前言
從上一篇的「產品思維」中,我們發現要設計一款好的產品,不單單只是「功能面」這麼簡單,仍然需要從「人性」心理層面去思考,並突顯最重要的「資訊」給用戶,每一個環節都非常的精彩。
當我們開發完產品之後,一旦上市,就會有不斷的「建議」、「回饋」、「好評或負評」飛奔而來,什麼意見是有幫助的呢?怎麼的決策是好的呢?
而且會抱怨的客戶不見得是代表大部份用戶的想法,這時候「數據思維」就是很重要的一個基準點,它幫助我們更客觀的決策,做出更有利的判斷…這一篇我們來介紹第二個思維:「數據思維」。
在這個篇幅裡面,作者提到了「幸存者偏差」、「p值」、「標準差」、「風險對沖」、「偽陽性」、「偽陰性」…等等非常多的觀點,都是我們在學習數據使用時,必須要知道的觀點;
在這邊我們就挑一個我覺得最常用到的「A/B 測試」來做分享。
1. 客戶到底要什麼?
我們在開發產品的時候的時候,經常會收到用戶各種各樣的意見、建議,甚至是抱怨。
這時候設計師就會糾結,應該用的字級多大,放幾個按鈕,按鈕用什麼顏色等。
但是,用戶就跟女朋友一樣,難以捉摸。無論你怎樣糾結,時限一到,還是要做出決斷。
這時候我們要怎麼做出決斷呢?
最後怎樣做出決斷?當然不是靠產品經理憑主觀臆斷,也不是靠工程師和設計師談判,更不是靠高層們扔骰子(比大小)。其實,矽谷的幾乎所有企業,都在使用一套科學的數據統計方法,來幫助團隊做出最優化的決策。
簡而言之,總結起來就是一個公式:p < 0.05。
案例重現
我們都知道,想要對兩個方案做出選擇,最好的方法就是做實驗。在互聯網行業,這個實驗統稱為A/B測試(A/B Test)。也就是找出一部分實驗用戶,例如10萬人,給其中一半人使用A方案,而對另一半的5萬人,使用B方案。
看看下面這個案例。
透過第一章,你現在應該已經知道了,「顏色」對於用戶的行為有著顯著的影響。於是,你們的產品團隊現在想試試,把按鈕的顏色從綠色變成紅色,是不是有更多的人點擊。於是你就簡單地設計了下面這個實驗。對於所有進入這個頁面的用戶,你讓一半人看到綠色按鈕,而另外一半人看到的,則是紅色。
實驗就這樣跑了幾天,你得到了如下的數據統計結果。
A組,綠色:100 個人看到了這個按鈕,可是卻沒人點擊,點擊量為 0。
B組,紅色:同樣有 100 個人看到,居然有 50 個人點擊。
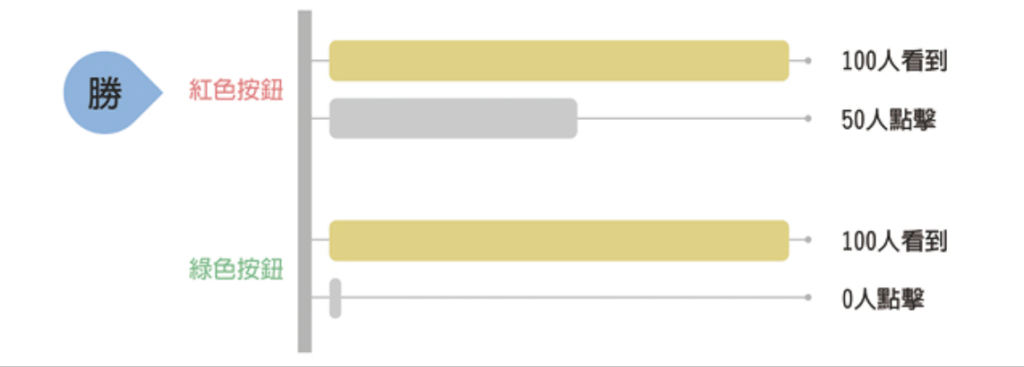
如果是這樣完美的數據,我們容易得出結論 —— 紅色完勝,畢竟綠色組成績為 0。之後,你的產品團隊就高興地上線了紅色按鈕方案。
但現實是,我們往往得不到這麼完美的一面倒的數據,而且我們如果同時關注兩個以上的用戶指標,結論還很有可能相互矛盾,在這個時候我們應該怎麼辦呢?
