作者:陳華夫
有兩、三千年歷史的圍棋,在中、日、韓三國創造了很多「圍棋天才」,但2016年「Google谷歌」人工智慧的「AlphpaGo」把他們都掃下了神壇(詳見拙文「人工智慧」的AlphaGo「圍棋革命」─圍棋的本質(1)),長期以來,人們崇拜這些「圍棋天才」(如吳清源大師等),神秘化他們的高超棋力,並且有數不清的圍棋經典書籍傳頌這些天才逸文佚事。
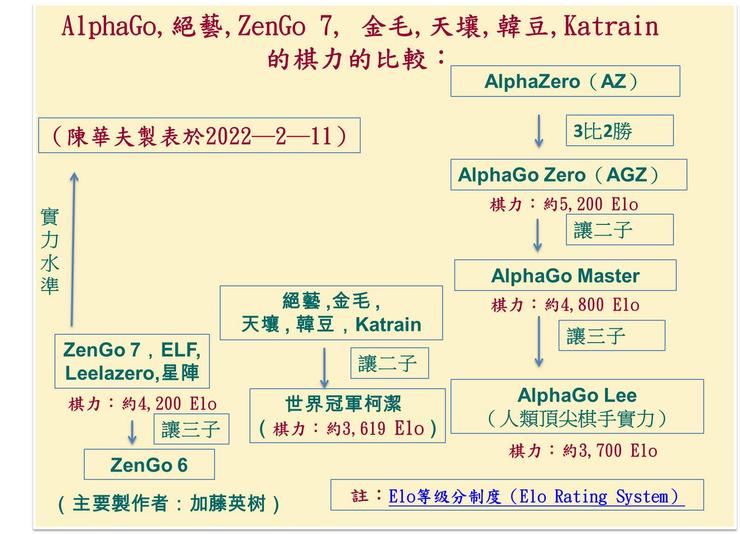
當「AlphpaGo」成了世界圍棋無敵霸主以後,谷歌也同樣搞神秘化的造神運動,不僅不公開其電腦程式碼供「人工智慧」研究,也不販售「AlphpaGo」電腦圍棋的單機版,方便一般棋手與之對弈。AlphaGo Zero與緊追在其後的絕藝、, 「ZenGo 7」, 金毛,天壤,韓豆, Katrain等電腦圍棋的棋力比較如下圖:(見最新圍棋AI實力排行!)

問題就在,雖然AlphaGo Zero是可以讓人類5子的超級圍棋天才,但不管是新的或舊的「圍棋天才」,都無助於增進人類圍棋的知識及棋力。現代社會學大師馬克斯.韋伯認為科學知識的進步必須建立在祛魅(Disenchantment)上。在圍棋這個領域來說,就是必須先揭掉(祛魅)「圍棋天才」的神秘面紗,人類圍棋知識與棋力才能進步。
本文研究圍棋的本質,祛魅AlphaGo Zero為何能讓人類五子的天才面紗?
首先,依照「賽局理論」(Game Theory)圍棋是資訊完全公開的賽局(「Perfect Information 賽局」,或「Markov 賽局」),與「麻將」及「撲克牌21點」都有不可知的暗牌不同,它們叫做「Imperfect Information賽局」,「賽局理論」Game Theory)的目的就是找到參與者的最佳博奕策略─「納許均衡」(Nash equilibrium)。
圍棋的規則是對弈雙方各自走一手,直到局終。持白棋的先走,但必須適當補償後走的「黑棋」6或7.5點,所以圍棋是雙方公平(Fair)的賽局。圍棋勝負的判定,是依雙方各自在19 x 19棋盤上,所圈定的地盤多少而定,多半點以上一方就算穫勝。
但是關鍵的問題來了,雖說圍棋是公平的賽局,但卻是「風險」(不確定性)的賽局;平均一局圍棋兩百多手,不到終局的任何一手,都令賽局「豬羊變色」,正所謂「一著棋錯,滿盤皆輸」。在如此的賽局,局部短期的「領先」,毫無意義,全局的大局觀「占優」才是關鍵。「AlphpaGo」能橫掃人類,就在其無人能及的全局的大局觀,這個問題要等下一篇文章來專論。(另請看拙文:「人工智慧」的AlphaGo「圍棋革命」─圍棋的本質(1))
本文先談另一個關鍵的問題:既然圍棋是各走一手的公平賽局,為何「AlphpaGo」棋力高出人類一大截─為何能讓人類五顆子呢?
長久以來,我們都用「天分」或「天才」來解釋棋力的高低。但是,當人們用「天才」來解釋吳清源大師的高超的「棋力」時,就等於間接承認人們對「棋力」本質知之甚少。當然就更無法解釋「AlphpaGo」的棋力為何能讓人類(包括吳清源大師)五子?
