link comes in)」或「連結出去 (link goes out)」的數量多寡。連結愈多,代表影響力愈強。
Graph Analysis用 HITS 演算法來計算筆記的影響力。主要有兩個指數可利用:Authority (權威分數) 和 Hub (樞紐分數)。簡單的說:
- Authority 分數高,表示該則筆記「被連結 (link comes in)」的筆記數量高
- Hub 分數高,表示該則筆記有很多「連結出去 (link goes out)」的筆記連結
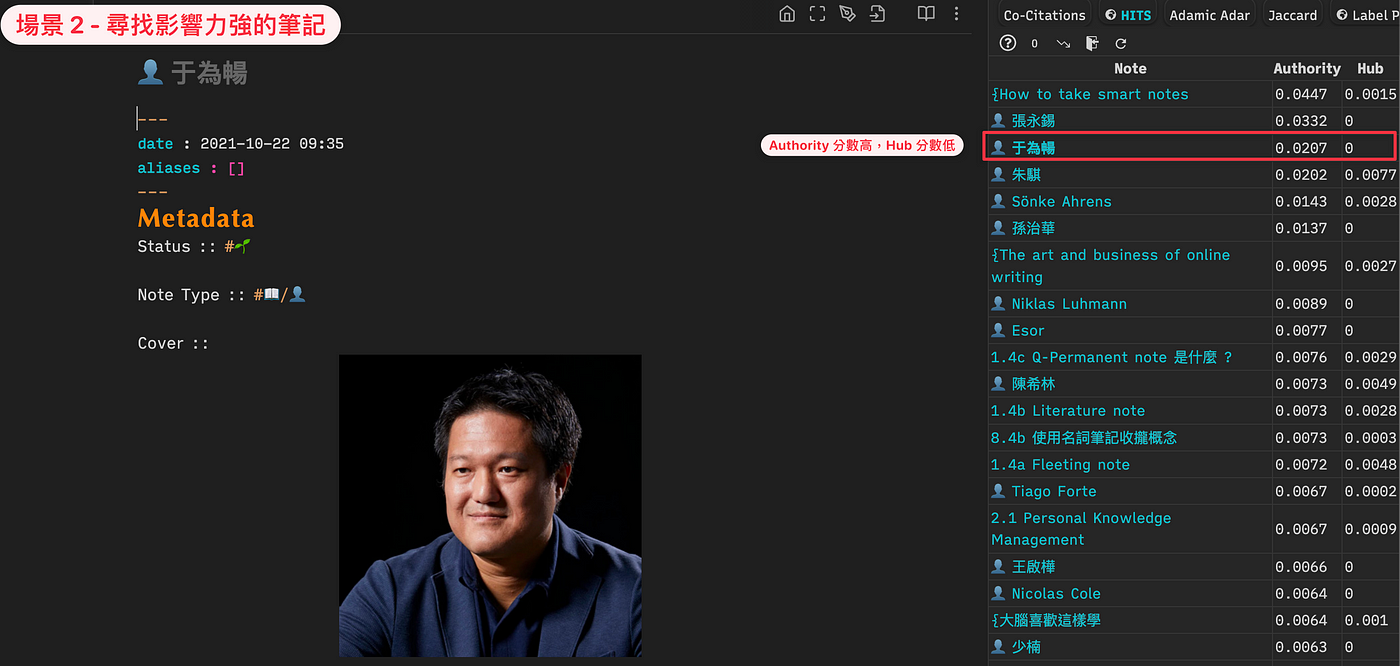
觀察 Authority 分數高、Hub 分數低的筆記。這些筆記不斷被我們連結到 (暗示重要性程度高),但是卻很少向外連結 (可能自己沒注意到),值得我們多放注意力維護。
我的應用
例如在我的 Obsidian 中,Authority 分數高、但Hub 分數低的是「于為暢老師」這則筆記。
這暗示:在其他筆記中我反覆提到 (連結)了「于為暢老師」,但卻沒有以「于為暢老師」為中心去寫相關的筆記內容。
因此我可以打開「反向連結 (backlink)」面板,參考有連結到「于為暢老師」的筆記,並將這些內容作為「于為暢老師」的人物介紹。
場景 2 適合用在「分配精力,維護高價值的筆記」。
備註:HITS (Hyperlink-Induced Topic Search) 原本是對網路搜尋引擎的搜尋結果計算排名的演算法。參考資料:https://bit.ly/3LntcgQ場景 3 : 尋找概念相近的筆記 (Cluster your notes)
Cluster (集群)指概念相近的筆記,會被歸類成一個群組。
Ensley Tan 拿了 3 種演算法進行測試 :
- Label propagation
- Louvain