再來看一個例子。
還是應用了第一章的內容,你現在應該知道,手機的「推播通知」對挽留用戶很重要吧。發一個推播,用戶說不定就會點開好久不用的App了。所以,你的團隊又有了一個想法,想和文案部門聯合,一起試試「個性化通知內容」是不是更有效。
於是,你們設計了下面這個實驗。依然是把用戶隨機分成兩組,然後你們分別給兩組人發送不一樣的推播通知。
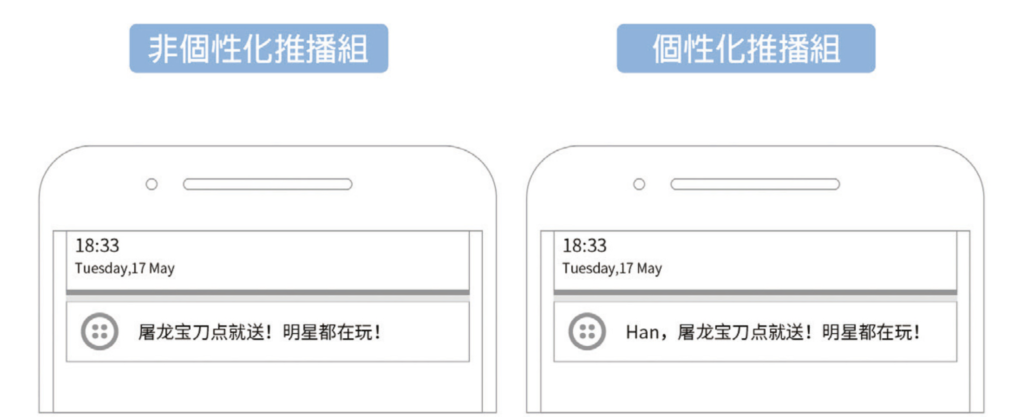
第一組收到的是非個性的「屠龍寶刀點就送!明星都在玩!」
第二組則有一點點個性化,在開頭加上了用戶的名字,「(用戶姓名),屠龍寶刀點就送!明星都在玩!」
通知發送一天之後,得到了如下圖所示的實驗結果。
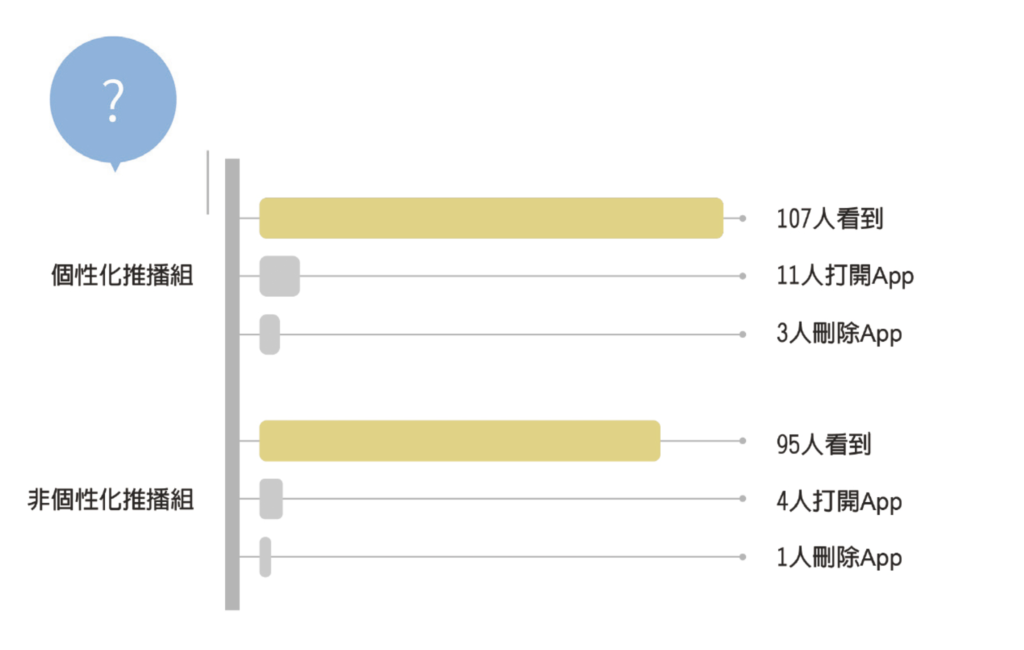
- 第一組,有 95 個用戶接到了推播;收到通知 24 小時內,有四個人打開了 App,但是有一個人刪除了App ,可能是因為收到推播太多,太煩了。
- 第二組,有 107 個用戶接到了推播;收到通知 24 小時內,有 11 個人打開了 App,但是有三個人刪除了App。
注意,對於上面的數據,我們並不區分用戶是直接點擊推播通知打開的App,還是看到推播後,過了一會兒,用戶自主找到App圖示打開的。
結果擺在面前,就很尷尬了,似乎是喜憂參半的悖論。如果只看讀取率,那可能是第二組更好,但是第二組的刪除率又上升了。
到底應該怎樣抉擇?還好我們有統計學。
P值是什麼?