在谷歌刻意搞神秘的情況下,要解釋「AlphpaGo」高超「棋力」的真相,並不容易。我在拙文「人工智慧」的AlphaGo「圍棋革命」─圍棋的本質(1),從「人工智慧」的角度切入,回答「AlphpaGo」憑什麼卻能擊敗人類行之數千年的圍棋,但過多的專有名詞複雜化了真正的問題,真相反而不易解讀。
於是,再寫本文,化繁為簡的說明「AlphpaGo」高超的「棋力」來自以下三方面:
1)包括「AlphpaGo」在內的圍棋軟體,從第一手開始就在計算,也就是說,每一手都做「預估盤面」─即預估盤點對弈雙方所掌握的實空,再加上未來潛在可能成空的點數。這個預估,當盤面手數少時,很不精確,但隨著盤面手數越多,預估的準確性隨著提高,到了「收關」階段,這個「預估盤面」就變成了準確的「盤面清點」。
2)「AlphpaGo」的這個「預估盤面」用在模擬(試走)的局勢優劣的判斷,它每次使用至少3輪的「蒙特卡洛樹搜索」(Monte Carlo tree search)的模擬(試走),以選取「預估盤面」局勢最優的一手。而這種3輪的試走模擬的策略,實質意義上就是一種「悔棋」─試走若不滿意,就後悔的換另一種。換句話說,「AlphpaGo」每下一手都悔棋,但而人類卻「起手無回大丈夫」,連一手都不能回,這就違反圍棋的公平原則。深入的研究,就發現人類不能「悔棋」是「棋力」比「AlphpaGo」差一大截的一種原因。(請看拙文千夫所指的圍棋允許「回手」(悔棋)─圍棋本質(5))
3)人類「棋力」差一大截的主要原因,我在拙著「現代流圍棋:如何簡單對戰ALPHAGO-II (第一集)」裡,就提到人類與「AlphpaGo」對弈,通常早早在五、六十手就落入下風,終至落敗。這是因為包括「AlphpaGo」在內的圍棋軟體從第一手就「預估盤面」,並且每一手都3輪模擬試走的「算計」人類,但人類的智力卻無法從第一手起「預估盤面」,又不能會悔棋,在這種「一著錯而整盤輸」的高風險賽局中,被從不「無心」犯錯的「AlphpaGo」讓五子,是很合理的棋力估算。而且,我在媒體上也發現類職業9段被讓3子還是輸棋。(見圍棋教學|AI讓九段三子,結果九段被爆打,到底輸在哪裡呀?),。
綜上所述「AlphpaGo」的高超棋力是來自三點:(1)「預估盤面」;(2)每手3輪模擬試走的悔棋;(3)從第一手就開始「算計」對方。這些分析得來的圍棋知識,就為人類擊敗「AlphpaGo」點了盞明燈。
我因此建議人類的圍棋要因應AlphaGo的「圍棋革命」,而搖身一變為「現代流圍棋」,才能以擊敗「AlphpaGo」。
什麼是「現代流圍棋」?
就是改革傳統的圍棋的現代圍棋,採取下面的下面的4個改革:
1)凡是圍棋對弈,都允許使用「圍棋計算機」(詳見拙著「現代流圍棋:如何簡單對戰ALPHAGO-II (第一集)」第3頁),「圍棋計算機」是手機上的一種App(應用程式),可以照相19 x 19圍棋盤就能「預估盤面」,正如工學院大學生期末考,准許攜帶「工程計算機」一樣。以補足人類數學計算能力的不足。當然「棋力」的關鍵不在快速的「預估盤面」,但包括「AlphpaGo」在內的圍棋軟體,都有此初級算數的武器,人類也要擁有,才能在立足點上公平。使用「圍棋計算機」下圍棋是一種《人機共生》(Man-Computer Symbiosis), 也許稱為「智能增強」(Intelligence Augmentation 或Amplification,IA),這是在大數據,網絡系統,開放平台和嵌入式技術的時代裡,人工智慧的主要思想和潮流。
2)圍棋世界冠軍賽(及其它任何較低級別的圍棋賽)能允許棋手全局總共「回手」三次(請看拙文各級別的圍棋賽請允許三次回手(悔棋)─圍棋的本質(4)),前面說過,雖然「AlphpaGo」每一手都是實質意義上的「悔棋」,但在實際棋賽中,不能允許每一手都能悔棋,否則沒完沒了,耗時太多。於是我建議允許總共三次悔棋,則人類與「AlphpaGo」站在悔棋的基本公平點。