- Clustering Co-efficient Label propagation 在結果上最準確 (Ensley Tan的人為判斷)。
這個演算法最終會以群組中的筆記數量做排列,點開群組即可看到被歸類在此群組的筆記。
我的應用
適合用在「以下至上(Bottom up) 挖掘寫作/研究主題」。
例如我的前 3 大集群是:
- The art and business of online writing (一本教網路寫作的書)
- T-2022_讀書會_高產出的本事
孫治華老師 點開群組 (例如孫治華老師),可以看到跟老師相關的所有筆記內容,包含:
- 孫治華老師
- 張瑋容 (講師訓學姊)
- 蕭景宇 (講師訓學姊)
- 講師訓的筆記
- 有提到講師訓或孫治華老師的每日日記
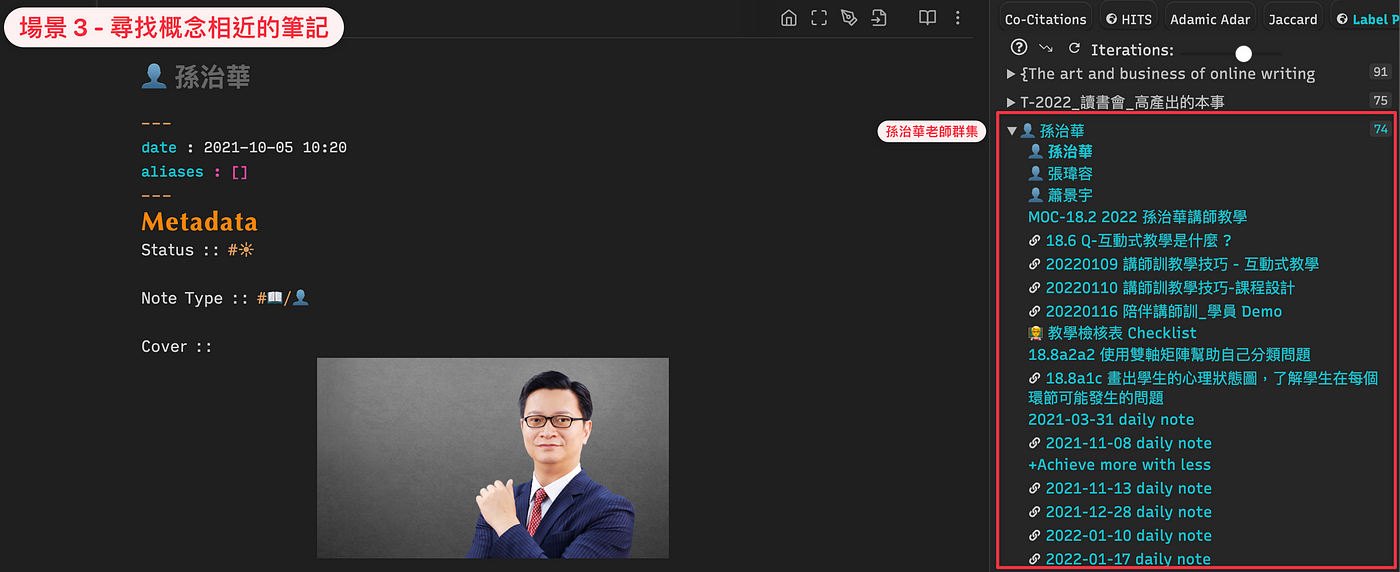
場景 3 適合用在「搜集寫作材料」。
總結
以上 3 種場景就是 Graph Analysis 的實際應用。
有使用 Obsidian 的朋友可以下載此款插件來玩看看,基本上有 50–100 則的筆記就可以看出效果了。
使用其他筆記軟體的朋友,可以先匯出成 .md 的格式並且用 Obsidian 開啟。由於主流的雙向鏈接筆記軟體 (Roam Rearch, Logseq, Heptabase, RemNote) 都支援 Wikilink (即 [[]] 格式來連結筆記),所以匯入到 Obsidian 中筆記連結都還會保留,Graph Analysis 就可以計算。
若不會下載與開啟插件,可參考下方的教學影片。
如果你對 Obsidian 有興趣、想系統性的學習這款筆記軟體,可以參考我的 Obsidian 學習包。
我會從基本的軟體操作開始教起,並且提到如何寫 Markdown 語法、Obsidian 的使用案例 (寫日記)...等。