這個事情,要是交給統計學家,會怎麼處理呢?他們會計算 p值(p-Value)。
P來自英文單詞probability(機率,又譯「或然率」)的首字母。嚴格來講,p值雖然不能直接代表機率,但是可以相對表示出實驗組方案沒有任何用處的可能性。
對於推播行動通知的實驗,我們可以先來以只計算讀取率為例。第一組用戶的讀取率,很容易計算,那就是4/95=4.21%。現在問題的關鍵是,我們需要知道,第二組這個打開人數的增長,到底是一個「恰好」出現的偶然結果,還是真的因為「個性化的通知內容」很有效而帶來的讀取率提高呢?因為,用戶即使收到了通知,其實也不一定會注意到。即使注意到了推播,可能也沒有看推播的內容。而且,用戶還有可能完全沒有看任何推播通知,也會自己打開App。
在統計方法上,我們會先來一個「虛無假設」(null hypothesis):也就是假設「個性化」通知根本沒啥用,於是我們有:如果「虛無假設」成立,那麼第二組的真實讀取率,就應該維持4.21%不變,和第一組一樣。
下面,我們就要對這個假設是否成立進行驗證。
那麼,按照4.21%這個讀取率,第二組出現11個人打開App的機率是多少呢?這是一道高考難度的數學題,答案就是:
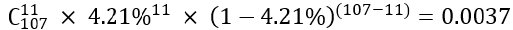
這個值,就是p值(此處進行了合理的簡化),p=0.0037。它代表了「個性化通知」沒有任何用處的機率僅為0.0037。
其實,p值就表示了實驗結果純屬巧合的可能性。所以,p值當然是愈低愈好了;更低的p值,會表明實驗組更「可能」有效(注意,不是更有效)。那麼多低是低呢?標準是什麼?在矽谷業界和學術界,目前普遍採用的p值標準線是0.05。
也就是說,如果 p < 0.05, 就代表數據有「統計顯著」(statistically significant,或譯「顯著性差異」),通常簡稱Stat-Sig。如果具有顯著性,那麼實驗結果是有意義的,可以接受(accept),虛無假設將被駁回(reject)。以上驗證過程,在統計學上稱為「假設檢驗」。
這時我們再看,讀取率的p值小於0.05,那麼就可以說「個性化」通知對於促進用戶讀取App有效。
再來看看兩組刪除率的p值,經過計算,我們得出p=0.1795,大於0.05;也就是說,刪除率上升純屬偶然。
這下好啦,產品決策清晰了。
我們現在可以得出結論,相比原來的非個性化推播,我們發現個性化的推播讀取率有顯著性提升,而刪除率則沒有顯著的統計學差異。
於是,歡快地決定上線「個性化推播」功能!