3)在圍棋這種「一著錯而整盤輸」的高風險賽局中,對弈必須從第一手起就要有好的貫穿全局策略,以「算計」對方。但傳統圍棋的「定石」、「佈局」、「手筋」、「中盤戰」、「收關」都是不同階段的局部策略,沒有貫穿全局,所以碰到「AlphpaGo」就不堪一擊。尤其,人類使用「定石」是兩面刃,它可以讓棋手在比賽時,不必浪費寶貴的時間思考,但也會讓棋手掉入路徑依賴理論(Path Dependence)所說的「路徑鎖定」,例如,「定石辭典」裡有許多星位對付來襲的「小馬步掛」的定式,但兩千年來的圍棋棋手都被「路徑鎖定」─人類一旦形成某種行為模式就很難改變而被鎖定在此種行為模式─在這些定石裡,以致於沒法發現開局之初的「小馬步掛」,是手壞棋。(詳細,請看拙文人類圍棋「定石」的致命缺陷─圍棋本質(6)、及革命性的、有效的痛擊來襲的「小馬步掛」─圍棋本質(7))
所以,我建議現代流圍棋要使用貫穿全局的「現代流5原則」:(見現代流5原則對戰職業九段,9P系列(5 /40)─陳華夫博士以「現代流4大法寶」持白中押勝ZenGo九段的經典的戰役)

及貫穿全局的現代流圍棋策略:(見科學方法學圍棋(18/40)─AlphaGo Zero 對付AlphaGo Master的持白「現代流5大手段」及(我的直播現代流5原則對戰職業九段,9P系列(6/40)─陳華夫博士以「埋伏餘味」吃掉ZenGo九段一塊─達標智源直播))

人類若能使用這種貫穿全局的現代流圍棋策略,才可以從第一手就「算計」對手,以扭轉被「AlphpaGo」讓五子的劣勢。
4)我建議屏棄學習「定石」的圍棋傳統,因為「定石辭典」裡有許多星位對付來襲的「小馬步掛」的定式,但兩千年來的圍棋棋手都被「路徑鎖定」─人類一旦形成某種行為模式就很難改變而被鎖定在此種行為模式─在這些定石裡,以致於沒法發現開局之初的「小馬步掛」,是手壞棋。(見拙文人類圍棋「定石」的致命缺陷─圍棋本質(6)、及革命性的、有效的痛擊來襲的「小馬步掛」─圍棋本質(7))
所以,我建議「現代流的圍棋」的學習是採用自學,其關鍵是在圍棋學習之初,要「有意識」的掌握現代流圍棋五原則,而這5原則扮演兩個角色:一是在作為整個學習的指導方針,而作為「刻意練習」的學習目標。發現學習的瓶頸及克服之道,另一是做為學習結果的評量圭臬(準則)。(詳細請看拙文現代流5原則─圍棋的本質(3) )
自從2016年電腦(AI)圍棋橫掃人類職業世界冠軍以來,媒體也報導人類職業9段被人工智慧電腦圍棋讓3子還是輸棋,(見圍棋教學|AI讓九段三子,結果九段被爆打,到底輸在哪裡呀?),然而,自學的AlphaGo Zero仍是基於深度學習,其演算法是「由下而上」的規則性(rule-based),而人類的圍棋智慧卻是「由上而下」的理論性(theory based),也就是說,人類智慧是一種理論的洞識,而理論及推理是高過規則一個檔次(見人類才不會被AI取代!《大腦如何精準學習》揭大腦6大優點:目前的人工智慧永遠學不來)。所以人類智慧高人工智慧一個檔次。而我就成功的抽取出圍棋的理論:現代流圍棋五原則,並以它奮戰「ZenGo 九段」與「Katrain 9段」。在經過4、5年,我現在已能有系統的持白大勝「ZenGo 九段」與「Katrain 9段」,證明了人類智慧還是有機會戰勝人工智慧的電腦圍棋軟體。(請看拙文如何正確的戰勝AI電腦圍棋「Katrain 9段」?─圍棋本質(9)、及youtube視頻現代流5原則對戰職業九段,9P系列(60─100)─ 陳華夫持白狂勝「Katrain 9段」144目半)
請看「陳華夫專欄」─圍棋的本質─系列文章:
(
「人工智慧」的AlphaGo「圍棋革命」─圍棋的本質(1)
現代流圍棋─圍棋的本質(2)
現代流5原則─圍棋的本質(3)
各級別的圍棋賽請允許三次回手(悔棋)─圍棋的本質(4)
千夫所指的圍棋允許「回手」(悔棋)─圍棋本質(5)
人類圍棋「定石」的致命缺陷─圍棋本質(6)
革命性的、有效的痛擊來襲的「小馬步掛」─圍棋本質(7)
「ZenGo 7」AI電腦圍棋9段被我中押敗的人生感悟─圍棋本質(8)
如何正確的戰勝AI電腦圍棋「Katrain 9段」?─圍棋本質(9)
)
Brute computing force alone can't solve the world's problems.
J.C.R. Licklider-約瑟夫·利克萊德-的《人機共生》(Man-Computer Symbiosis)
請看我的直播現代流5原則對戰職業九段,9P系列(6/40)─陳華夫博士以「埋伏餘味」吃掉ZenGo九段一塊─達標智源直播