實驗工具
可以說,矽谷的互聯網產品,就是由實驗驅動著的。
無論是設計師提出的一個小小的UI變動,還是推薦引擎工程師對演算法模型的升級,抑或宣傳和公關部門的文案標題改動,大都由實驗驅動。在很多大型App裡,例如YouTube、Twitter等,往往同時運行著超級多的實驗,每個人使用的App功能甚至都不盡相同。
為了提高效率,矽谷各大企業紛紛開發了專門的實驗工具和分析系統,讓大家快速使用。
例如Google旗下Analytics產品的內容實驗(Content Experiments)工具,它可以幫助用戶,快速地通過UI創建各類實驗,添加各項實驗組。還能在實驗運行時,利用多臂吃角子老虎機(Multi-armed bandit)演算法,自動調整並分配各個實驗組的流量比例,以加快實驗速度。實驗結束後,還會自動生成智慧化報表。
Uber則在公司內部推出了實驗平台XP。它不僅是實驗和分析工具,還幫助Uber安全上線和部署新功能,即時觀測數據。
Airbnb內部則使用實驗框架ERF(Experimentation Reporting Framework)工具。ERF的互動設計非常好,可以批量顯示正在運行的所有實驗,還提供了美觀的報表系統,p值一目瞭然,並用不同顏色標注實驗結果,清晰快速。

Netflix的跨平台實驗工具則是ABlaze。它有著跨電腦和手機多平台的優良特性。借助ABlaze,Netflix得以快速疊代產品,以便滿足全球超過1億用戶的觀影需求。尤其是打開App後90秒內的黃金時間,根據統計,如果在這個時間範圍內用戶找不到自己想看的影片,他們就會關閉整個App。
此外,還有很多公開的免費在線工具,如AB Testguide,就可以幫助用戶快速地計算p值。
更複雜的實驗方法
當然,A/B測試僅僅是實驗中最簡單的情況,在實際應用中,還會有非常複雜的情況。下面舉出兩個典型的例子。
第一個例子是社交產品。
在進行涉及兩個用戶以上的社交功能測試時,為保證實驗品質,我們需要找到兩組彼此沒有任何關聯的用戶群,否則實驗就可能被「汙染」。例如,朋友圈要測試一個新功能 —— 朋友圈搶紅包。這裡就涉及紅包發送者和搶紅包的人兩種角色。
這時,我們就不能簡單地使用隨機演算法把用戶分成兩組了,因為發紅包的人和搶紅包的人,有可能在兩個不同的測試組,這樣功能就是不完整的。為了保證控制組的人永遠不會看到這個功能,我們可以按照地區挑選。例如只有本地好友的北京用戶為一組,而把只有本地好友的廣州用戶設為一組。有時候,我們還要挑選一些偏遠地區的用戶,如海島上的居民,因為他們對外的社會關係相對更少。
另外一個典型的例子是廣告產品。
在做電子廣告測試的時候,我們也不能簡單地把用戶隨機分成兩組。因為每一個用戶的「價值」不同。
例如,兩個用戶同樣在使用朋友圈,其中一位用戶因為歷史消費很多,系統認定這是有高消費能力的用戶。這時各種奢侈品、車、房地產等廣告都想爭奪對他的廣告顯示機會。因為朋友圈廣告對每一個用戶每天看廣告的數量有一個上限,這樣這一條廣告就很有可能競價到很高的價格。相比另外一個「低價值」用戶,廣告主則要花費更多的錢來獲得這一次點擊。
這時,為了衡量廣告效果,不需要控制AB兩組用戶的數量絕對相等,我們應該控制的是兩組消耗掉的廣告費用相等。例如,你花費了100元,給50個「高價值」用戶看了名車廣告,有10個人完成了購買。而另一組,你花費100元,給1000個「低價值」用戶同樣看了這個名車廣告,只有一個人最終購買。這樣你就能衡量廣告效果的不同了。
更進一步
對於p值小於0.05,你可能會有一個疑問。為什麼這些矽谷企業偏偏都選0.05這個數字呢?答案就是:隨便選的。
嗯,其實這個真的就只是一個約定俗成的數值而已。這還要歸功於1920年代,一位英國人羅納德.費雪(Ronald Fisher)。他在研究肥料對農作物影響時提出了這個值,並向學術界推廣。到現在,0.05已經成為很多場合下的通用標準。
當然,很多產品為了更加可靠,也會使用更低的 p 值,例如 0.01。
可能被「汙染」。例如,朋友圈要測試一個新功能——朋友圈搶紅包。這裡就涉及紅包發送者和搶紅包的人兩種角色。
這時,我們就不能簡單地使用隨機演算法把用戶分成兩組了,因為發紅包的人和搶紅包的人,有可能在兩個不同的測試組,這樣功能就是不完整的。為了保證控制組的人永遠不會看到這個功能,我們可以按照地區挑選。例如只有本地好友的北京用戶為一組,而把只有本地好友的廣州用戶設為一組。有時候,我們還要挑選一些偏遠地區的用戶,如海島上的居民,因為他們對外的社會關係相對更少。
小結
在這個世界,我們都知道「數據」對我們來說有多重要,所以不管怎麼,我們都會努力去蒐集資料;然而蒐集完資料之後,便面臨一個大問題:〝這些數據該怎麼使用〞?或者是說,這些數據怎麼幫助我們做出更好的決策。
從一開始的「篩選用戶」,根據我們的需求進行用戶分組並進行 「AB 測試」實驗,取得用戶相關數據之後,我們可以透過 P 值計算,取得 「p<0.05」的有效假設,進而進行我們的決策。
在這一篇當中,我們理解了「A/B 測試」、「p值」、「統計顯著性」、「假設檢驗」等觀念,知道這些思維,便可以更進一步去處理數據,得到我們想要的資訊,更好的做出判斷。